 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Swapping for Zero-Shot Cross-Lingual Transfer in Large Language Models
Oct 02, 2024



Model merging, such as model souping, is the practice of combining different models with the same architecture together without further training. In this work, we present a model merging methodology that addresses the difficulty of fine-tuning Large Language Models (LLMs) for target tasks in non-English languages, where task-specific data is often unavailable. We focus on mathematical reasoning and without in-language math data, facilitate cross-lingual transfer by composing language and math capabilities. Starting from the same pretrained model, we fine-tune separate "experts" on math instruction data in English and on generic instruction data in the target language. We then replace the top and bottom transformer layers of the math expert directly with layers from the language expert, which consequently enhances math performance in the target language. The resulting merged models outperform the individual experts and other merging methods on the math benchmark, MGSM, by 10% across four major languages where math instruction data is scarce. In addition, this layer swapping is simple, inexpensive, and intuitive, as it is based on an interpretative analysis of the most important parameter changes during the fine-tuning of each expert. The ability to successfully re-compose LLMs for cross-lingual transfer in this manner opens up future possibilities to combine model expertise, create modular solutions, and transfer reasoning capabilities across languages all post hoc.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities
Nov 10, 2022
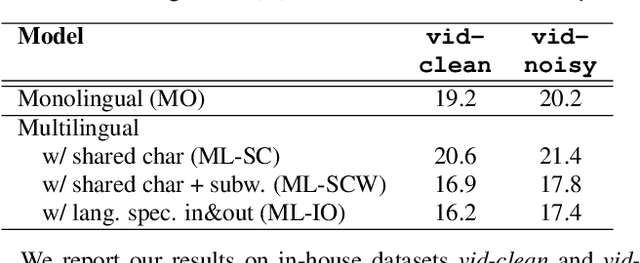


End-to-end multilingual ASR has become more appealing because of several reasons such as simplifying the training and deployment process and positive performance transfer from high-resource to low-resource languages. However, scaling up the number of languages, total hours, and number of unique tokens is not a trivial task. This paper explores large-scale multilingual ASR models on 70 languages. We inspect two architectures: (1) Shared embedding and output and (2) Multiple embedding and output model. In the shared model experiments, we show the importance of tokenization strategy across different languages. Later, we use our optimal tokenization strategy to train multiple embedding and output model to further improve our result. Our multilingual ASR achieves 13.9%-15.6% average WER relative improvement compared to monolingual models. We show that our multilingual ASR generalizes well on an unseen dataset and domain, achieving 9.5% and 7.5% WER on Multilingual Librispeech (MLS) with zero-shot and finetuning, respectively.
Transferring Voice Knowledge for Acoustic Event Detection: An Empirical Study
Oct 07, 2021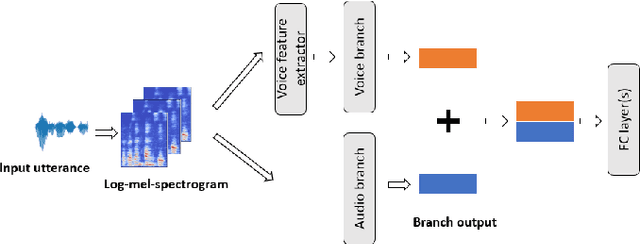
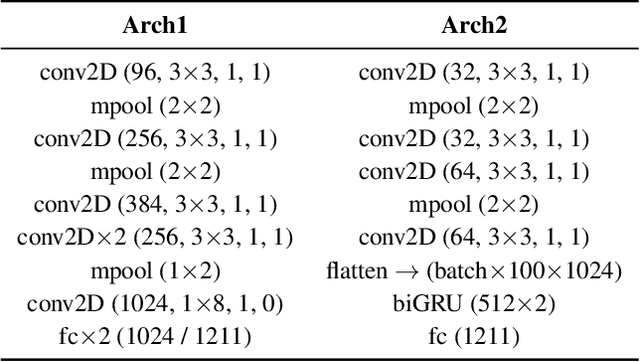
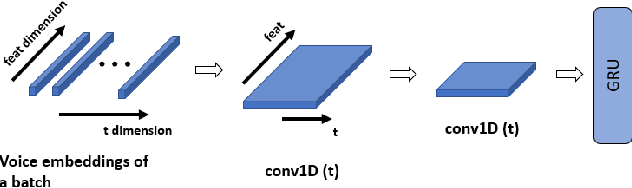
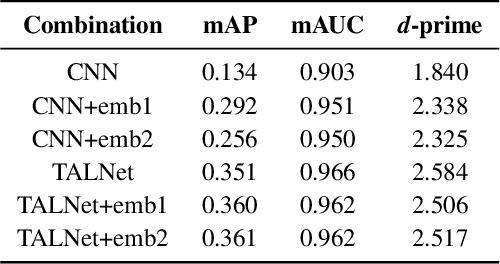
Detection of common events and scenes from audio is useful for extracting and understanding human contexts in daily life. Prior studies have shown that leveraging knowledge from a relevant domain is beneficial for a target acoustic event detection (AED) process. Inspired by the observation that many human-centered acoustic events in daily life involve voice elements, this paper investigates the potential of transferring high-level voice representations extracted from a public speaker dataset to enrich an AED pipeline. Towards this end, we develop a dual-branch neural network architecture for the joint learning of voice and acoustic features during an AED process and conduct thorough empirical studies to examine the performance on the public AudioSet [1] with different types of inputs. Our main observations are that: 1) Joint learning of audio and voice inputs improves the AED performance (mean average precision) for both a CNN baseline (0.292 vs 0.134 mAP) and a TALNet [2] baseline (0.361 vs 0.351 mAP); 2) Augmenting the extra voice features is critical to maximize the model performance with dual inputs.
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021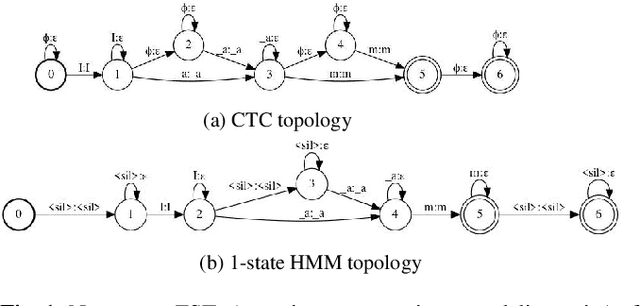
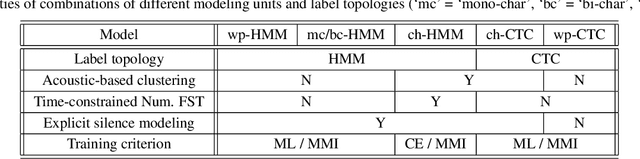
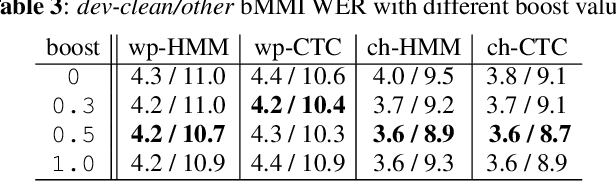
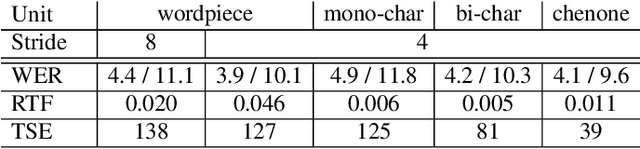
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
A Multi-View Approach To Audio-Visual Speaker Verification
Feb 11, 2021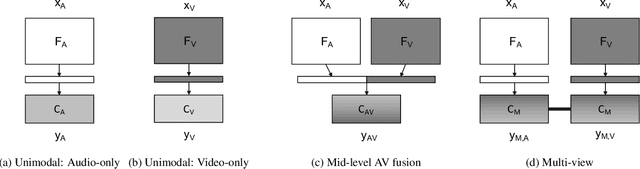
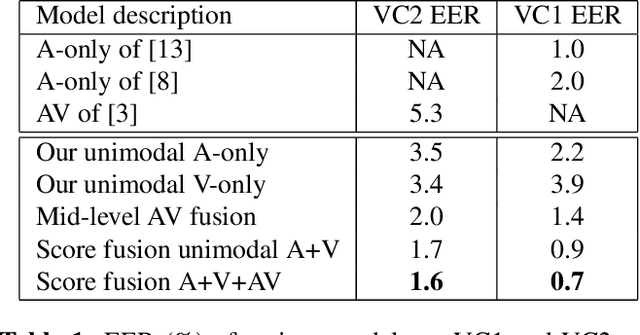

