 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Search in the Wild: Intents and Trajectory Dynamics from 14M+ Real Search Requests
Jan 24, 2026LLM-powered search agents are increasingly being used for multi-step information seeking tasks, yet the IR community lacks empirical understanding of how agentic search sessions unfold and how retrieved evidence is used. This paper presents a large-scale log analysis of agentic search based on 14.44M search requests (3.97M sessions) collected from DeepResearchGym, i.e. an open-source search API accessed by external agentic clients. We sessionize the logs, assign session-level intents and step-wise query-reformulation labels using LLM-based annotation, and propose Context-driven Term Adoption Rate (CTAR) to quantify whether newly introduced query terms are traceable to previously retrieved evidence. Our analyses reveal distinctive behavioral patterns. First, over 90% of multi-turn sessions contain at most ten steps, and 89% of inter-step intervals fall under one minute. Second, behavior varies by intent. Fact-seeking sessions exhibit high repetition that increases over time, while sessions requiring reasoning sustain broader exploration. Third, agents reuse evidence across steps. On average, 54% of newly introduced query terms appear in the accumulated evidence context, with contributions from earlier steps beyond the most recent retrieval. The findings suggest that agentic search may benefit from repetition-aware early stopping, intent-adaptive retrieval budgets, and explicit cross-step context tracking. We plan to release the anonymized logs to support future research.
Aligning Web Query Generation with Ranking Objectives via Direct Preference Optimization
May 25, 2025Neural retrieval models excel in Web search, but their training requires substantial amounts of labeled query-document pairs, which are costly to obtain. With the widespread availability of Web document collections like ClueWeb22, synthetic queries generated by large language models offer a scalable alternative. Still, synthetic training queries often vary in quality, which leads to suboptimal downstream retrieval performance. Existing methods typically filter out noisy query-document pairs based on signals from an external re-ranker. In contrast, we propose a framework that leverages Direct Preference Optimization (DPO) to integrate ranking signals into the query generation process, aiming to directly optimize the model towards generating high-quality queries that maximize downstream retrieval effectiveness. Experiments show higher ranker-assessed relevance between query-document pairs after DPO, leading to stronger downstream performance on the MS~MARCO benchmark when compared to baseline models trained with synthetic data.
DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
May 25, 2025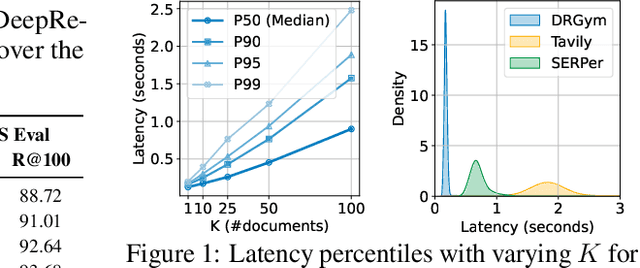
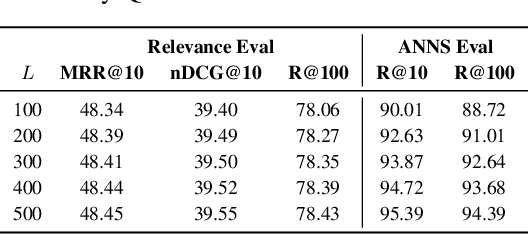
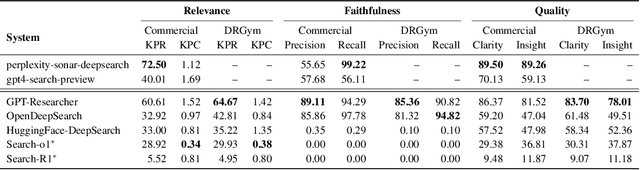
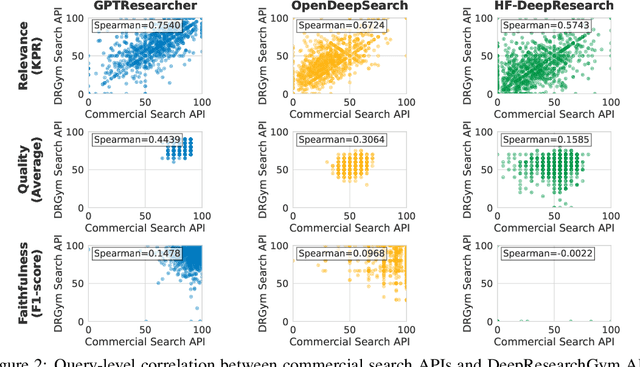
Deep research systems represent an emerging class of agentic information retrieval methods that generate comprehensive and well-supported reports to complex queries. However, most existing frameworks rely on dynamic commercial search APIs, which pose reproducibility and transparency challenges in addition to their cost. To address these limitations, we introduce DeepResearchGym, an open-source sandbox that combines a reproducible search API with a rigorous evaluation protocol for benchmarking deep research systems. The API indexes large-scale public web corpora, namely ClueWeb22 and FineWeb, using a state-of-the-art dense retriever and approximate nearest neighbor search via DiskANN. It achieves lower latency than popular commercial APIs while ensuring stable document rankings across runs, and is freely available for research use. To evaluate deep research systems' outputs, we extend the Researchy Questions benchmark with automatic metrics through LLM-as-a-judge assessments to measure alignment with users' information needs, retrieval faithfulness, and report quality. Experimental results show that systems integrated with DeepResearchGym achieve performance comparable to those using commercial APIs, with performance rankings remaining consistent across evaluation metrics. A human evaluation study further confirms that our automatic protocol aligns with human preferences, validating the framework's ability to help support controlled assessment of deep research systems. Our code and API documentation are available at https://www.deepresearchgym.ai.
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval
Apr 05, 2024



This study investigates the existence of positional biases in Transformer-based models for text representation learning, particularly in the context of web document retrieval. We build on previous research that demonstrated loss of information in the middle of input sequences for causal language models, extending it to the domain of representation learning. We examine positional biases at various stages of training for an encoder-decoder model, including language model pre-training, contrastive pre-training, and contrastive fine-tuning. Experiments with the MS-MARCO document collection reveal that after contrastive pre-training the model already generates embeddings that better capture early contents of the input, with fine-tuning further aggravating this effect.