 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaw of the Weakest Link: Cross Capabilities of Large Language Models
Sep 30, 2024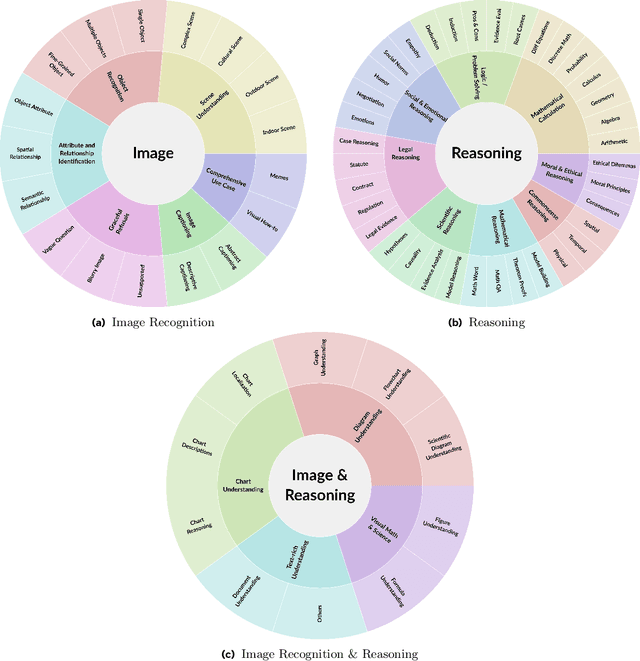
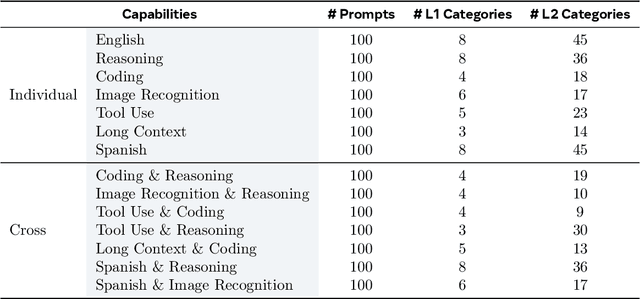
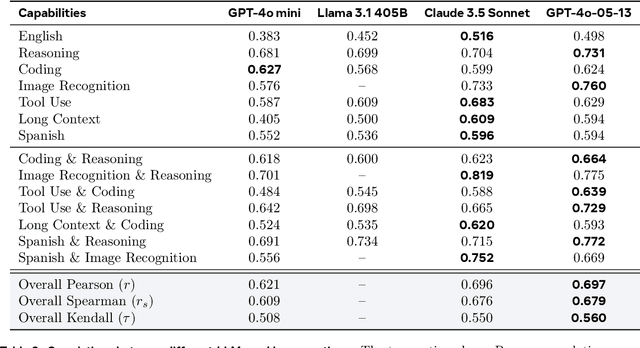
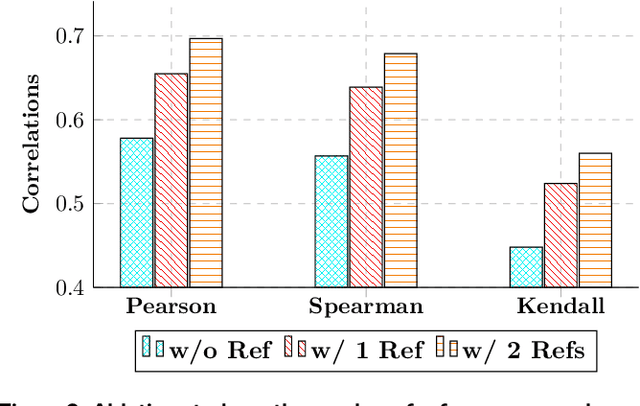
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
FLAME: Factuality-Aware Alignment for Large Language Models
May 02, 2024



Alignment is a standard procedure to fine-tune pre-trained large language models (LLMs) to follow natural language instructions and serve as helpful AI assistants. We have observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts (i.e. hallucination). In this paper, we study how to make the LLM alignment process more factual, by first identifying factors that lead to hallucination in both alignment steps:\ supervised fine-tuning (SFT) and reinforcement learning (RL). In particular, we find that training the LLM on new knowledge or unfamiliar texts can encourage hallucination. This makes SFT less factual as it trains on human labeled data that may be novel to the LLM. Furthermore, reward functions used in standard RL can also encourage hallucination, because it guides the LLM to provide more helpful responses on a diverse set of instructions, often preferring longer and more detailed responses. Based on these observations, we propose factuality-aware alignment, comprised of factuality-aware SFT and factuality-aware RL through direct preference optimization. Experiments show that our proposed factuality-aware alignment guides LLMs to output more factual responses while maintaining instruction-following capability.
Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
Apr 12, 2024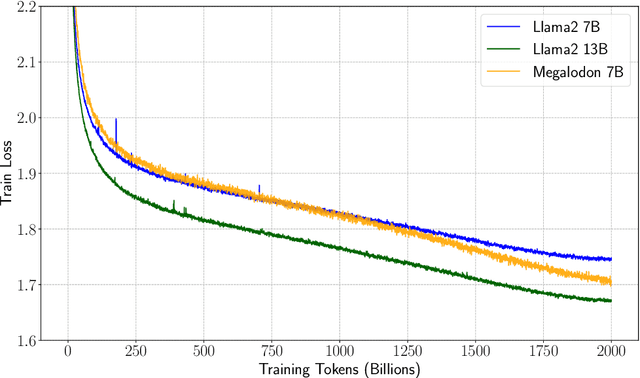
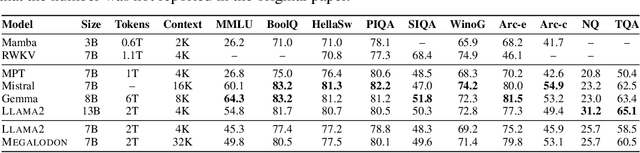
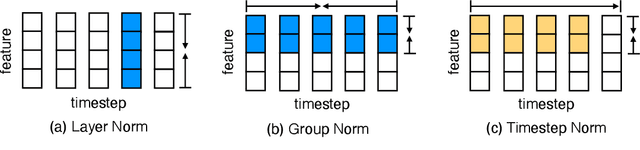
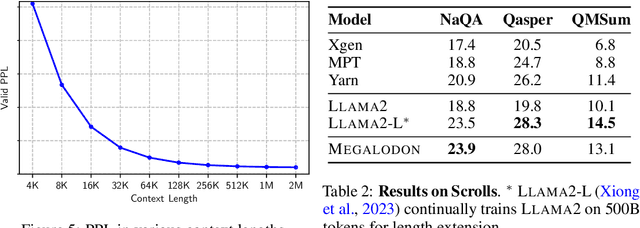
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability and stability, including complex exponential moving average (CEMA), timestep normalization layer, normalized attention mechanism and pre-norm with two-hop residual configuration. In a controlled head-to-head comparison with Llama2, Megalodon achieves better efficiency than Transformer in the scale of 7 billion parameters and 2 trillion training tokens. Megalodon reaches a training loss of 1.70, landing mid-way between Llama2-7B (1.75) and 13B (1.67). Code: https://github.com/XuezheMax/megalodon
Scene-LLM: Extending Language Model for 3D Visual Understanding and Reasoning
Mar 22, 2024



This paper introduces Scene-LLM, a 3D-visual-language model that enhances embodied agents' abilities in interactive 3D indoor environments by integrating the reasoning strengths of Large Language Models (LLMs). Scene-LLM adopts a hybrid 3D visual feature representation, that incorporates dense spatial information and supports scene state updates. The model employs a projection layer to efficiently project these features in the pre-trained textual embedding space, enabling effective interpretation of 3D visual information. Unique to our approach is the integration of both scene-level and ego-centric 3D information. This combination is pivotal for interactive planning, where scene-level data supports global planning and ego-centric data is important for localization. Notably, we use ego-centric 3D frame features for feature alignment, an efficient technique that enhances the model's ability to align features of small objects within the scene. Our experiments with Scene-LLM demonstrate its strong capabilities in dense captioning, question answering, and interactive planning. We believe Scene-LLM advances the field of 3D visual understanding and reasoning, offering new possibilities for sophisticated agent interactions in indoor settings.
