 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Selection of Text-to-speech Data to Augment ASR Training
May 30, 2023



This paper presents a method for selecting appropriate synthetic speech samples from a given large text-to-speech (TTS) dataset as supplementary training data for an automatic speech recognition (ASR) model. We trained a neural network, which can be optimised using cross-entropy loss or Arcface loss, to measure the similarity of a synthetic data to real speech. We found that incorporating synthetic samples with considerable dissimilarity to real speech, owing in part to lexical differences, into ASR training is crucial for boosting recognition performance. Experimental results on Librispeech test sets indicate that, in order to maintain the same speech recognition accuracy as when using all TTS data, our proposed solution can reduce the size of the TTS data down below its $30\,\%$, which is superior to several baseline methods.
Synthetic Cross-accent Data Augmentation for Automatic Speech Recognition
Mar 01, 2023


The awareness for biased ASR datasets or models has increased notably in recent years. Even for English, despite a vast amount of available training data, systems perform worse for non-native speakers. In this work, we improve an accent-conversion model (ACM) which transforms native US-English speech into accented pronunciation. We include phonetic knowledge in the ACM training to provide accurate feedback about how well certain pronunciation patterns were recovered in the synthesized waveform. Furthermore, we investigate the feasibility of learned accent representations instead of static embeddings. Generated data was then used to train two state-of-the-art ASR systems. We evaluated our approach on native and non-native English datasets and found that synthetically accented data helped the ASR to better understand speech from seen accents. This observation did not translate to unseen accents, and it was not observed for a model that had been pre-trained exclusively with native speech.
Towards Measuring Fairness in Speech Recognition: Casual Conversations Dataset Transcriptions
Nov 18, 2021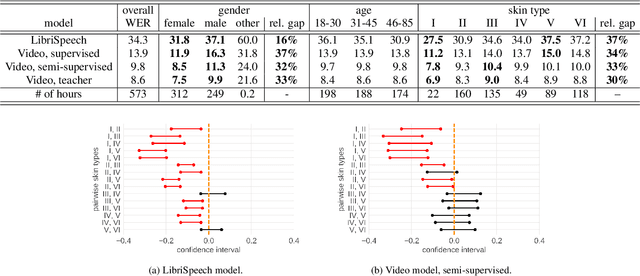

It is well known that many machine learning systems demonstrate bias towards specific groups of individuals. This problem has been studied extensively in the Facial Recognition area, but much less so in Automatic Speech Recognition (ASR). This paper presents initial Speech Recognition results on "Casual Conversations" -- a publicly released 846 hour corpus designed to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of metadata, including age, gender, and skin tone. The entire corpus has been manually transcribed, allowing for detailed ASR evaluations across these metadata. Multiple ASR models are evaluated, including models trained on LibriSpeech, 14,000 hour transcribed, and over 2 million hour untranscribed social media videos. Significant differences in word error rate across gender and skin tone are observed at times for all models. We are releasing human transcripts from the Casual Conversations dataset to encourage the community to develop a variety of techniques to reduce these statistical biases.
A Multi-View Approach To Audio-Visual Speaker Verification
Feb 11, 2021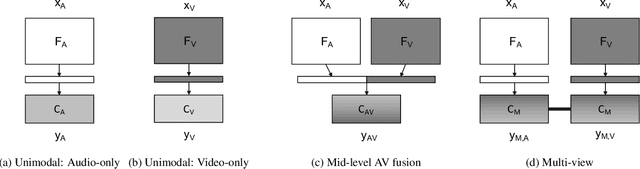
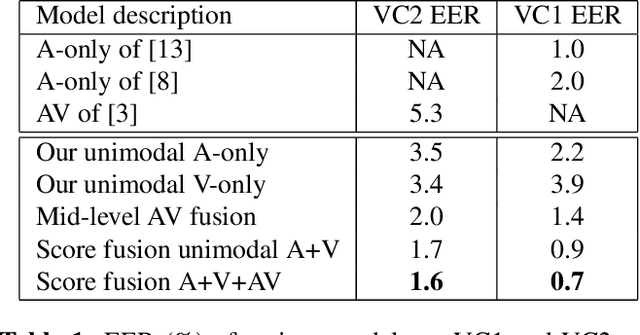

