 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Recognition Error Prediction for Modern and Off-the-shelf Speech Recognizers
Aug 21, 2024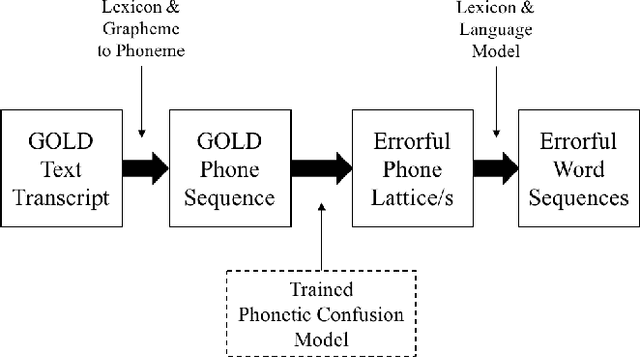
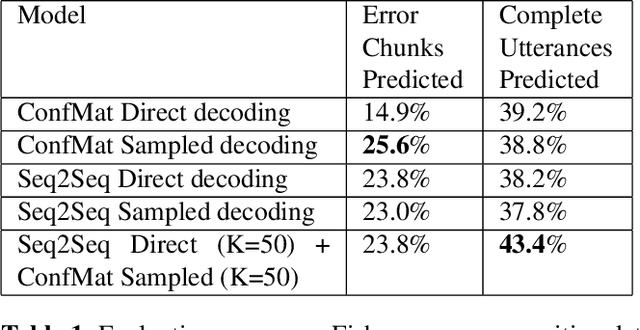
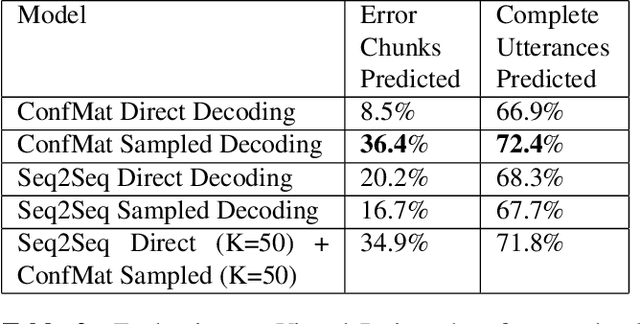
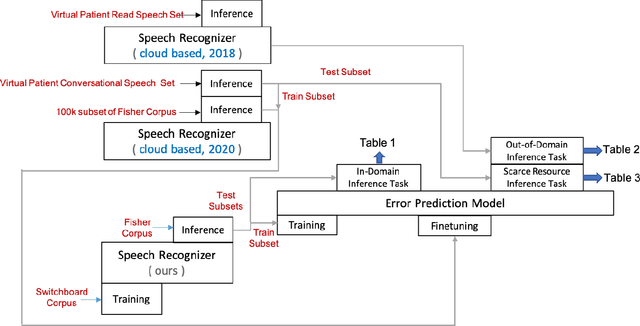
Modeling the errors of a speech recognizer can help simulate errorful recognized speech data from plain text, which has proven useful for tasks like discriminative language modeling, improving robustness of NLP systems, where limited or even no audio data is available at train time. Previous work typically considered replicating behavior of GMM-HMM based systems, but the behavior of more modern posterior-based neural network acoustic models is not the same and requires adjustments to the error prediction model. In this work, we extend a prior phonetic confusion based model for predicting speech recognition errors in two ways: first, we introduce a sampling-based paradigm that better simulates the behavior of a posterior-based acoustic model. Second, we investigate replacing the confusion matrix with a sequence-to-sequence model in order to introduce context dependency into the prediction. We evaluate the error predictors in two ways: first by predicting the errors made by a Switchboard ASR system on unseen data (Fisher), and then using that same predictor to estimate the behavior of an unrelated cloud-based ASR system on a novel task. Sampling greatly improves predictive accuracy within a 100-guess paradigm, while the sequence model performs similarly to the confusion matrix.