The Role of Chain-of-Thought in Complex Vision-Language Reasoning Task
Nov 15, 2023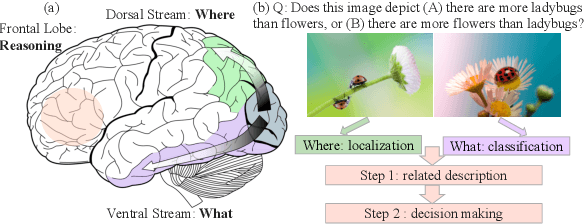



The study explores the effectiveness of the Chain-of-Thought approach, known for its proficiency in language tasks by breaking them down into sub-tasks and intermediate steps, in improving vision-language tasks that demand sophisticated perception and reasoning. We present the "Description then Decision" strategy, which is inspired by how humans process signals. This strategy significantly improves probing task performance by 50%, establishing the groundwork for future research on reasoning paradigms in complex vision-language tasks.
Sub-network Discovery and Soft-masking for Continual Learning of Mixed Tasks
Oct 13, 2023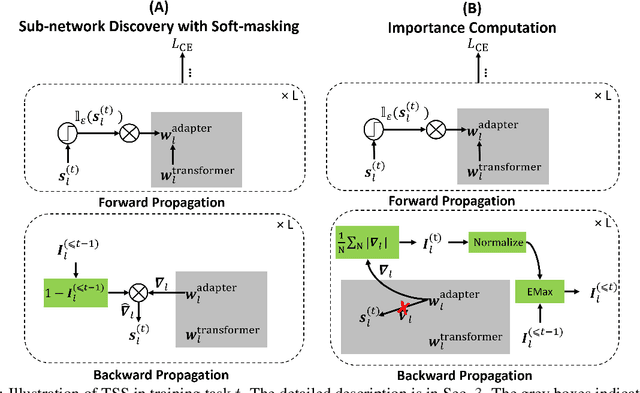
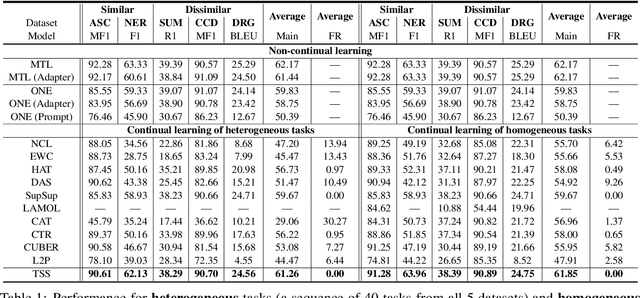
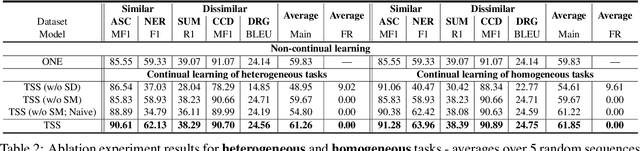
Continual learning (CL) has two main objectives: preventing catastrophic forgetting (CF) and encouraging knowledge transfer (KT). The existing literature mainly focused on overcoming CF. Some work has also been done on KT when the tasks are similar. To our knowledge, only one method has been proposed to learn a sequence of mixed tasks. However, these techniques still suffer from CF and/or limited KT. This paper proposes a new CL method to achieve both. It overcomes CF by isolating the knowledge of each task via discovering a subnetwork for it. A soft-masking mechanism is also proposed to preserve the previous knowledge and to enable the new task to leverage the past knowledge to achieve KT. Experiments using classification, generation, information extraction, and their mixture (i.e., heterogeneous tasks) show that the proposed method consistently outperforms strong baselines.