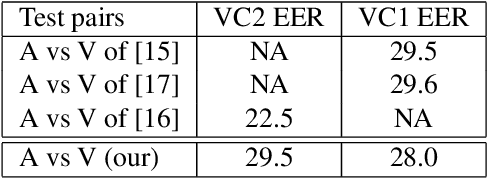
Although speaker verification has conventionally been an audio-only task, some practical applications provide both audio and visual streams of input. In these cases, the visual stream provides complementary information and can often be leveraged in conjunction with the acoustics of speech to improve verification performance. In this study, we explore audio-visual approaches to speaker verification, starting with standard fusion techniques to learn joint audio-visual (AV) embeddings, and then propose a novel approach to handle cross-modal verification at test time. Specifically, we investigate unimodal and concatenation based AV fusion and report the lowest AV equal error rate (EER) of 0.7% on the VoxCeleb1 dataset using our best system. As these methods lack the ability to do cross-modal verification, we introduce a multi-view model which uses a shared classifier to map audio and video into the same space. This new approach achieves 28% EER on VoxCeleb1 in the challenging testing condition of cross-modal verification.
Video Compression through Image Interpolation
Apr 18, 2018
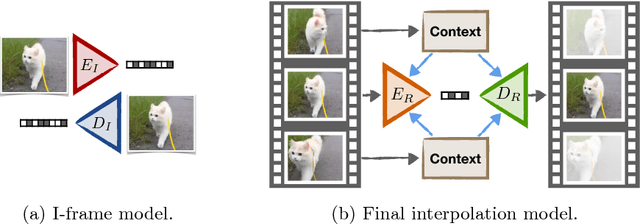


An ever increasing amount of our digital communication, media consumption, and content creation revolves around videos. We share, watch, and archive many aspects of our lives through them, all of which are powered by strong video compression. Traditional video compression is laboriously hand designed and hand optimized. This paper presents an alternative in an end-to-end deep learning codec. Our codec builds on one simple idea: Video compression is repeated image interpolation. It thus benefits from recent advances in deep image interpolation and generation. Our deep video codec outperforms today's prevailing codecs, such as H.261, MPEG-4 Part 2, and performs on par with H.264.