 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Weights Are Created Equal: Enhancing Energy Efficiency in On-Device Streaming Speech Recognition
Feb 20, 2024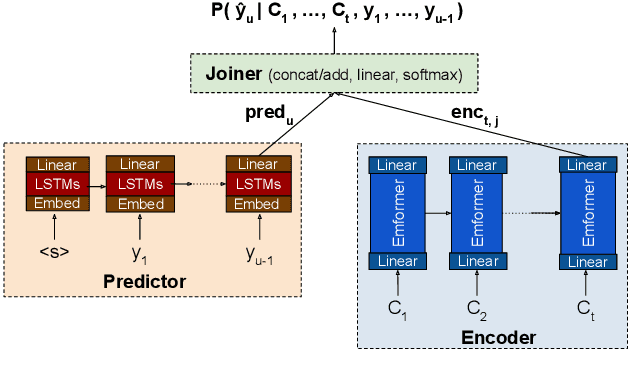
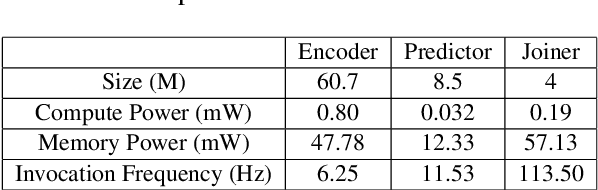
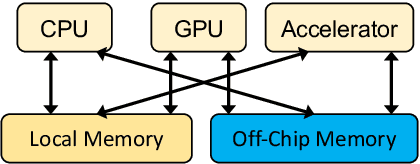
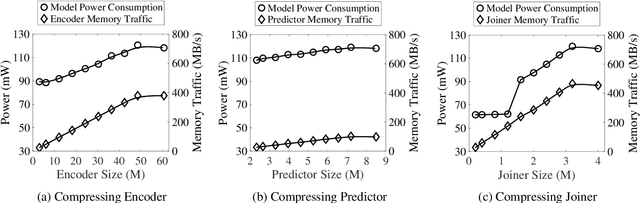
Power consumption plays an important role in on-device streaming speech recognition, as it has a direct impact on the user experience. This study delves into how weight parameters in speech recognition models influence the overall power consumption of these models. We discovered that the impact of weight parameters on power consumption varies, influenced by factors including how often they are invoked and their placement in memory. Armed with this insight, we developed design guidelines aimed at optimizing on-device speech recognition models. These guidelines focus on minimizing power use without substantially affecting accuracy. Our method, which employs targeted compression based on the varying sensitivities of weight parameters, demonstrates superior performance compared to state-of-the-art compression methods. It achieves a reduction in energy usage of up to 47% while maintaining similar model accuracy and improving the real-time factor.
Towards General-Purpose Speech Abilities for Large Language Models Using Unpaired Data
Nov 12, 2023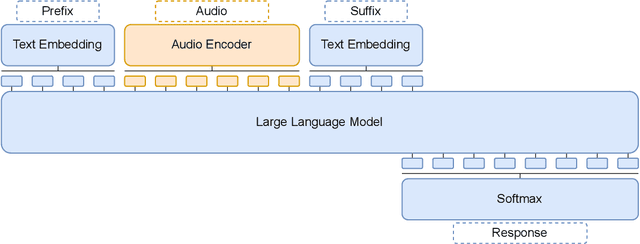

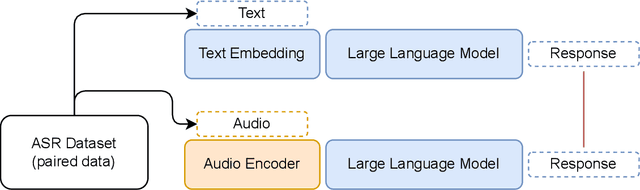
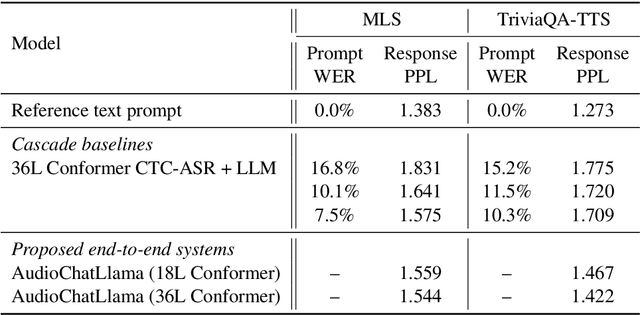
In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of LLM capabilities, without using any carefully curated paired data. The proposed model can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform speech question answering, speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. Experiments show that our end-to-end approach is on par with or outperforms a cascaded system (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike a cascade, our approach shows the ability to interchange text and audio modalities and utilize the prior context in a conversation to provide better results.
Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
Sep 22, 2023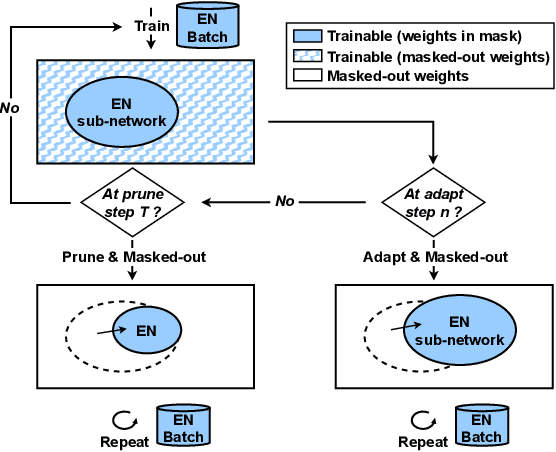



Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 21, 2023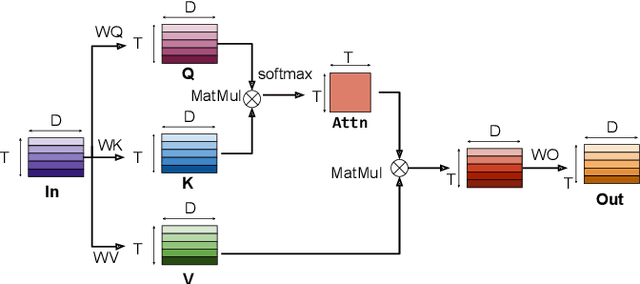
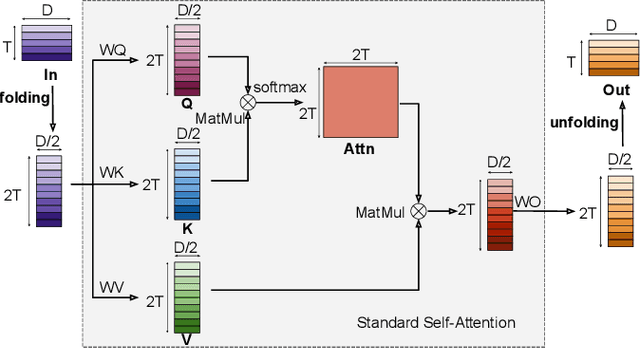
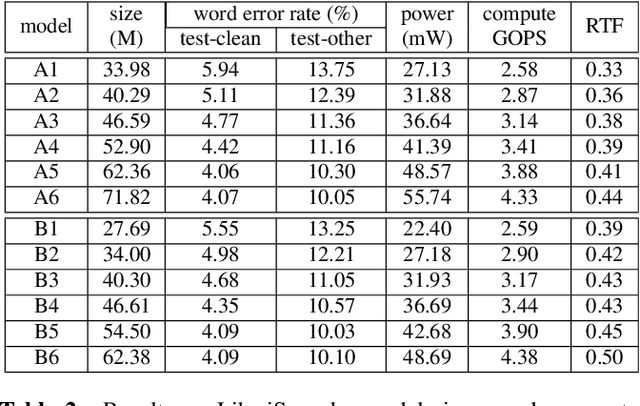
Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023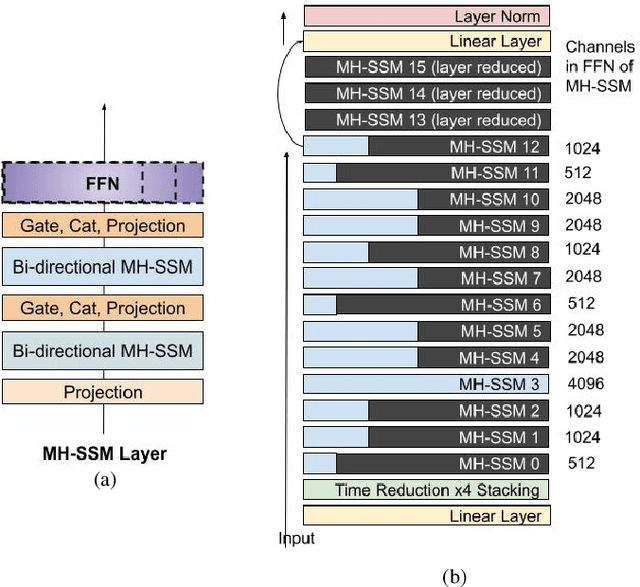
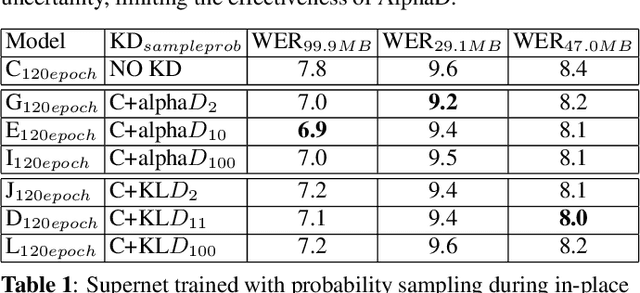
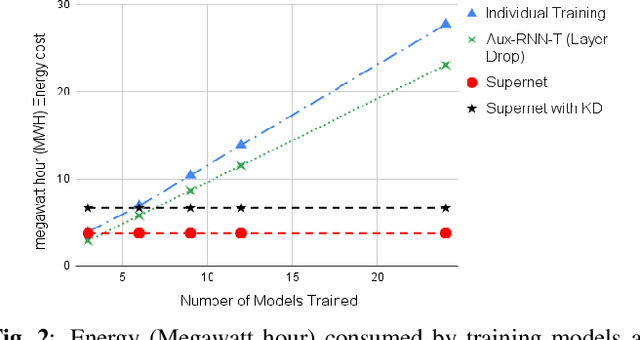
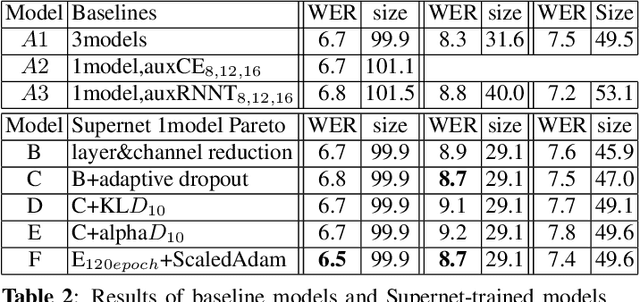
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Prompting Large Language Models with Speech Recognition Abilities
Jul 21, 2023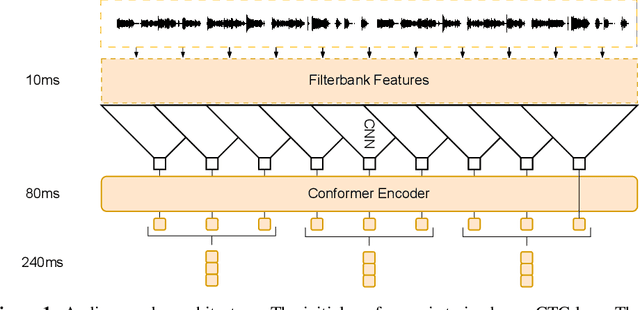
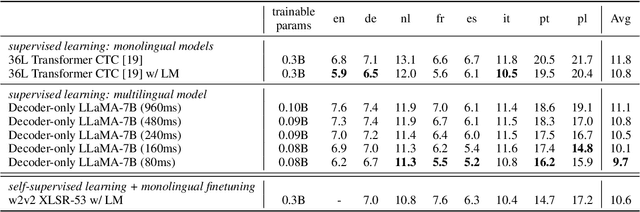
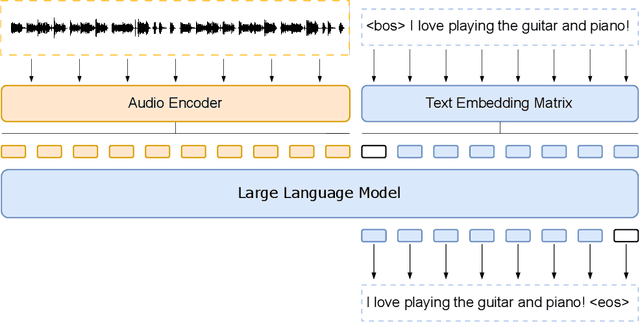

Large language models have proven themselves highly flexible, able to solve a wide range of generative tasks, such as abstractive summarization and open-ended question answering. In this paper we extend the capabilities of LLMs by directly attaching a small audio encoder allowing it to perform speech recognition. By directly prepending a sequence of audial embeddings to the text token embeddings, the LLM can be converted to an automatic speech recognition (ASR) system, and be used in the exact same manner as its textual counterpart. Experiments on Multilingual LibriSpeech (MLS) show that incorporating a conformer encoder into the open sourced LLaMA-7B allows it to outperform monolingual baselines by 18% and perform multilingual speech recognition despite LLaMA being trained overwhelmingly on English text. Furthermore, we perform ablation studies to investigate whether the LLM can be completely frozen during training to maintain its original capabilities, scaling up the audio encoder, and increasing the audio encoder striding to generate fewer embeddings. The results from these studies show that multilingual ASR is possible even when the LLM is frozen or when strides of almost 1 second are used in the audio encoder opening up the possibility for LLMs to operate on long-form audio.
