 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Search in the Wild: Intents and Trajectory Dynamics from 14M+ Real Search Requests
Jan 24, 2026LLM-powered search agents are increasingly being used for multi-step information seeking tasks, yet the IR community lacks empirical understanding of how agentic search sessions unfold and how retrieved evidence is used. This paper presents a large-scale log analysis of agentic search based on 14.44M search requests (3.97M sessions) collected from DeepResearchGym, i.e. an open-source search API accessed by external agentic clients. We sessionize the logs, assign session-level intents and step-wise query-reformulation labels using LLM-based annotation, and propose Context-driven Term Adoption Rate (CTAR) to quantify whether newly introduced query terms are traceable to previously retrieved evidence. Our analyses reveal distinctive behavioral patterns. First, over 90% of multi-turn sessions contain at most ten steps, and 89% of inter-step intervals fall under one minute. Second, behavior varies by intent. Fact-seeking sessions exhibit high repetition that increases over time, while sessions requiring reasoning sustain broader exploration. Third, agents reuse evidence across steps. On average, 54% of newly introduced query terms appear in the accumulated evidence context, with contributions from earlier steps beyond the most recent retrieval. The findings suggest that agentic search may benefit from repetition-aware early stopping, intent-adaptive retrieval budgets, and explicit cross-step context tracking. We plan to release the anonymized logs to support future research.
DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
May 25, 2025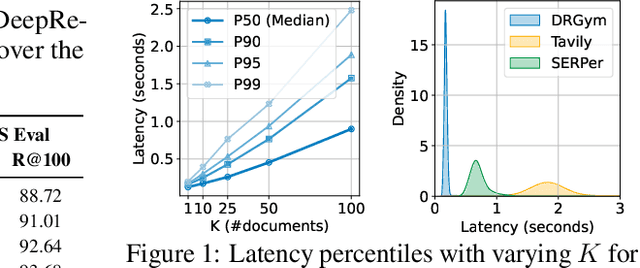
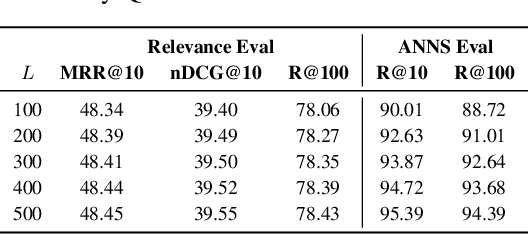
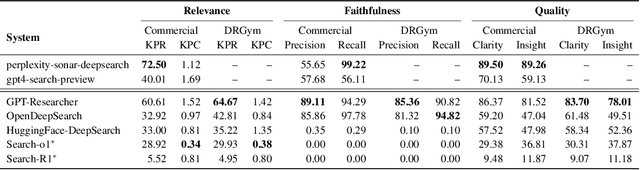
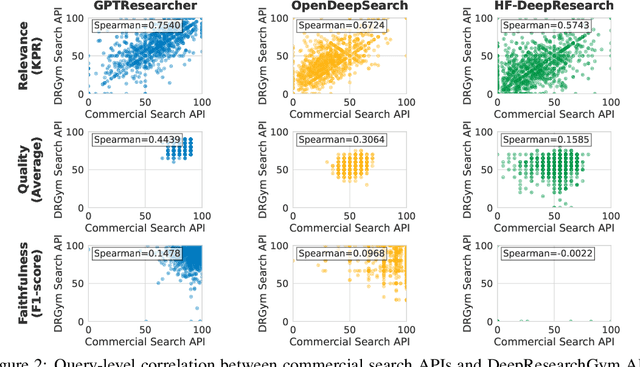
Deep research systems represent an emerging class of agentic information retrieval methods that generate comprehensive and well-supported reports to complex queries. However, most existing frameworks rely on dynamic commercial search APIs, which pose reproducibility and transparency challenges in addition to their cost. To address these limitations, we introduce DeepResearchGym, an open-source sandbox that combines a reproducible search API with a rigorous evaluation protocol for benchmarking deep research systems. The API indexes large-scale public web corpora, namely ClueWeb22 and FineWeb, using a state-of-the-art dense retriever and approximate nearest neighbor search via DiskANN. It achieves lower latency than popular commercial APIs while ensuring stable document rankings across runs, and is freely available for research use. To evaluate deep research systems' outputs, we extend the Researchy Questions benchmark with automatic metrics through LLM-as-a-judge assessments to measure alignment with users' information needs, retrieval faithfulness, and report quality. Experimental results show that systems integrated with DeepResearchGym achieve performance comparable to those using commercial APIs, with performance rankings remaining consistent across evaluation metrics. A human evaluation study further confirms that our automatic protocol aligns with human preferences, validating the framework's ability to help support controlled assessment of deep research systems. Our code and API documentation are available at https://www.deepresearchgym.ai.
Tevatron 2.0: Unified Document Retrieval Toolkit across Scale, Language, and Modality
May 05, 2025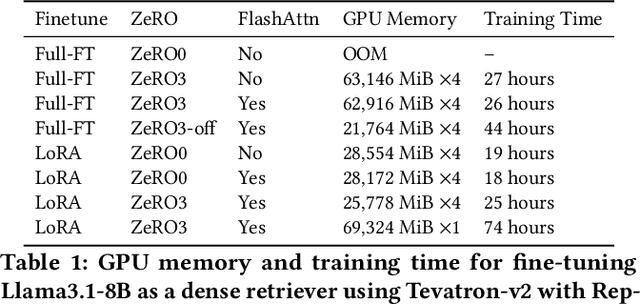
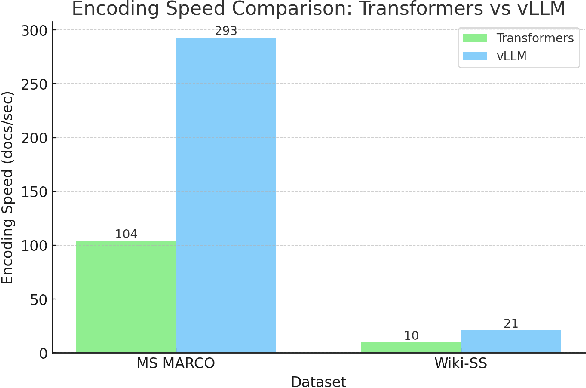
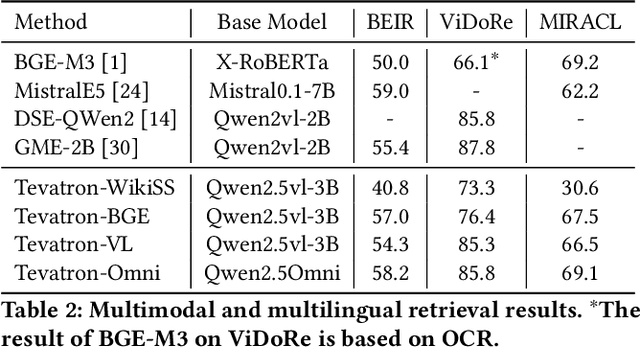

