 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025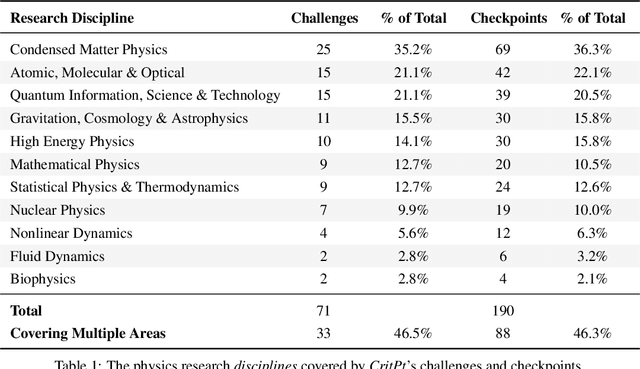
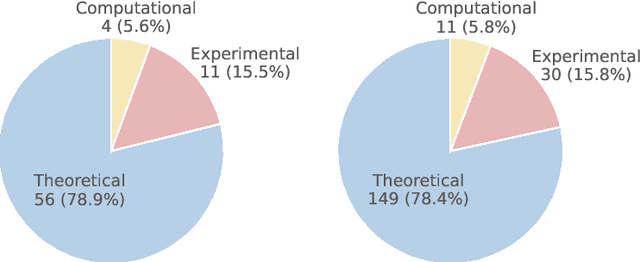
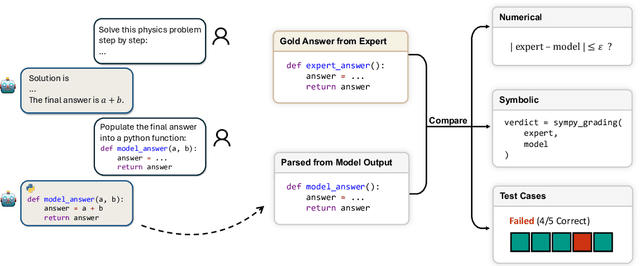

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Tevatron 2.0: Unified Document Retrieval Toolkit across Scale, Language, and Modality
May 05, 2025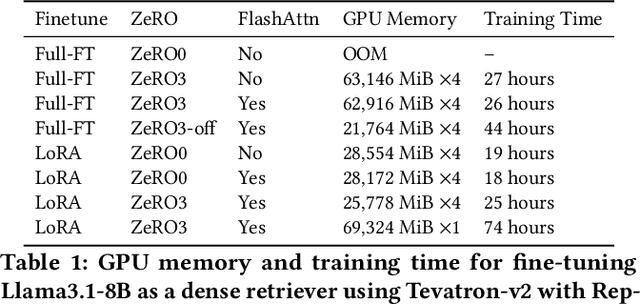
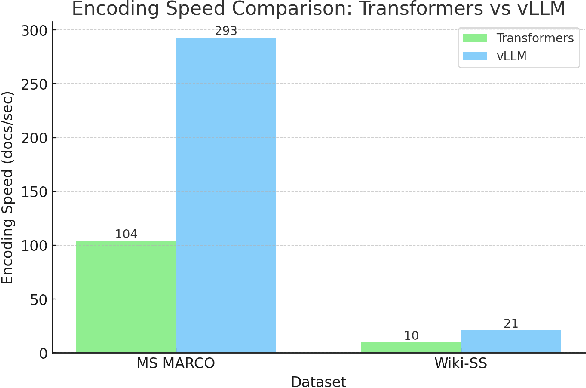
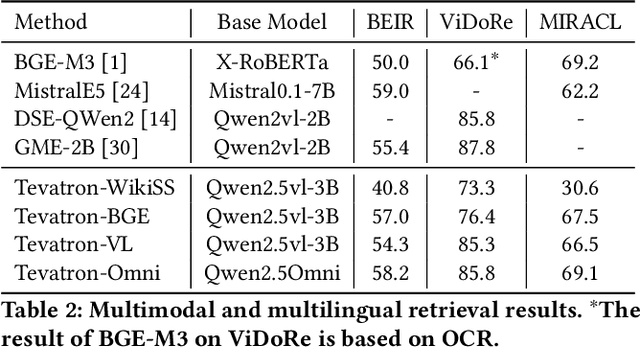

Recent advancements in large language models (LLMs) have driven interest in billion-scale retrieval models with strong generalization across retrieval tasks and languages. Additionally, progress in large vision-language models has created new opportunities for multimodal retrieval. In response, we have updated the Tevatron toolkit, introducing a unified pipeline that enables researchers to explore retriever models at different scales, across multiple languages, and with various modalities. This demo paper highlights the toolkit's key features, bridging academia and industry by supporting efficient training, inference, and evaluation of neural retrievers. We showcase a unified dense retriever achieving strong multilingual and multimodal effectiveness, and conduct a cross-modality zero-shot study to demonstrate its research potential. Alongside, we release OmniEmbed, to the best of our knowledge, the first embedding model that unifies text, image document, video, and audio retrieval, serving as a baseline for future research.
Repository-level Code Search with Neural Retrieval Methods
Feb 10, 2025
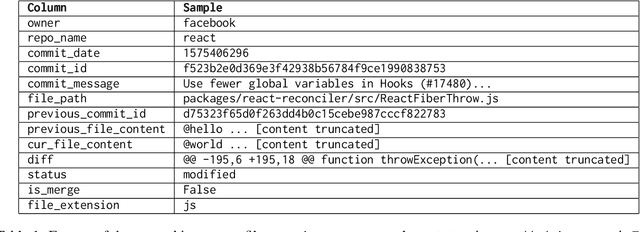
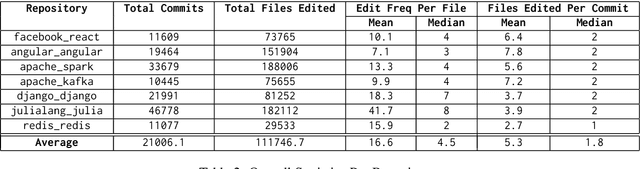

