 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Benign Inputs Lead to Severe Harms: Eliciting Unsafe Unintended Behaviors of Computer-Use Agents
Feb 09, 2026Although computer-use agents (CUAs) hold significant potential to automate increasingly complex OS workflows, they can demonstrate unsafe unintended behaviors that deviate from expected outcomes even under benign input contexts. However, exploration of this risk remains largely anecdotal, lacking concrete characterization and automated methods to proactively surface long-tail unintended behaviors under realistic CUA scenarios. To fill this gap, we introduce the first conceptual and methodological framework for unintended CUA behaviors, by defining their key characteristics, automatically eliciting them, and analyzing how they arise from benign inputs. We propose AutoElicit: an agentic framework that iteratively perturbs benign instructions using CUA execution feedback, and elicits severe harms while keeping perturbations realistic and benign. Using AutoElicit, we surface hundreds of harmful unintended behaviors from state-of-the-art CUAs such as Claude 4.5 Haiku and Opus. We further evaluate the transferability of human-verified successful perturbations, identifying persistent susceptibility to unintended behaviors across various other frontier CUAs. This work establishes a foundation for systematically analyzing unintended behaviors in realistic computer-use settings.
Beyond Length: Context-Aware Expansion and Independence as Developmentally Sensitive Evaluation in Child Utterances
Feb 05, 2026Evaluating the quality of children's utterances in adult-child dialogue remains challenging due to insufficient context-sensitive metrics. Common proxies such as Mean Length of Utterance (MLU), lexical diversity (vocd-D), and readability indices (Flesch-Kincaid Grade Level, Gunning Fog Index) are dominated by length and ignore conversational context, missing aspects of response quality such as reasoning depth, topic maintenance, and discourse planning. We introduce an LLM-as-a-judge framework that first classifies the Previous Adult Utterance Type and then scores the child's response along two axes: Expansion (contextual elaboration and inferential depth) and Independence (the child's contribution to advancing the discourse). These axes reflect fundamental dimensions in child language development, where Expansion captures elaboration, clause combining, and causal and contrastive connectives. Independence captures initiative, topic control, decreasing reliance on adult scaffolding through growing self-regulation, and audience design. We establish developmental validity by showing age-related patterns and demonstrate predictive value by improving age estimation over common baselines. We further confirm semantic sensitivity by detecting differences tied to discourse relations. Our metrics align with human judgments, enabling large-scale evaluation. This shifts child utterance assessment from simply measuring length to evaluating how meaningfully the child's speech contributes to and advances the conversation within its context.
VISTA Score: Verification In Sequential Turn-based Assessment
Oct 30, 2025Hallucination--defined here as generating statements unsupported or contradicted by available evidence or conversational context--remains a major obstacle to deploying conversational AI systems in settings that demand factual reliability. Existing metrics either evaluate isolated responses or treat unverifiable content as errors, limiting their use for multi-turn dialogue. We introduce VISTA (Verification In Sequential Turn-based Assessment), a framework for evaluating conversational factuality through claim-level verification and sequential consistency tracking. VISTA decomposes each assistant turn into atomic factual claims, verifies them against trusted sources and dialogue history, and categorizes unverifiable statements (subjective, contradicted, lacking evidence, or abstaining). Across eight large language models and four dialogue factuality benchmarks (AIS, BEGIN, FAITHDIAL, and FADE), VISTA substantially improves hallucination detection over FACTSCORE and LLM-as-Judge baselines. Human evaluation confirms that VISTA's decomposition improves annotator agreement and reveals inconsistencies in existing benchmarks. By modeling factuality as a dynamic property of conversation, VISTA offers a more transparent, human-aligned measure of truthfulness in dialogue systems.
Improving Neural Diarization through Speaker Attribute Attractors and Local Dependency Modeling
Jun 05, 2025In recent years, end-to-end approaches have made notable progress in addressing the challenge of speaker diarization, which involves segmenting and identifying speakers in multi-talker recordings. One such approach, Encoder-Decoder Attractors (EDA), has been proposed to handle variable speaker counts as well as better guide the network during training. In this study, we extend the attractor paradigm by moving beyond direct speaker modeling and instead focus on representing more detailed `speaker attributes' through a multi-stage process of intermediate representations. Additionally, we enhance the architecture by replacing transformers with conformers, a convolution-augmented transformer, to model local dependencies. Experiments demonstrate improved diarization performance on the CALLHOME dataset.
RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Environments
May 28, 2025Computer-use agents (CUAs) promise to automate complex tasks across operating systems (OS) and the web, but remain vulnerable to indirect prompt injection. Current evaluations of this threat either lack support realistic but controlled environments or ignore hybrid web-OS attack scenarios involving both interfaces. To address this, we propose RedTeamCUA, an adversarial testing framework featuring a novel hybrid sandbox that integrates a VM-based OS environment with Docker-based web platforms. Our sandbox supports key features tailored for red teaming, such as flexible adversarial scenario configuration, and a setting that decouples adversarial evaluation from navigational limitations of CUAs by initializing tests directly at the point of an adversarial injection. Using RedTeamCUA, we develop RTC-Bench, a comprehensive benchmark with 864 examples that investigate realistic, hybrid web-OS attack scenarios and fundamental security vulnerabilities. Benchmarking current frontier CUAs identifies significant vulnerabilities: Claude 3.7 Sonnet | CUA demonstrates an ASR of 42.9%, while Operator, the most secure CUA evaluated, still exhibits an ASR of 7.6%. Notably, CUAs often attempt to execute adversarial tasks with an Attempt Rate as high as 92.5%, although failing to complete them due to capability limitations. Nevertheless, we observe concerning ASRs of up to 50% in realistic end-to-end settings, with the recently released frontier Claude 4 Opus | CUA showing an alarming ASR of 48%, demonstrating that indirect prompt injection presents tangible risks for even advanced CUAs despite their capabilities and safeguards. Overall, RedTeamCUA provides an essential framework for advancing realistic, controlled, and systematic analysis of CUA vulnerabilities, highlighting the urgent need for robust defenses to indirect prompt injection prior to real-world deployment.
A Non-autoregressive Model for Joint STT and TTS
Jan 15, 2025In this paper, we take a step towards jointly modeling automatic speech recognition (STT) and speech synthesis (TTS) in a fully non-autoregressive way. We develop a novel multimodal framework capable of handling the speech and text modalities as input either individually or together. The proposed model can also be trained with unpaired speech or text data owing to its multimodal nature. We further propose an iterative refinement strategy to improve the STT and TTS performance of our model such that the partial hypothesis at the output can be fed back to the input of our model, thus iteratively improving both STT and TTS predictions. We show that our joint model can effectively perform both STT and TTS tasks, outperforming the STT-specific baseline in all tasks and performing competitively with the TTS-specific baseline across a wide range of evaluation metrics.
Improving Transducer-Based Spoken Language Understanding with Self-Conditioned CTC and Knowledge Transfer
Jan 03, 2025In this paper, we propose to improve end-to-end (E2E) spoken language understand (SLU) in an RNN transducer model (RNN-T) by incorporating a joint self-conditioned CTC automatic speech recognition (ASR) objective. Our proposed model is akin to an E2E differentiable cascaded model which performs ASR and SLU sequentially and we ensure that the SLU task is conditioned on the ASR task by having CTC self conditioning. This novel joint modeling of ASR and SLU improves SLU performance significantly over just using SLU optimization. We further improve the performance by aligning the acoustic embeddings of this model with the semantically richer BERT model. Our proposed knowledge transfer strategy makes use of a bag-of-entity prediction layer on the aligned embeddings and the output of this is used to condition the RNN-T based SLU decoding. These techniques show significant improvement over several strong baselines and can perform at par with large models like Whisper with significantly fewer parameters.