Recent advancements in large language models (LLMs) have driven interest in billion-scale retrieval models with strong generalization across retrieval tasks and languages. Additionally, progress in large vision-language models has created new opportunities for multimodal retrieval. In response, we have updated the Tevatron toolkit, introducing a unified pipeline that enables researchers to explore retriever models at different scales, across multiple languages, and with various modalities. This demo paper highlights the toolkit's key features, bridging academia and industry by supporting efficient training, inference, and evaluation of neural retrievers. We showcase a unified dense retriever achieving strong multilingual and multimodal effectiveness, and conduct a cross-modality zero-shot study to demonstrate its research potential. Alongside, we release OmniEmbed, to the best of our knowledge, the first embedding model that unifies text, image document, video, and audio retrieval, serving as a baseline for future research.
Repository-level Code Search with Neural Retrieval Methods
Feb 10, 2025
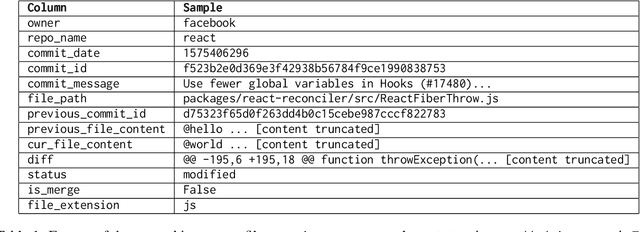
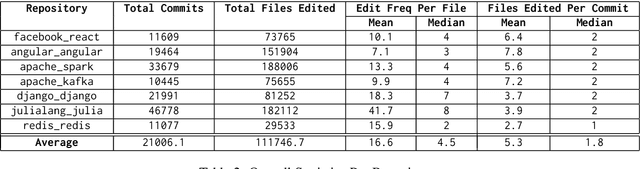

