 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniCam: Unified Multimodal Video Generation via Camera Control
Apr 03, 2025



Camera control, which achieves diverse visual effects by changing camera position and pose, has attracted widespread attention. However, existing methods face challenges such as complex interaction and limited control capabilities. To address these issues, we present OmniCam, a unified multimodal camera control framework. Leveraging large language models and video diffusion models, OmniCam generates spatio-temporally consistent videos. It supports various combinations of input modalities: the user can provide text or video with expected trajectory as camera path guidance, and image or video as content reference, enabling precise control over camera motion. To facilitate the training of OmniCam, we introduce the OmniTr dataset, which contains a large collection of high-quality long-sequence trajectories, videos, and corresponding descriptions. Experimental results demonstrate that our model achieves state-of-the-art performance in high-quality camera-controlled video generation across various metrics.
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
Mar 05, 2025Scaling up imitation learning for real-world applications requires efficient and cost-effective demonstration collection methods. Current teleoperation approaches, though effective, are expensive and inefficient due to the dependency on physical robot platforms. Alternative data sources like in-the-wild demonstrations can eliminate the need for physical robots and offer more scalable solutions. However, existing in-the-wild data collection devices have limitations: handheld devices offer restricted in-hand camera observation, while whole-body devices often require fine-tuning with robot data due to action inaccuracies. In this paper, we propose AirExo-2, a low-cost exoskeleton system for large-scale in-the-wild demonstration collection. By introducing the demonstration adaptor to transform the collected in-the-wild demonstrations into pseudo-robot demonstrations, our system addresses key challenges in utilizing in-the-wild demonstrations for downstream imitation learning in real-world environments. Additionally, we present RISE-2, a generalizable policy that integrates 2D and 3D perceptions, outperforming previous imitation learning policies in both in-domain and out-of-domain tasks, even with limited demonstrations. By leveraging in-the-wild demonstrations collected and transformed by the AirExo-2 system, without the need for additional robot demonstrations, RISE-2 achieves comparable or superior performance to policies trained with teleoperated data, highlighting the potential of AirExo-2 for scalable and generalizable imitation learning. Project page: https://airexo.tech/airexo2
Motion Before Action: Diffusing Object Motion as Manipulation Condition
Nov 14, 2024



Inferring object motion representations from observations enhances the performance of robotic manipulation tasks. This paper introduces a new paradigm for robot imitation learning that generates action sequences by reasoning about object motion from visual observations. We propose MBA (Motion Before Action), a novel module that employs two cascaded diffusion processes for object motion generation and robot action generation under object motion guidance. MBA first predicts the future pose sequence of the object based on observations, then uses this sequence as a condition to guide robot action generation. Designed as a plug-and-play component, MBA can be flexibly integrated into existing robotic manipulation policies with diffusion action heads. Extensive experiments in both simulated and real-world environments demonstrate that our approach substantially improves the performance of existing policies across a wide range of manipulation tasks.
Multi-view Hand Reconstruction with a Point-Embedded Transformer
Aug 20, 2024



This work introduces a novel and generalizable multi-view Hand Mesh Reconstruction (HMR) model, named POEM, designed for practical use in real-world hand motion capture scenarios. The advances of the POEM model consist of two main aspects. First, concerning the modeling of the problem, we propose embedding a static basis point within the multi-view stereo space. A point represents a natural form of 3D information and serves as an ideal medium for fusing features across different views, given its varied projections across these views. Consequently, our method harnesses a simple yet effective idea: a complex 3D hand mesh can be represented by a set of 3D basis points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encompass the hand in it. The second advance lies in the training strategy. We utilize a combination of five large-scale multi-view datasets and employ randomization in the number, order, and poses of the cameras. By processing such a vast amount of data and a diverse array of camera configurations, our model demonstrates notable generalizability in the real-world applications. As a result, POEM presents a highly practical, plug-and-play solution that enables user-friendly, cost-effective multi-view motion capture for both left and right hands. The model and source codes are available at https://github.com/JubSteven/POEM-v2.