Towards Selection of Text-to-speech Data to Augment ASR Training
May 30, 2023



This paper presents a method for selecting appropriate synthetic speech samples from a given large text-to-speech (TTS) dataset as supplementary training data for an automatic speech recognition (ASR) model. We trained a neural network, which can be optimised using cross-entropy loss or Arcface loss, to measure the similarity of a synthetic data to real speech. We found that incorporating synthetic samples with considerable dissimilarity to real speech, owing in part to lexical differences, into ASR training is crucial for boosting recognition performance. Experimental results on Librispeech test sets indicate that, in order to maintain the same speech recognition accuracy as when using all TTS data, our proposed solution can reduce the size of the TTS data down below its $30\,\%$, which is superior to several baseline methods.
Multi-Head State Space Model for Speech Recognition
May 25, 2023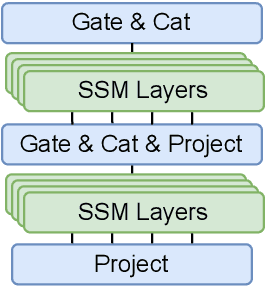
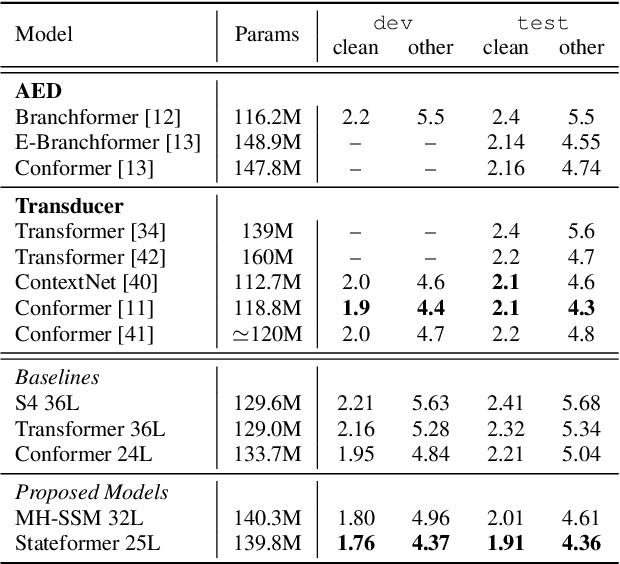
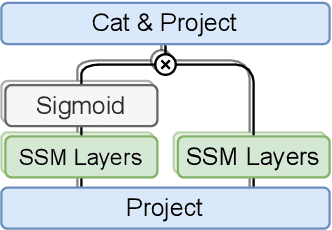
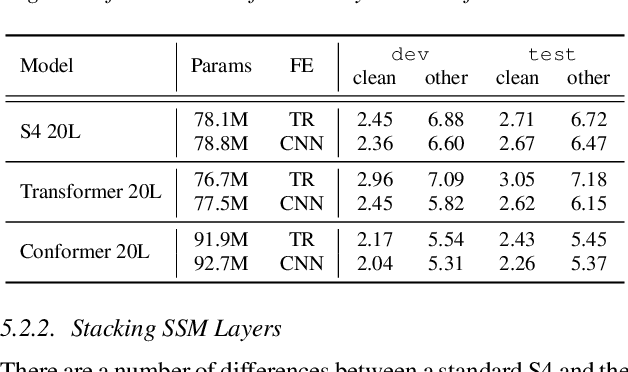
State space models (SSMs) have recently shown promising results on small-scale sequence and language modelling tasks, rivalling and outperforming many attention-based approaches. In this paper, we propose a multi-head state space (MH-SSM) architecture equipped with special gating mechanisms, where parallel heads are taught to learn local and global temporal dynamics on sequence data. As a drop-in replacement for multi-head attention in transformer encoders, this new model significantly outperforms the transformer transducer on the LibriSpeech speech recognition corpus. Furthermore, we augment the transformer block with MH-SSMs layers, referred to as the Stateformer, achieving state-of-the-art performance on the LibriSpeech task, with word error rates of 1.76\%/4.37\% on the development and 1.91\%/4.36\% on the test sets without using an external language model.