This paper presents a multi-stage reranking system for repository-level code search, which leverages the vastly available commit histories of large open-source repositories to aid in bug fixing. We define the task of repository-level code search as retrieving the set of files from the current state of a code repository that are most relevant to addressing a user's question or bug. The proposed approach combines BM25-based retrieval over commit messages with neural reranking using CodeBERT to identify the most pertinent files. By learning patterns from diverse repositories and their commit histories, the system can surface relevant files for the task at hand. The system leverages both commit messages and source code for relevance matching, and is evaluated in both normal and oracle settings. Experiments on a new dataset created from 7 popular open-source repositories demonstrate substantial improvements of up to 80% in MAP, MRR and P@1 over the BM25 baseline, across a diverse set of queries, demonstrating the effectiveness this approach. We hope this work aids LLM agents as a tool for better code search and understanding. Our code and results obtained are publicly available.
ACER: Automatic Language Model Context Extension via Retrieval
Oct 11, 2024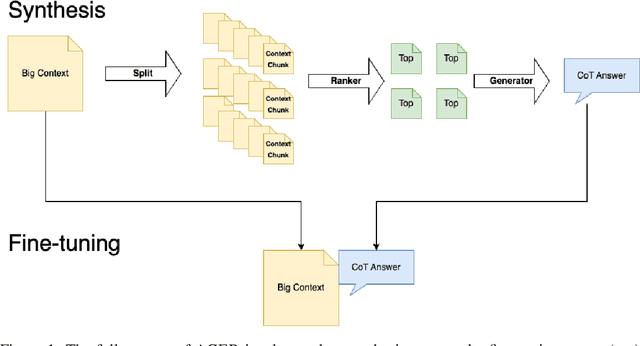
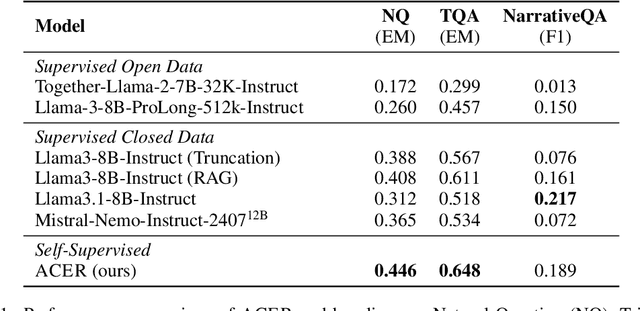

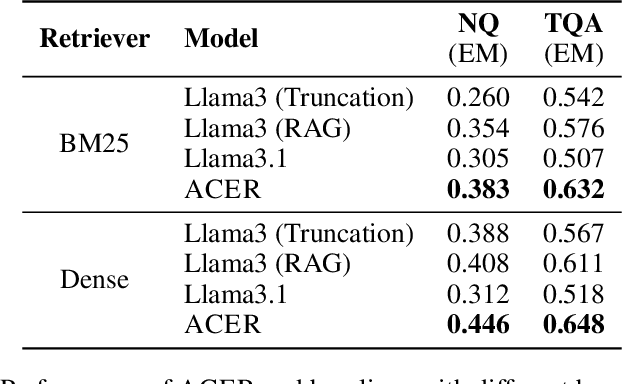
Long-context modeling is one of the critical capabilities of language AI for digesting and reasoning over complex information pieces. In practice, long-context capabilities are typically built into a pre-trained language model~(LM) through a carefully designed context extension stage, with the goal of producing generalist long-context capabilities. In our preliminary experiments, however, we discovered that the current open-weight generalist long-context models are still lacking in practical long-context processing tasks. While this means perfectly effective long-context modeling demands task-specific data, the cost can be prohibitive. In this paper, we draw inspiration from how humans process a large body of information: a lossy \textbf{retrieval} stage ranks a large set of documents while the reader ends up reading deeply only the top candidates. We build an \textbf{automatic} data synthesis pipeline that mimics this process using short-context LMs. The short-context LMs are further tuned using these self-generated data to obtain task-specific long-context capabilities. Similar to how pre-training learns from imperfect data, we hypothesize and further demonstrate that the short-context model can bootstrap over the synthetic data, outperforming not only long-context generalist models but also the retrieval and read pipeline used to synthesize the training data in real-world tasks such as long-context retrieval augmented generation.
SciCode: A Research Coding Benchmark Curated by Scientists
Jul 18, 2024



Since language models (LMs) now outperform average humans on many challenging tasks, it has become increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this issue by examining LMs' capabilities to generate code for solving real scientific research problems. Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we created a scientist-curated coding benchmark, SciCode. The problems in SciCode naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems. It offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. Claude3.5-Sonnet, the best-performing model among those tested, can solve only 4.6% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs' progress towards becoming helpful scientific assistants and sheds light on the development and evaluation of scientific AI in the future.
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval
Apr 05, 2024