Improving Speech Recognition Error Prediction for Modern and Off-the-shelf Speech Recognizers
Aug 21, 2024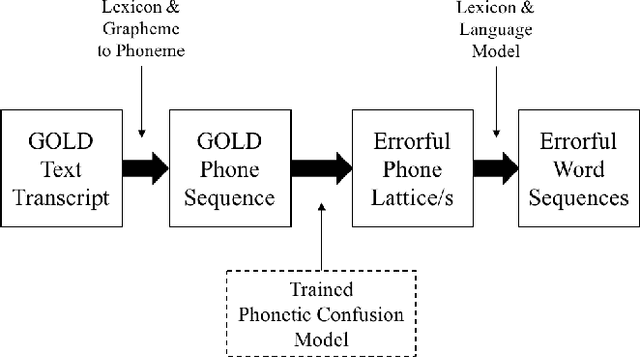
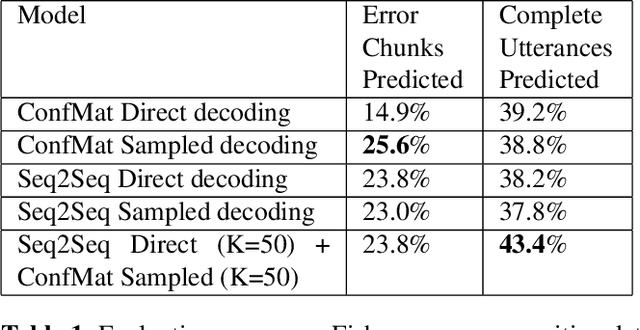
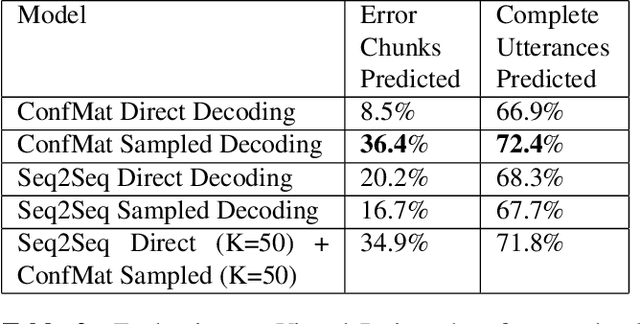
Modeling the errors of a speech recognizer can help simulate errorful recognized speech data from plain text, which has proven useful for tasks like discriminative language modeling, improving robustness of NLP systems, where limited or even no audio data is available at train time. Previous work typically considered replicating behavior of GMM-HMM based systems, but the behavior of more modern posterior-based neural network acoustic models is not the same and requires adjustments to the error prediction model. In this work, we extend a prior phonetic confusion based model for predicting speech recognition errors in two ways: first, we introduce a sampling-based paradigm that better simulates the behavior of a posterior-based acoustic model. Second, we investigate replacing the confusion matrix with a sequence-to-sequence model in order to introduce context dependency into the prediction. We evaluate the error predictors in two ways: first by predicting the errors made by a Switchboard ASR system on unseen data (Fisher), and then using that same predictor to estimate the behavior of an unrelated cloud-based ASR system on a novel task. Sampling greatly improves predictive accuracy within a 100-guess paradigm, while the sequence model performs similarly to the confusion matrix.
A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
Feb 18, 2024



Counter narratives - informed responses to hate speech contexts designed to refute hateful claims and de-escalate encounters - have emerged as an effective hate speech intervention strategy. While previous work has proposed automatic counter narrative generation methods to aid manual interventions, the evaluation of these approaches remains underdeveloped. Previous automatic metrics for counter narrative evaluation lack alignment with human judgment as they rely on superficial reference comparisons instead of incorporating key aspects of counter narrative quality as evaluation criteria. To address prior evaluation limitations, we propose a novel evaluation framework prompting LLMs to provide scores and feedback for generated counter narrative candidates using 5 defined aspects derived from guidelines from counter narrative specialized NGOs. We found that LLM evaluators achieve strong alignment to human-annotated scores and feedback and outperform alternative metrics, indicating their potential as multi-aspect, reference-free and interpretable evaluators for counter narrative evaluation.
End-to-End real time tracking of children's reading with pointer network
Oct 17, 2023In this work, we explore how a real time reading tracker can be built efficiently for children's voices. While previously proposed reading trackers focused on ASR-based cascaded approaches, we propose a fully end-to-end model making it less prone to lags in voice tracking. We employ a pointer network that directly learns to predict positions in the ground truth text conditioned on the streaming speech. To train this pointer network, we generate ground truth training signals by using forced alignment between the read speech and the text being read on the training set. Exploring different forced alignment models, we find a neural attention based model is at least as close in alignment accuracy to the Montreal Forced Aligner, but surprisingly is a better training signal for the pointer network. Our results are reported on one adult speech data (TIMIT) and two children's speech datasets (CMU Kids and Reading Races). Our best model can accurately track adult speech with 87.8% accuracy and the much harder and disfluent children's speech with 77.1% accuracy on CMU Kids data and a 65.3% accuracy on the Reading Races dataset.