Handling the Alignment for Wake Word Detection: A Comparison Between Alignment-Based, Alignment-Free and Hybrid Approaches
Feb 17, 2023
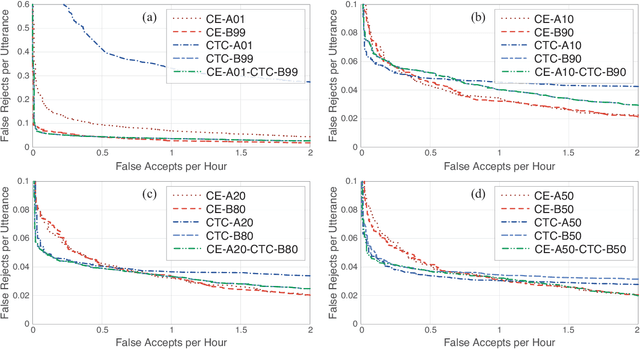
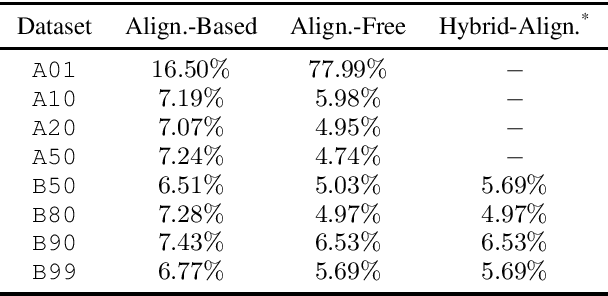

Wake word detection exists in most intelligent homes and portable devices. It offers these devices the ability to "wake up" when summoned at a low cost of power and computing. This paper focuses on understanding alignment's role in developing a wake-word system that answers a generic phrase. We discuss three approaches. The first is alignment-based, where the model is trained with frame-wise cross-entropy. The second is alignment-free, where the model is trained with CTC. The third, proposed by us, is a hybrid solution in which the model is trained with a small set of aligned data and then tuned with a sizeable unaligned dataset. We compare the three approaches and evaluate the impact of the different aligned-to-unaligned ratios for hybrid training. Our results show that the alignment-free system performs better alignment-based for the target operating point, and with a small fraction of the data (20%), we can train a model that complies with our initial constraints.
Learning a Dual-Mode Speech Recognition Model via Self-Pruning
Jul 25, 2022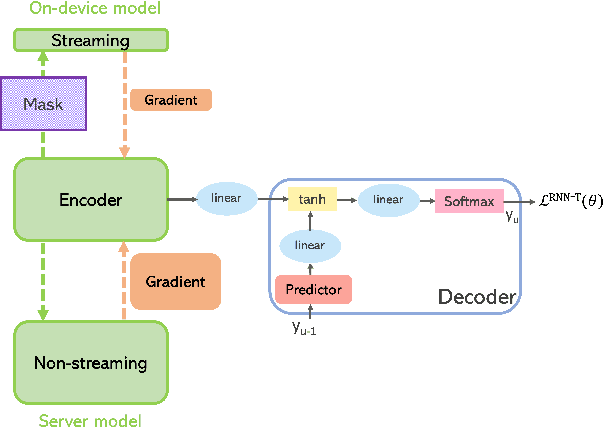

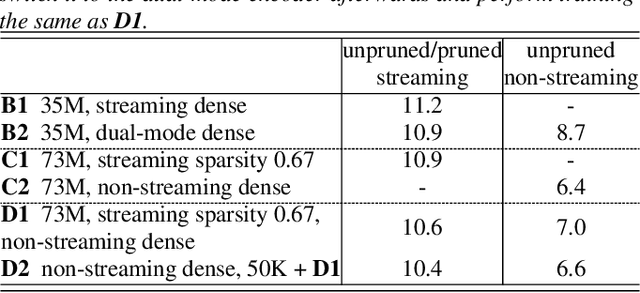

There is growing interest in unifying the streaming and full-context automatic speech recognition (ASR) networks into a single end-to-end ASR model to simplify the model training and deployment for both use cases. While in real-world ASR applications, the streaming ASR models typically operate under more storage and computational constraints - e.g., on embedded devices - than any server-side full-context models. Motivated by the recent progress in Omni-sparsity supernet training, where multiple subnetworks are jointly optimized in one single model, this work aims to jointly learn a compact sparse on-device streaming ASR model, and a large dense server non-streaming model, in a single supernet. Next, we present that, performing supernet training on both wav2vec 2.0 self-supervised learning and supervised ASR fine-tuning can not only substantially improve the large non-streaming model as shown in prior works, and also be able to improve the compact sparse streaming model.