 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting User-Perceived Latency of On-Device E2E Speech Recognition
Paper and Code
Apr 06, 2021
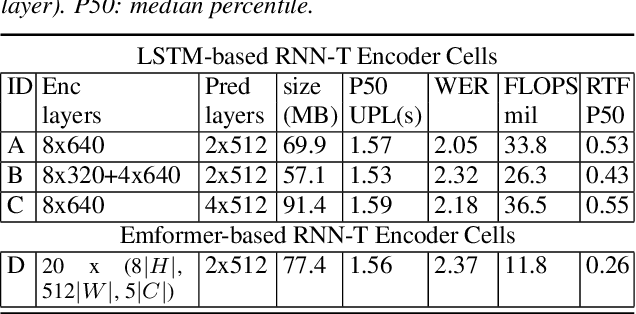

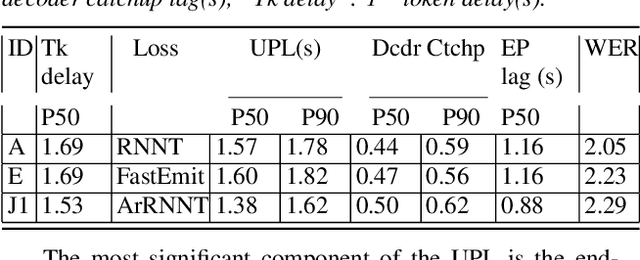
As speech-enabled devices such as smartphones and smart speakers become increasingly ubiquitous, there is growing interest in building automatic speech recognition (ASR) systems that can run directly on-device; end-to-end (E2E) speech recognition models such as recurrent neural network transducers and their variants have recently emerged as prime candidates for this task. Apart from being accurate and compact, such systems need to decode speech with low user-perceived latency (UPL), producing words as soon as they are spoken. This work examines the impact of various techniques -- model architectures, training criteria, decoding hyperparameters, and endpointer parameters -- on UPL. Our analyses suggest that measures of model size (parameters, input chunk sizes), or measures of computation (e.g., FLOPS, RTF) that reflect the model's ability to process input frames are not always strongly correlated with observed UPL. Thus, conventional algorithmic latency measurements might be inadequate in accurately capturing latency observed when models are deployed on embedded devices. Instead, we find that factors affecting token emission latency, and endpointing behavior significantly impact on UPL. We achieve the best trade-off between latency and word error rate when performing ASR jointly with endpointing, and using the recently proposed alignment regularization.