This paper presents a multi-stage reranking system for repository-level code search, which leverages the vastly available commit histories of large open-source repositories to aid in bug fixing. We define the task of repository-level code search as retrieving the set of files from the current state of a code repository that are most relevant to addressing a user's question or bug. The proposed approach combines BM25-based retrieval over commit messages with neural reranking using CodeBERT to identify the most pertinent files. By learning patterns from diverse repositories and their commit histories, the system can surface relevant files for the task at hand. The system leverages both commit messages and source code for relevance matching, and is evaluated in both normal and oracle settings. Experiments on a new dataset created from 7 popular open-source repositories demonstrate substantial improvements of up to 80% in MAP, MRR and P@1 over the BM25 baseline, across a diverse set of queries, demonstrating the effectiveness this approach. We hope this work aids LLM agents as a tool for better code search and understanding. Our code and results obtained are publicly available.
ACER: Automatic Language Model Context Extension via Retrieval
Oct 11, 2024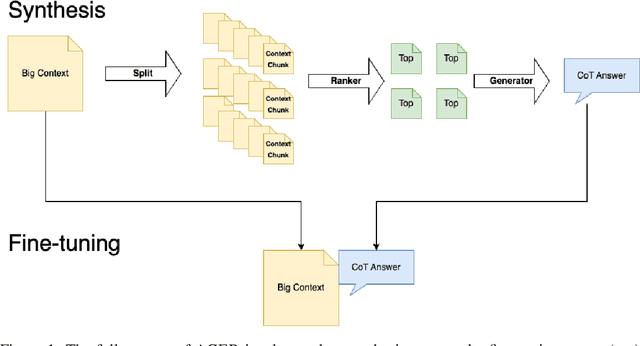
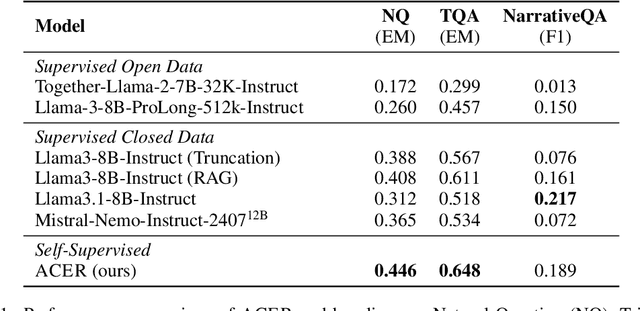

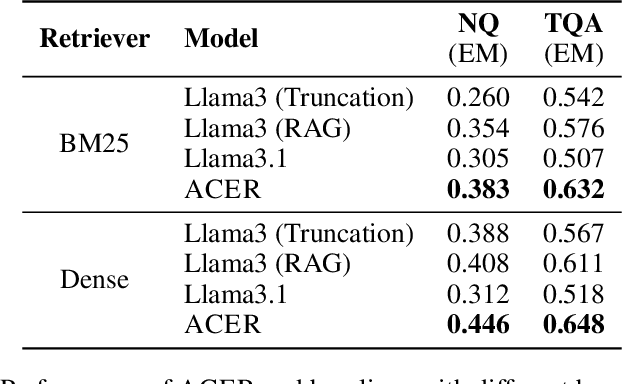
Long-context modeling is one of the critical capabilities of language AI for digesting and reasoning over complex information pieces. In practice, long-context capabilities are typically built into a pre-trained language model~(LM) through a carefully designed context extension stage, with the goal of producing generalist long-context capabilities. In our preliminary experiments, however, we discovered that the current open-weight generalist long-context models are still lacking in practical long-context processing tasks. While this means perfectly effective long-context modeling demands task-specific data, the cost can be prohibitive. In this paper, we draw inspiration from how humans process a large body of information: a lossy \textbf{retrieval} stage ranks a large set of documents while the reader ends up reading deeply only the top candidates. We build an \textbf{automatic} data synthesis pipeline that mimics this process using short-context LMs. The short-context LMs are further tuned using these self-generated data to obtain task-specific long-context capabilities. Similar to how pre-training learns from imperfect data, we hypothesize and further demonstrate that the short-context model can bootstrap over the synthetic data, outperforming not only long-context generalist models but also the retrieval and read pipeline used to synthesize the training data in real-world tasks such as long-context retrieval augmented generation.
SciCode: A Research Coding Benchmark Curated by Scientists
Jul 18, 2024



Since language models (LMs) now outperform average humans on many challenging tasks, it has become increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this issue by examining LMs' capabilities to generate code for solving real scientific research problems. Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we created a scientist-curated coding benchmark, SciCode. The problems in SciCode naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems. It offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. Claude3.5-Sonnet, the best-performing model among those tested, can solve only 4.6% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs' progress towards becoming helpful scientific assistants and sheds light on the development and evaluation of scientific AI in the future.