OAKINK2: A Dataset of Bimanual Hands-Object Manipulation in Complex Task Completion
Mar 28, 2024



We present OAKINK2, a dataset of bimanual object manipulation tasks for complex daily activities. In pursuit of constructing the complex tasks into a structured representation, OAKINK2 introduces three level of abstraction to organize the manipulation tasks: Affordance, Primitive Task, and Complex Task. OAKINK2 features on an object-centric perspective for decoding the complex tasks, treating them as a sequence of object affordance fulfillment. The first level, Affordance, outlines the functionalities that objects in the scene can afford, the second level, Primitive Task, describes the minimal interaction units that humans interact with the object to achieve its affordance, and the third level, Complex Task, illustrates how Primitive Tasks are composed and interdependent. OAKINK2 dataset provides multi-view image streams and precise pose annotations for the human body, hands and various interacting objects. This extensive collection supports applications such as interaction reconstruction and motion synthesis. Based on the 3-level abstraction of OAKINK2, we explore a task-oriented framework for Complex Task Completion (CTC). CTC aims to generate a sequence of bimanual manipulation to achieve task objectives. Within the CTC framework, we employ Large Language Models (LLMs) to decompose the complex task objectives into sequences of Primitive Tasks and have developed a Motion Fulfillment Model that generates bimanual hand motion for each Primitive Task. OAKINK2 datasets and models are available at https://oakink.net/v2.
CHORD: Category-level Hand-held Object Reconstruction via Shape Deformation
Aug 21, 2023



In daily life, humans utilize hands to manipulate objects. Modeling the shape of objects that are manipulated by the hand is essential for AI to comprehend daily tasks and to learn manipulation skills. However, previous approaches have encountered difficulties in reconstructing the precise shapes of hand-held objects, primarily owing to a deficiency in prior shape knowledge and inadequate data for training. As illustrated, given a particular type of tool, such as a mug, despite its infinite variations in shape and appearance, humans have a limited number of 'effective' modes and poses for its manipulation. This can be attributed to the fact that humans have mastered the shape prior of the 'mug' category, and can quickly establish the corresponding relations between different mug instances and the prior, such as where the rim and handle are located. In light of this, we propose a new method, CHORD, for Category-level Hand-held Object Reconstruction via shape Deformation. CHORD deforms a categorical shape prior for reconstructing the intra-class objects. To ensure accurate reconstruction, we empower CHORD with three types of awareness: appearance, shape, and interacting pose. In addition, we have constructed a new dataset, COMIC, of category-level hand-object interaction. COMIC contains a rich array of object instances, materials, hand interactions, and viewing directions. Extensive evaluation shows that CHORD outperforms state-of-the-art approaches in both quantitative and qualitative measures. Code, model, and datasets are available at https://kailinli.github.io/CHORD.
POEM: Reconstructing Hand in a Point Embedded Multi-view Stereo
Apr 08, 2023



Enable neural networks to capture 3D geometrical-aware features is essential in multi-view based vision tasks. Previous methods usually encode the 3D information of multi-view stereo into the 2D features. In contrast, we present a novel method, named POEM, that directly operates on the 3D POints Embedded in the Multi-view stereo for reconstructing hand mesh in it. Point is a natural form of 3D information and an ideal medium for fusing features across views, as it has different projections on different views. Our method is thus in light of a simple yet effective idea, that a complex 3D hand mesh can be represented by a set of 3D points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encircle the hand. To leverage the power of points, we design two operations: point-based feature fusion and cross-set point attention mechanism. Evaluation on three challenging multi-view datasets shows that POEM outperforms the state-of-the-art in hand mesh reconstruction. Code and models are available for research at https://github.com/lixiny/POEM.