This study investigates the existence of positional biases in Transformer-based models for text representation learning, particularly in the context of web document retrieval. We build on previous research that demonstrated loss of information in the middle of input sequences for causal language models, extending it to the domain of representation learning. We examine positional biases at various stages of training for an encoder-decoder model, including language model pre-training, contrastive pre-training, and contrastive fine-tuning. Experiments with the MS-MARCO document collection reveal that after contrastive pre-training the model already generates embeddings that better capture early contents of the input, with fine-tuning further aggravating this effect.
Building Retrieval Systems for the ClueWeb22-B Corpus
Feb 06, 2024The ClueWeb22 dataset containing nearly 10 billion documents was released in 2022 to support academic and industry research. The goal of this project was to build retrieval baselines for the English section of the "super head" part (category B) of this dataset. These baselines can then be used by the research community to compare their systems and also to generate data to train/evaluate new retrieval and ranking algorithms. The report covers sparse and dense first stage retrievals as well as neural rerankers that were implemented for this dataset. These systems are available as a service on a Carnegie Mellon University cluster.
Active Retrieval Augmented Generation
May 11, 2023

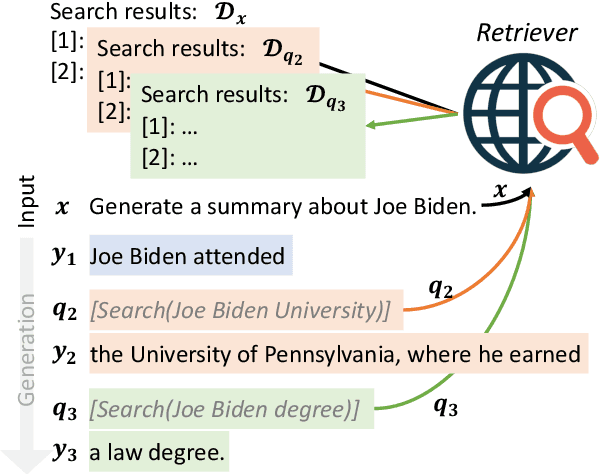

Despite the remarkable ability of large language models (LMs) to comprehend and generate language, they have a tendency to hallucinate and create factually inaccurate output. Augmenting LMs by retrieving information from external knowledge resources is one promising solution. Most existing retrieval-augmented LMs employ a retrieve-and-generate setup that only retrieves information once based on the input. This is limiting, however, in more general scenarios involving generation of long texts, where continually gathering information throughout the generation process is essential. There have been some past efforts to retrieve information multiple times while generating outputs, which mostly retrieve documents at fixed intervals using the previous context as queries. In this work, we provide a generalized view of active retrieval augmented generation, methods that actively decide when and what to retrieve across the course of the generation. We propose Forward-Looking Active REtrieval augmented generation (FLARE), a generic retrieval-augmented generation method which iteratively uses a prediction of the upcoming sentence to anticipate future content, which is then utilized as a query to retrieve relevant documents to regenerate the sentence if it contains low-confidence tokens. We test FLARE along with baselines comprehensively over 4 long-form knowledge-intensive generation tasks/datasets. FLARE achieves superior or competitive performance on all tasks, demonstrating the effectiveness of our method. Code and datasets are available at https://github.com/jzbjyb/FLARE.
Precise Zero-Shot Dense Retrieval without Relevance Labels
Dec 20, 2022



While dense retrieval has been shown effective and efficient across tasks and languages, it remains difficult to create effective fully zero-shot dense retrieval systems when no relevance label is available. In this paper, we recognize the difficulty of zero-shot learning and encoding relevance. Instead, we propose to pivot through Hypothetical Document Embeddings~(HyDE). Given a query, HyDE first zero-shot instructs an instruction-following language model (e.g. InstructGPT) to generate a hypothetical document. The document captures relevance patterns but is unreal and may contain false details. Then, an unsupervised contrastively learned encoder~(e.g. Contriever) encodes the document into an embedding vector. This vector identifies a neighborhood in the corpus embedding space, where similar real documents are retrieved based on vector similarity. This second step ground the generated document to the actual corpus, with the encoder's dense bottleneck filtering out the incorrect details. Our experiments show that HyDE significantly outperforms the state-of-the-art unsupervised dense retriever Contriever and shows strong performance comparable to fine-tuned retrievers, across various tasks (e.g. web search, QA, fact verification) and languages~(e.g. sw, ko, ja).