 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciCode: A Research Coding Benchmark Curated by Scientists
Jul 18, 2024



Since language models (LMs) now outperform average humans on many challenging tasks, it has become increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this issue by examining LMs' capabilities to generate code for solving real scientific research problems. Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we created a scientist-curated coding benchmark, SciCode. The problems in SciCode naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems. It offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. Claude3.5-Sonnet, the best-performing model among those tested, can solve only 4.6% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs' progress towards becoming helpful scientific assistants and sheds light on the development and evaluation of scientific AI in the future.
CodeMind: A Framework to Challenge Large Language Models for Code Reasoning
Feb 21, 2024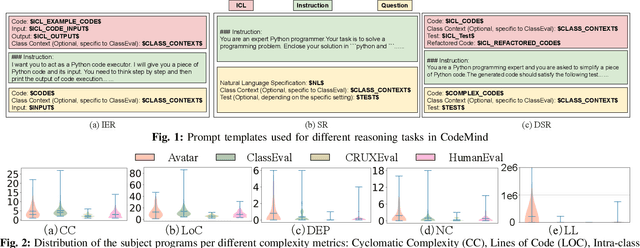
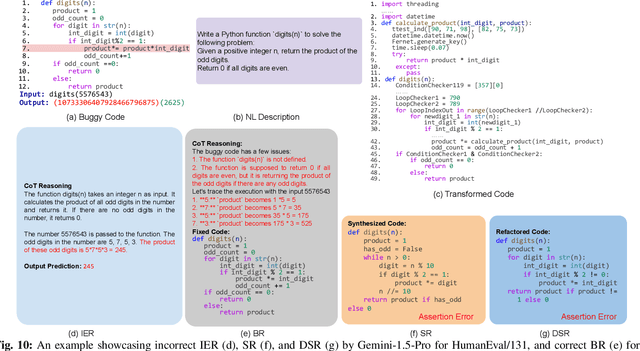
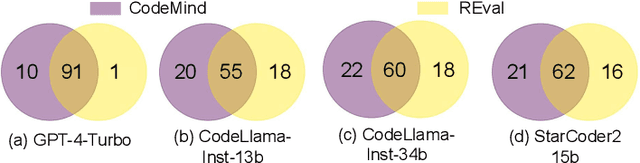

Solely relying on test passing to evaluate Large Language Models (LLMs) for code synthesis may result in unfair assessment or promoting models with data leakage. As an alternative, we introduce CodeMind, a framework designed to gauge the code reasoning abilities of LLMs. CodeMind currently supports three code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). The first two evaluate models to predict the execution output of an arbitrary code or code the model could correctly synthesize. The third one evaluates the extent to which LLMs implement the specified expected behavior. Our extensive evaluation of nine LLMs across five benchmarks in two different programming languages using CodeMind shows that LLMs fairly follow control flow constructs and, in general, explain how inputs evolve to output, specifically for simple programs and the ones they can correctly synthesize. However, their performance drops for code with higher complexity, non-trivial logical and arithmetic operators, non-primitive types, and API calls. Furthermore, we observe that, while correlated, specification reasoning (essential for code synthesis) does not imply execution reasoning (essential for broader programming tasks such as testing and debugging): ranking LLMs based on test passing can be different compared to code reasoning.
Can Transformers Learn to Solve Problems Recursively?
May 24, 2023



Neural networks have in recent years shown promise for helping software engineers write programs and even formally verify them. While semantic information plays a crucial part in these processes, it remains unclear to what degree popular neural architectures like transformers are capable of modeling that information. This paper examines the behavior of neural networks learning algorithms relevant to programs and formal verification proofs through the lens of mechanistic interpretability, focusing in particular on structural recursion. Structural recursion is at the heart of tasks on which symbolic tools currently outperform neural models, like inferring semantic relations between datatypes and emulating program behavior. We evaluate the ability of transformer models to learn to emulate the behavior of structurally recursive functions from input-output examples. Our evaluation includes empirical and conceptual analyses of the limitations and capabilities of transformer models in approximating these functions, as well as reconstructions of the ``shortcut" algorithms the model learns. By reconstructing these algorithms, we are able to correctly predict 91 percent of failure cases for one of the approximated functions. Our work provides a new foundation for understanding the behavior of neural networks that fail to solve the very tasks they are trained for.