 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Noisy Training Improves E2E ASR for the Edge
Jul 09, 2021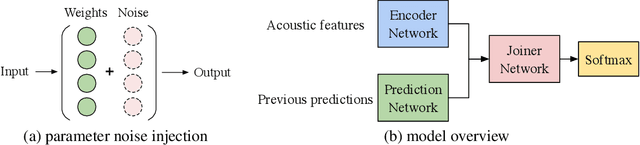
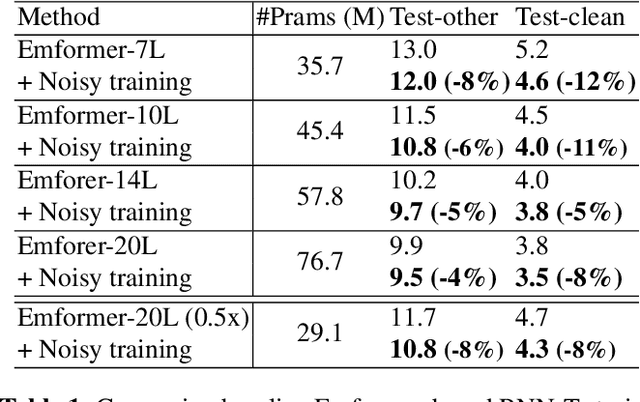
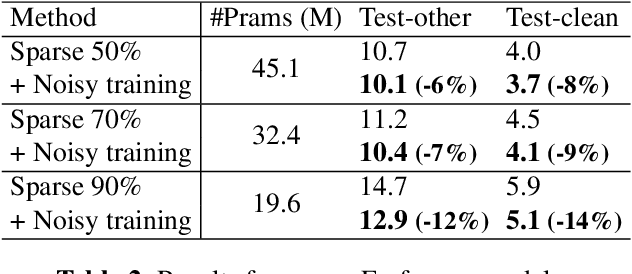
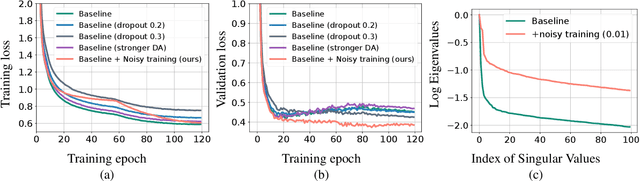
Automatic speech recognition (ASR) has become increasingly ubiquitous on modern edge devices. Past work developed streaming End-to-End (E2E) all-neural speech recognizers that can run compactly on edge devices. However, E2E ASR models are prone to overfitting and have difficulties in generalizing to unseen testing data. Various techniques have been proposed to regularize the training of ASR models, including layer normalization, dropout, spectrum data augmentation and speed distortions in the inputs. In this work, we present a simple yet effective noisy training strategy to further improve the E2E ASR model training. By introducing random noise to the parameter space during training, our method can produce smoother models at convergence that generalize better. We apply noisy training to improve both dense and sparse state-of-the-art Emformer models and observe consistent WER reduction. Specifically, when training Emformers with 90% sparsity, we achieve 12% and 14% WER improvements on the LibriSpeech Test-other and Test-clean data set, respectively.