OakInk: A Large-scale Knowledge Repository for Understanding Hand-Object Interaction
Mar 29, 2022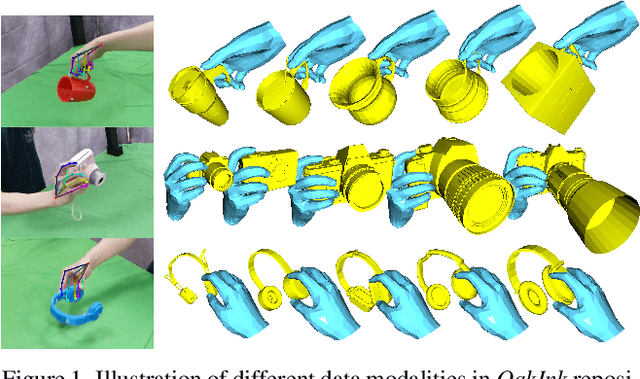
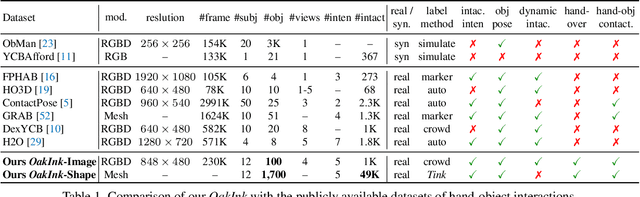
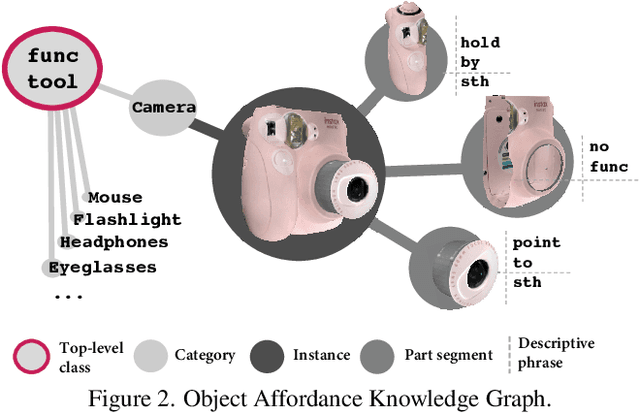
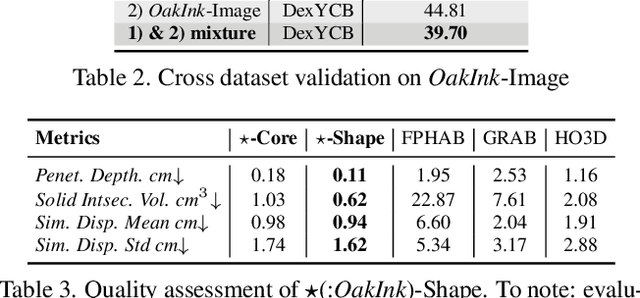
Learning how humans manipulate objects requires machines to acquire knowledge from two perspectives: one for understanding object affordances and the other for learning human's interactions based on the affordances. Even though these two knowledge bases are crucial, we find that current databases lack a comprehensive awareness of them. In this work, we propose a multi-modal and rich-annotated knowledge repository, OakInk, for visual and cognitive understanding of hand-object interactions. We start to collect 1,800 common household objects and annotate their affordances to construct the first knowledge base: Oak. Given the affordance, we record rich human interactions with 100 selected objects in Oak. Finally, we transfer the interactions on the 100 recorded objects to their virtual counterparts through a novel method: Tink. The recorded and transferred hand-object interactions constitute the second knowledge base: Ink. As a result, OakInk contains 50,000 distinct affordance-aware and intent-oriented hand-object interactions. We benchmark OakInk on pose estimation and grasp generation tasks. Moreover, we propose two practical applications of OakInk: intent-based interaction generation and handover generation. Our datasets and source code are publicly available at https://github.com/lixiny/OakInk.