Ultra-lightweight Neural Differential DSP Vocoder For High Quality Speech Synthesis
Jan 19, 2024



Neural vocoders model the raw audio waveform and synthesize high-quality audio, but even the highly efficient ones, like MB-MelGAN and LPCNet, fail to run real-time on a low-end device like a smartglass. A pure digital signal processing (DSP) based vocoder can be implemented via lightweight fast Fourier transforms (FFT), and therefore, is a magnitude faster than any neural vocoder. A DSP vocoder often gets a lower audio quality due to consuming over-smoothed acoustic model predictions of approximate representations for the vocal tract. In this paper, we propose an ultra-lightweight differential DSP (DDSP) vocoder that uses a jointly optimized acoustic model with a DSP vocoder, and learns without an extracted spectral feature for the vocal tract. The model achieves audio quality comparable to neural vocoders with a high average MOS of 4.36 while being efficient as a DSP vocoder. Our C++ implementation, without any hardware-specific optimization, is at 15 MFLOPS, surpasses MB-MelGAN by 340 times in terms of FLOPS, and achieves a vocoder-only RTF of 0.003 and overall RTF of 0.044 while running single-threaded on a 2GHz Intel Xeon CPU.
Synthetic Cross-accent Data Augmentation for Automatic Speech Recognition
Mar 01, 2023


The awareness for biased ASR datasets or models has increased notably in recent years. Even for English, despite a vast amount of available training data, systems perform worse for non-native speakers. In this work, we improve an accent-conversion model (ACM) which transforms native US-English speech into accented pronunciation. We include phonetic knowledge in the ACM training to provide accurate feedback about how well certain pronunciation patterns were recovered in the synthesized waveform. Furthermore, we investigate the feasibility of learned accent representations instead of static embeddings. Generated data was then used to train two state-of-the-art ASR systems. We evaluated our approach on native and non-native English datasets and found that synthetically accented data helped the ASR to better understand speech from seen accents. This observation did not translate to unseen accents, and it was not observed for a model that had been pre-trained exclusively with native speech.
Voice-preserving Zero-shot Multiple Accent Conversion
Nov 23, 2022Most people who have tried to learn a foreign language would have experienced difficulties understanding or speaking with a native speaker's accent. For native speakers, understanding or speaking a new accent is likewise a difficult task. An accent conversion system that changes a speaker's accent but preserves that speaker's voice identity, such as timbre and pitch, has the potential for a range of applications, such as communication, language learning, and entertainment. Existing accent conversion models tend to change the speaker identity and accent at the same time. Here, we use adversarial learning to disentangle accent dependent features while retaining other acoustic characteristics. What sets our work apart from existing accent conversion models is the capability to convert an unseen speaker's utterance to multiple accents while preserving its original voice identity. Subjective evaluations show that our model generates audio that sound closer to the target accent and like the original speaker.
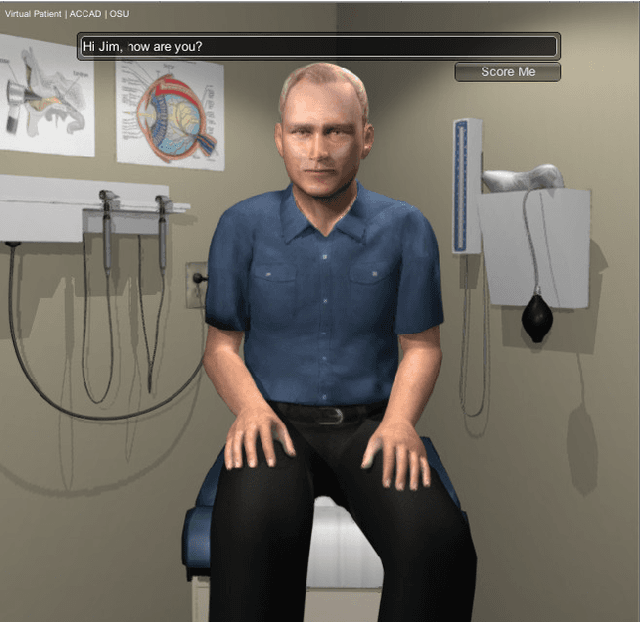
Building an ASR Error Robust Spoken Virtual Patient System in a Highly Class-Imbalanced Scenario Without Speech Data
Apr 11, 2022

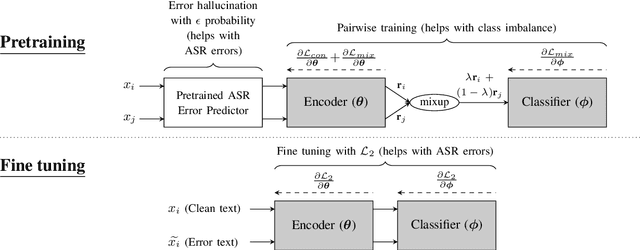

A Virtual Patient (VP) is a powerful tool for training medical students to take patient histories, where responding to a diverse set of spoken questions is essential to simulate natural conversations with a student. The performance of such a Spoken Language Understanding system (SLU) can be adversely affected by both the presence of Automatic Speech Recognition (ASR) errors in the test data and a high degree of class imbalance in the SLU training data. While these two issues have been addressed separately in prior work, we develop a novel two-step training methodology that tackles both these issues effectively in a single dialog agent. As it is difficult to collect spoken data from users without a functioning SLU system, our method does not rely on spoken data for training, rather we use an ASR error predictor to "speechify" the text data. Our method shows significant improvements over strong baselines on the VP intent classification task at various word error rate settings.
