 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Large Language Models with Speech Recognition Abilities
Paper and Code
Jul 21, 2023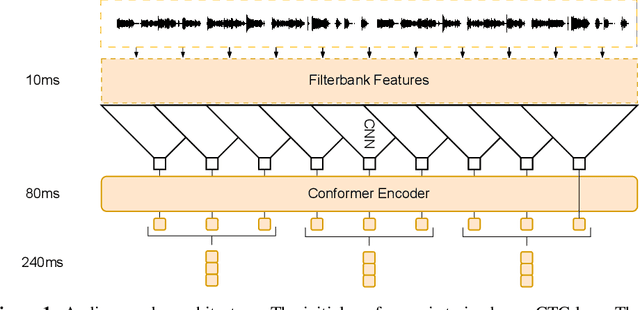
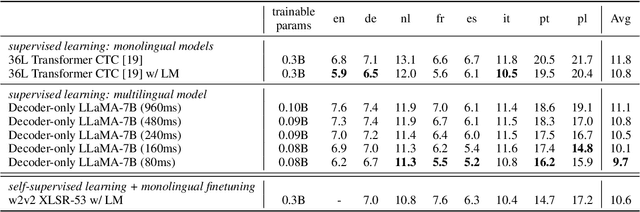
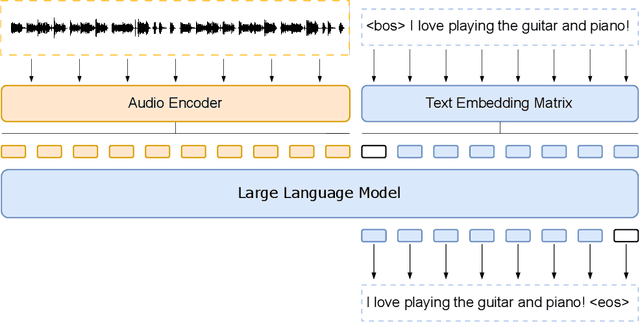

Large language models have proven themselves highly flexible, able to solve a wide range of generative tasks, such as abstractive summarization and open-ended question answering. In this paper we extend the capabilities of LLMs by directly attaching a small audio encoder allowing it to perform speech recognition. By directly prepending a sequence of audial embeddings to the text token embeddings, the LLM can be converted to an automatic speech recognition (ASR) system, and be used in the exact same manner as its textual counterpart. Experiments on Multilingual LibriSpeech (MLS) show that incorporating a conformer encoder into the open sourced LLaMA-7B allows it to outperform monolingual baselines by 18% and perform multilingual speech recognition despite LLaMA being trained overwhelmingly on English text. Furthermore, we perform ablation studies to investigate whether the LLM can be completely frozen during training to maintain its original capabilities, scaling up the audio encoder, and increasing the audio encoder striding to generate fewer embeddings. The results from these studies show that multilingual ASR is possible even when the LLM is frozen or when strides of almost 1 second are used in the audio encoder opening up the possibility for LLMs to operate on long-form audio.