 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORBIT -- Open Recommendation Benchmark for Reproducible Research with Hidden Tests
Oct 30, 2025Recommender systems are among the most impactful AI applications, interacting with billions of users every day, guiding them to relevant products, services, or information tailored to their preferences. However, the research and development of recommender systems are hindered by existing datasets that fail to capture realistic user behaviors and inconsistent evaluation settings that lead to ambiguous conclusions. This paper introduces the Open Recommendation Benchmark for Reproducible Research with HIdden Tests (ORBIT), a unified benchmark for consistent and realistic evaluation of recommendation models. ORBIT offers a standardized evaluation framework of public datasets with reproducible splits and transparent settings for its public leaderboard. Additionally, ORBIT introduces a new webpage recommendation task, ClueWeb-Reco, featuring web browsing sequences from 87 million public, high-quality webpages. ClueWeb-Reco is a synthetic dataset derived from real, user-consented, and privacy-guaranteed browsing data. It aligns with modern recommendation scenarios and is reserved as the hidden test part of our leaderboard to challenge recommendation models' generalization ability. ORBIT measures 12 representative recommendation models on its public benchmark and introduces a prompted LLM baseline on the ClueWeb-Reco hidden test. Our benchmark results reflect general improvements of recommender systems on the public datasets, with variable individual performances. The results on the hidden test reveal the limitations of existing approaches in large-scale webpage recommendation and highlight the potential for improvements with LLM integrations. ORBIT benchmark, leaderboard, and codebase are available at https://www.open-reco-bench.ai.
DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
May 25, 2025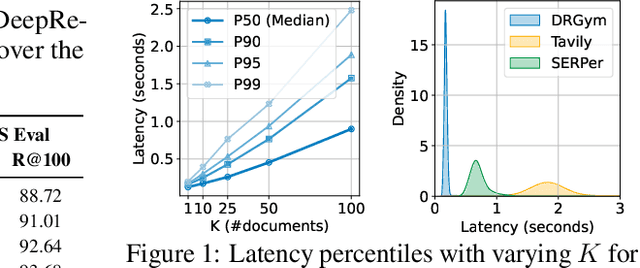
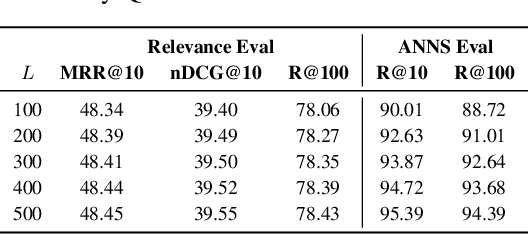
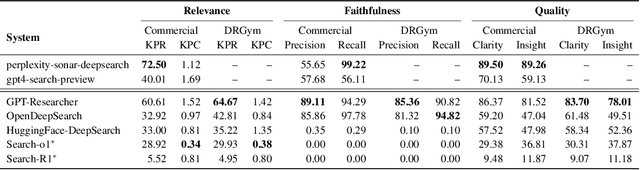
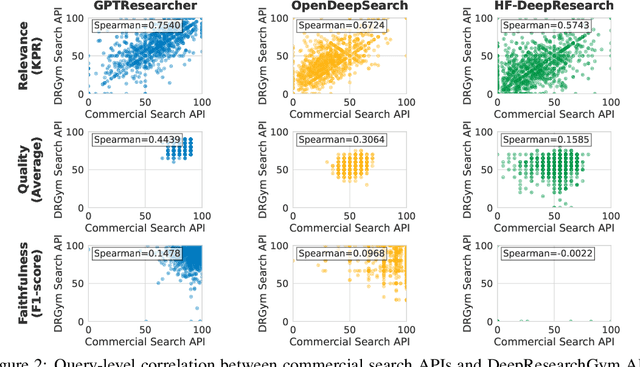
Deep research systems represent an emerging class of agentic information retrieval methods that generate comprehensive and well-supported reports to complex queries. However, most existing frameworks rely on dynamic commercial search APIs, which pose reproducibility and transparency challenges in addition to their cost. To address these limitations, we introduce DeepResearchGym, an open-source sandbox that combines a reproducible search API with a rigorous evaluation protocol for benchmarking deep research systems. The API indexes large-scale public web corpora, namely ClueWeb22 and FineWeb, using a state-of-the-art dense retriever and approximate nearest neighbor search via DiskANN. It achieves lower latency than popular commercial APIs while ensuring stable document rankings across runs, and is freely available for research use. To evaluate deep research systems' outputs, we extend the Researchy Questions benchmark with automatic metrics through LLM-as-a-judge assessments to measure alignment with users' information needs, retrieval faithfulness, and report quality. Experimental results show that systems integrated with DeepResearchGym achieve performance comparable to those using commercial APIs, with performance rankings remaining consistent across evaluation metrics. A human evaluation study further confirms that our automatic protocol aligns with human preferences, validating the framework's ability to help support controlled assessment of deep research systems. Our code and API documentation are available at https://www.deepresearchgym.ai.
MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding
Jun 20, 2024The advent of large vision-language models (LVLMs) has spurred research into their applications in multi-modal contexts, particularly in video understanding. Traditional VideoQA benchmarks, despite providing quantitative metrics, often fail to encompass the full spectrum of video content and inadequately assess models' temporal comprehension. To address these limitations, we introduce MMBench-Video, a quantitative benchmark designed to rigorously evaluate LVLMs' proficiency in video understanding. MMBench-Video incorporates lengthy videos from YouTube and employs free-form questions, mirroring practical use cases. The benchmark is meticulously crafted to probe the models' temporal reasoning skills, with all questions human-annotated according to a carefully constructed ability taxonomy. We employ GPT-4 for automated assessment, demonstrating superior accuracy and robustness over earlier LLM-based evaluations. Utilizing MMBench-Video, we have conducted comprehensive evaluations that include both proprietary and open-source LVLMs for images and videos. MMBench-Video stands as a valuable resource for the research community, facilitating improved evaluation of LVLMs and catalyzing progress in the field of video understanding. The evalutation code of MMBench-Video will be integrated into VLMEvalKit: https://github.com/open-compass/VLMEvalKit.
OAKINK2: A Dataset of Bimanual Hands-Object Manipulation in Complex Task Completion
Mar 28, 2024



We present OAKINK2, a dataset of bimanual object manipulation tasks for complex daily activities. In pursuit of constructing the complex tasks into a structured representation, OAKINK2 introduces three level of abstraction to organize the manipulation tasks: Affordance, Primitive Task, and Complex Task. OAKINK2 features on an object-centric perspective for decoding the complex tasks, treating them as a sequence of object affordance fulfillment. The first level, Affordance, outlines the functionalities that objects in the scene can afford, the second level, Primitive Task, describes the minimal interaction units that humans interact with the object to achieve its affordance, and the third level, Complex Task, illustrates how Primitive Tasks are composed and interdependent. OAKINK2 dataset provides multi-view image streams and precise pose annotations for the human body, hands and various interacting objects. This extensive collection supports applications such as interaction reconstruction and motion synthesis. Based on the 3-level abstraction of OAKINK2, we explore a task-oriented framework for Complex Task Completion (CTC). CTC aims to generate a sequence of bimanual manipulation to achieve task objectives. Within the CTC framework, we employ Large Language Models (LLMs) to decompose the complex task objectives into sequences of Primitive Tasks and have developed a Motion Fulfillment Model that generates bimanual hand motion for each Primitive Task. OAKINK2 datasets and models are available at https://oakink.net/v2.