Hallucination of speech recognition errors with sequence to sequence learning
Mar 31, 2021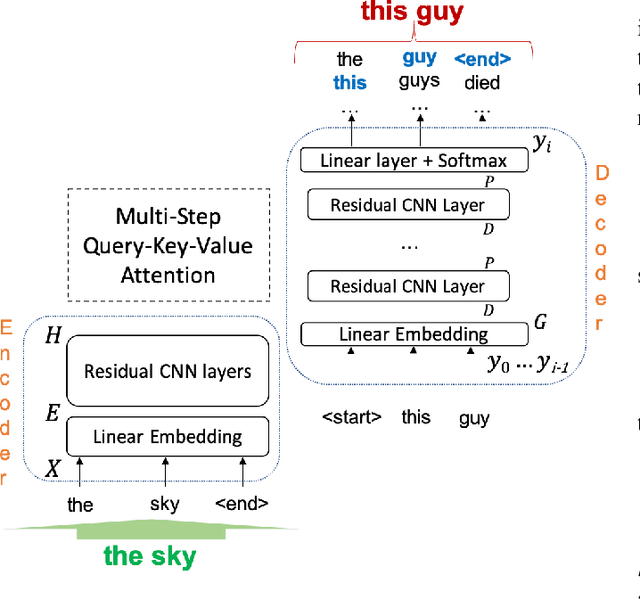
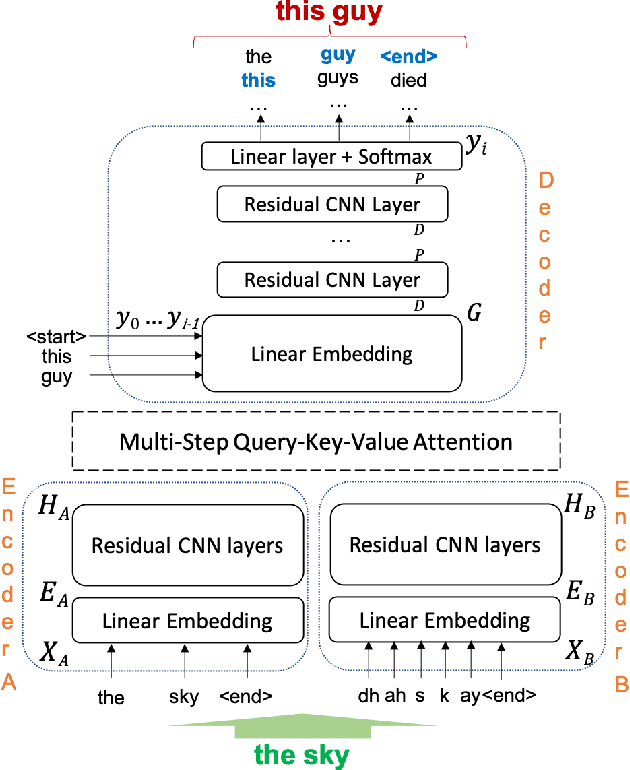
Automatic Speech Recognition (ASR) is an imperfect process that results in certain mismatches in ASR output text when compared to plain written text or transcriptions. When plain text data is to be used to train systems for spoken language understanding or ASR, a proven strategy to reduce said mismatch and prevent degradations, is to hallucinate what the ASR outputs would be given a gold transcription. Prior work in this domain has focused on modeling errors at the phonetic level, while using a lexicon to convert the phones to words, usually accompanied by an FST Language model. We present novel end-to-end models to directly predict hallucinated ASR word sequence outputs, conditioning on an input word sequence as well as a corresponding phoneme sequence. This improves prior published results for recall of errors from an in-domain ASR system's transcription of unseen data, as well as an out-of-domain ASR system's transcriptions of audio from an unrelated task, while additionally exploring an in-between scenario when limited characterization data from the test ASR system is obtainable. To verify the extrinsic validity of the method, we also use our hallucinated ASR errors to augment training for a spoken question classifier, finding that they enable robustness to real ASR errors in a downstream task, when scarce or even zero task-specific audio was available at train-time.