Dissecting User-Perceived Latency of On-Device E2E Speech Recognition
Apr 06, 2021
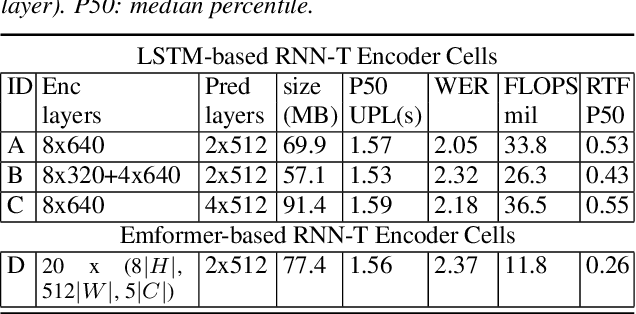

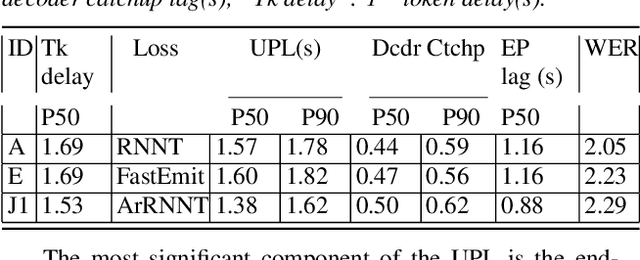
As speech-enabled devices such as smartphones and smart speakers become increasingly ubiquitous, there is growing interest in building automatic speech recognition (ASR) systems that can run directly on-device; end-to-end (E2E) speech recognition models such as recurrent neural network transducers and their variants have recently emerged as prime candidates for this task. Apart from being accurate and compact, such systems need to decode speech with low user-perceived latency (UPL), producing words as soon as they are spoken. This work examines the impact of various techniques -- model architectures, training criteria, decoding hyperparameters, and endpointer parameters -- on UPL. Our analyses suggest that measures of model size (parameters, input chunk sizes), or measures of computation (e.g., FLOPS, RTF) that reflect the model's ability to process input frames are not always strongly correlated with observed UPL. Thus, conventional algorithmic latency measurements might be inadequate in accurately capturing latency observed when models are deployed on embedded devices. Instead, we find that factors affecting token emission latency, and endpointing behavior significantly impact on UPL. We achieve the best trade-off between latency and word error rate when performing ASR jointly with endpointing, and using the recently proposed alignment regularization.
A Multi-View Approach To Audio-Visual Speaker Verification
Feb 11, 2021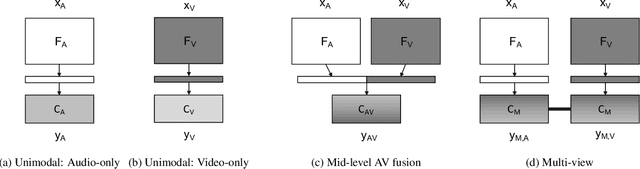
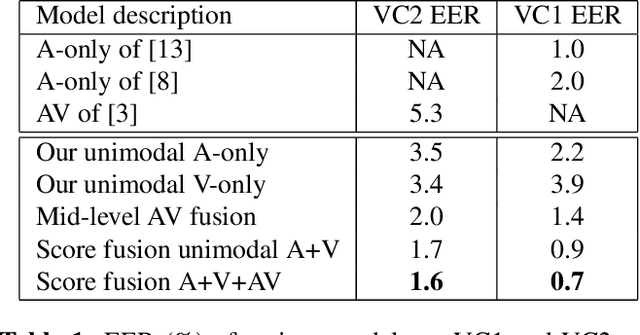

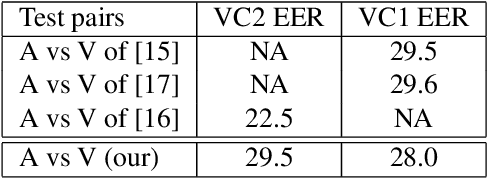
Although speaker verification has conventionally been an audio-only task, some practical applications provide both audio and visual streams of input. In these cases, the visual stream provides complementary information and can often be leveraged in conjunction with the acoustics of speech to improve verification performance. In this study, we explore audio-visual approaches to speaker verification, starting with standard fusion techniques to learn joint audio-visual (AV) embeddings, and then propose a novel approach to handle cross-modal verification at test time. Specifically, we investigate unimodal and concatenation based AV fusion and report the lowest AV equal error rate (EER) of 0.7% on the VoxCeleb1 dataset using our best system. As these methods lack the ability to do cross-modal verification, we introduce a multi-view model which uses a shared classifier to map audio and video into the same space. This new approach achieves 28% EER on VoxCeleb1 in the challenging testing condition of cross-modal verification.