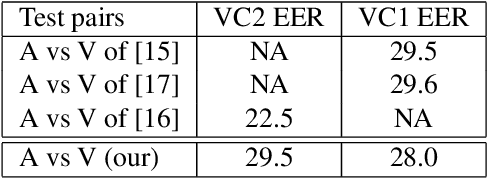
Although speaker verification has conventionally been an audio-only task, some practical applications provide both audio and visual streams of input. In these cases, the visual stream provides complementary information and can often be leveraged in conjunction with the acoustics of speech to improve verification performance. In this study, we explore audio-visual approaches to speaker verification, starting with standard fusion techniques to learn joint audio-visual (AV) embeddings, and then propose a novel approach to handle cross-modal verification at test time. Specifically, we investigate unimodal and concatenation based AV fusion and report the lowest AV equal error rate (EER) of 0.7% on the VoxCeleb1 dataset using our best system. As these methods lack the ability to do cross-modal verification, we introduce a multi-view model which uses a shared classifier to map audio and video into the same space. This new approach achieves 28% EER on VoxCeleb1 in the challenging testing condition of cross-modal verification.
Deep F-measure Maximization for End-to-End Speech Understanding
Aug 08, 2020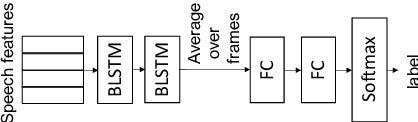
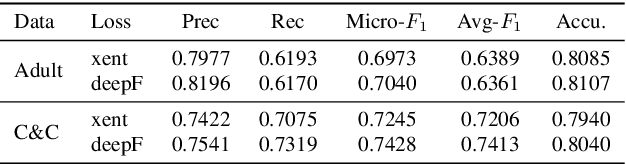
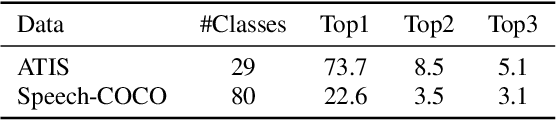
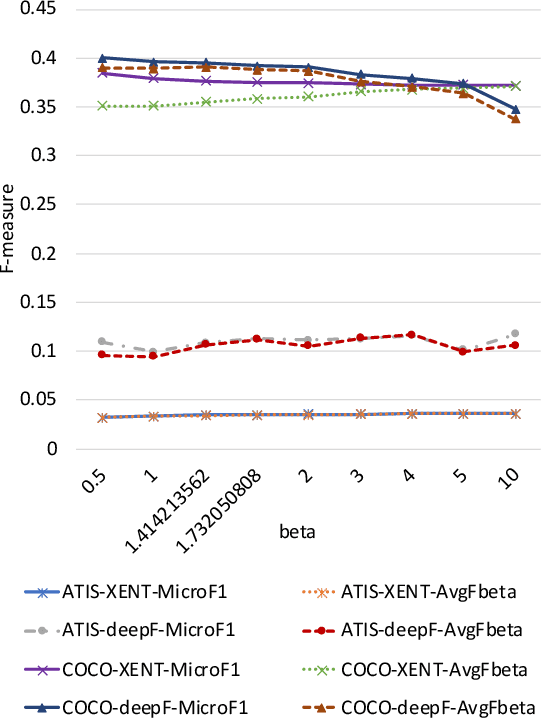
Spoken language understanding (SLU) datasets, like many other machine learning datasets, usually suffer from the label imbalance problem. Label imbalance usually causes the learned model to replicate similar biases at the output which raises the issue of unfairness to the minority classes in the dataset. In this work, we approach the fairness problem by maximizing the F-measure instead of accuracy in neural network model training. We propose a differentiable approximation to the F-measure and train the network with this objective using standard backpropagation. We perform experiments on two standard fairness datasets, Adult, and Communities and Crime, and also on speech-to-intent detection on the ATIS dataset and speech-to-image concept classification on the Speech-COCO dataset. In all four of these tasks, F-measure maximization results in improved micro-F1 scores, with absolute improvements of up to 8% absolute, as compared to models trained with the cross-entropy loss function. In the two multi-class SLU tasks, the proposed approach significantly improves class coverage, i.e., the number of classes with positive recall.
Unsupervised Speaker Adaptation using Attention-based Speaker Memory for End-to-End ASR
Feb 14, 2020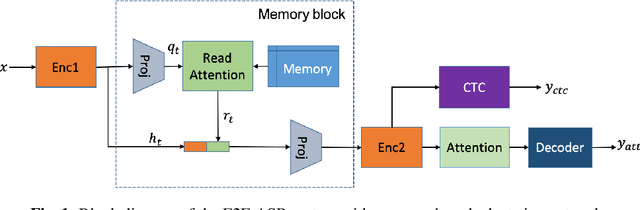
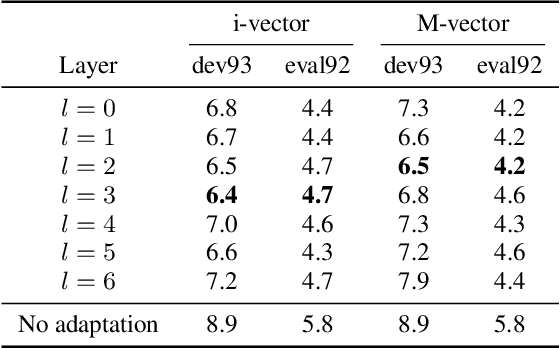
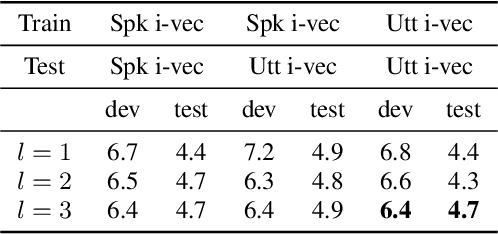

We propose an unsupervised speaker adaptation method inspired by the neural Turing machine for end-to-end (E2E) automatic speech recognition (ASR). The proposed model contains a memory block that holds speaker i-vectors extracted from the training data and reads relevant i-vectors from the memory through an attention mechanism. The resulting memory vector (M-vector) is concatenated to the acoustic features or to the hidden layer activations of an E2E neural network model. The E2E ASR system is based on the joint connectionist temporal classification and attention-based encoder-decoder architecture. M-vector and i-vector results are compared for inserting them at different layers of the encoder neural network using the WSJ and TED-LIUM2 ASR benchmarks. We show that M-vectors, which do not require an auxiliary speaker embedding extraction system at test time, achieve similar word error rates (WERs) compared to i-vectors for single speaker utterances and significantly lower WERs for utterances in which there are speaker changes.