ArtiBoost: Boosting Articulated 3D Hand-Object Pose Estimation via Online Exploration and Synthesis
Sep 12, 2021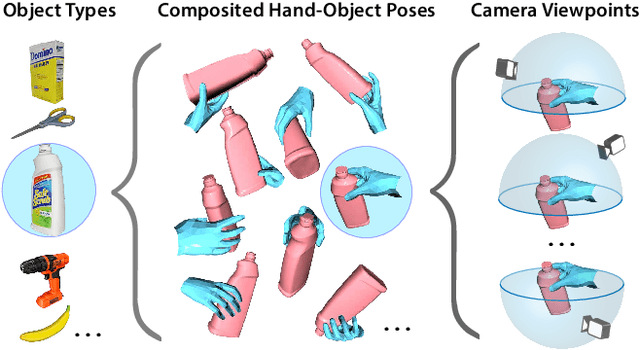
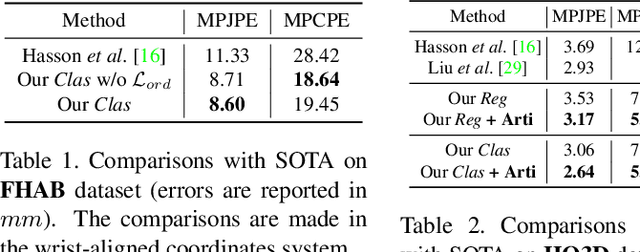
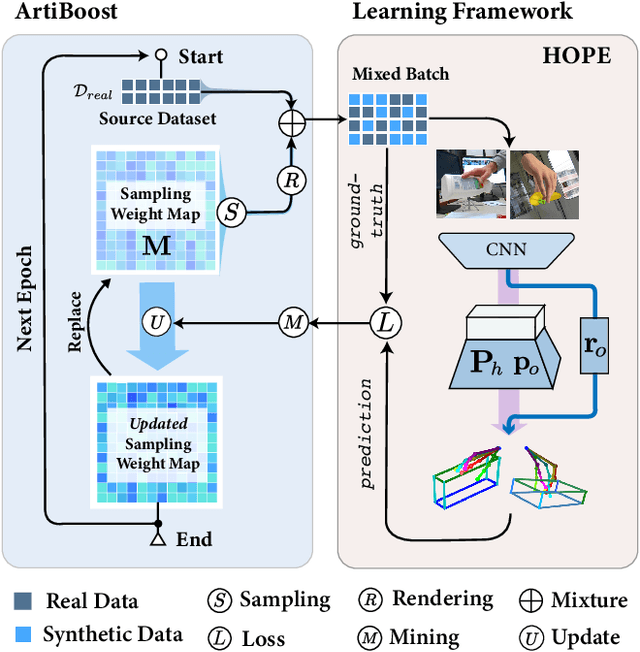
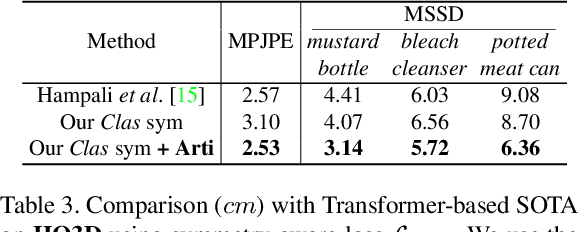
Estimating the articulated 3D hand-object pose from a single RGB image is a highly ambiguous and challenging problem requiring large-scale datasets that contain diverse hand poses, object poses, and camera viewpoints. Most real-world datasets lack this diversity. In contrast, synthetic datasets can easily ensure vast diversity, but learning from them is inefficient and suffers from heavy training consumption. To address the above issues, we propose ArtiBoost, a lightweight online data enrichment method that boosts articulated hand-object pose estimation from the data perspective. ArtiBoost is employed along with a real-world source dataset. During training, ArtiBoost alternatively performs data exploration and synthesis. ArtiBoost can cover various hand-object poses and camera viewpoints based on a Compositional hand-object Configuration and Viewpoint space (CCV-space) and can adaptively enrich the current hard-discernable samples by a mining strategy. We apply ArtiBoost on a simple learning baseline network and demonstrate the performance boost on several hand-object benchmarks. As an illustrative example, with ArtiBoost, even a simple baseline network can outperform the previous start-of-the-art based on Transformer on the HO3D dataset. Our code is available at https://github.com/MVIG-SJTU/ArtiBoost.