* https://github.com/ZixuanKe/PyContinual
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023



We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models
Sep 07, 2023In recent years, there have been remarkable advancements in the performance of Transformer-based Large Language Models (LLMs) across various domains. As these LLMs are deployed for increasingly complex tasks, they often face the need to conduct longer reasoning processes or understand larger contexts. In these situations, the length generalization failure of LLMs on long sequences becomes more prominent. Most pre-training schemes truncate training sequences to a fixed length. LLMs often struggle to generate fluent and coherent texts, let alone carry out downstream tasks, after longer contexts, even with relative positional encoding designed to cope with this problem. Common solutions such as finetuning on longer corpora often involve daunting hardware and time costs and require careful training process design. To more efficiently leverage the generation capacity of existing LLMs, we theoretically and empirically investigate the main out-of-distribution (OOD) factors contributing to this problem. Inspired by this diagnosis, we propose a simple yet effective solution for on-the-fly length generalization, LM-Infinite. It involves only a $\Lambda$-shaped attention mask (to avoid excessive attended tokens) and a distance limit (to avoid unseen distances) while requiring no parameter updates or learning. We find it applicable to a variety of LLMs using relative-position encoding methods. LM-Infinite is computationally efficient with $O(n)$ time and space, and demonstrates consistent text generation fluency and quality to as long as 32k tokens on ArXiv and OpenWebText2 datasets, with 2.72x decoding speedup. On downstream tasks such as passkey retrieval, it continues to work on inputs much longer than training lengths where vanilla models fail immediately.
Code Llama: Open Foundation Models for Code
Aug 25, 2023
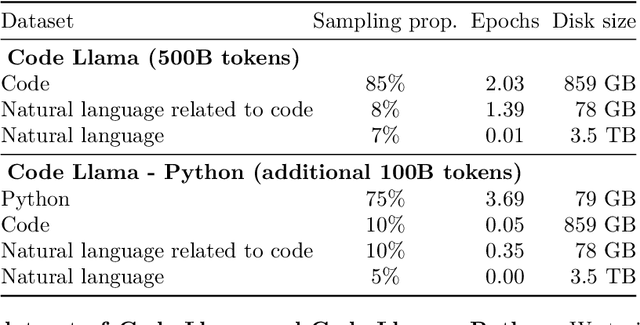
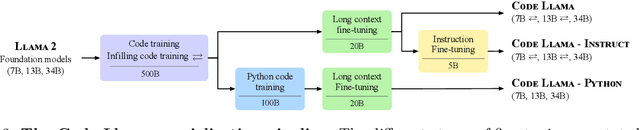
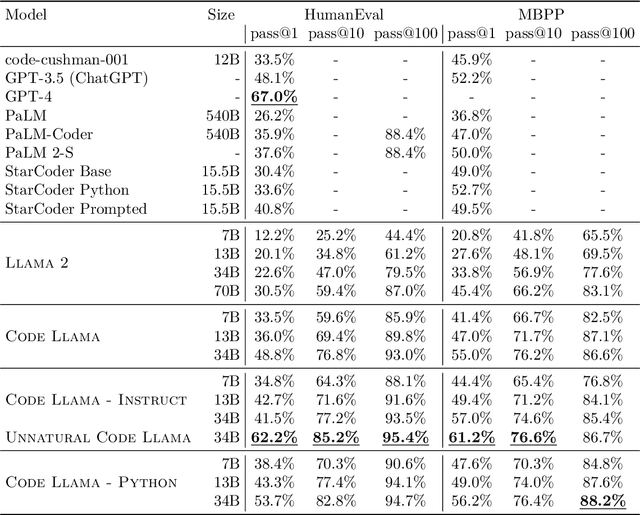
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.