 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtiBoost: Boosting Articulated 3D Hand-Object Pose Estimation via Online Exploration and Synthesis
Paper and Code
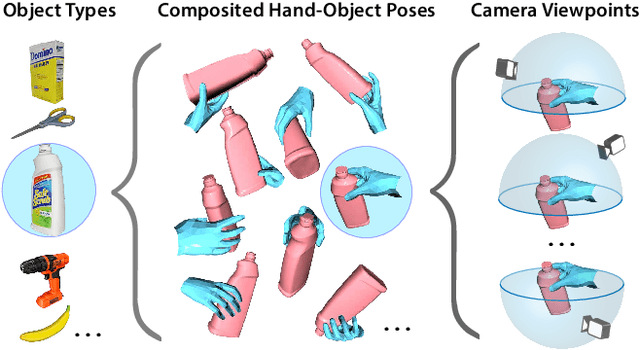
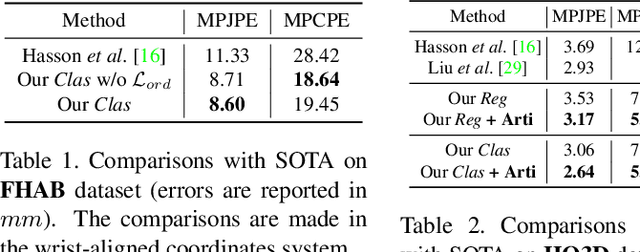
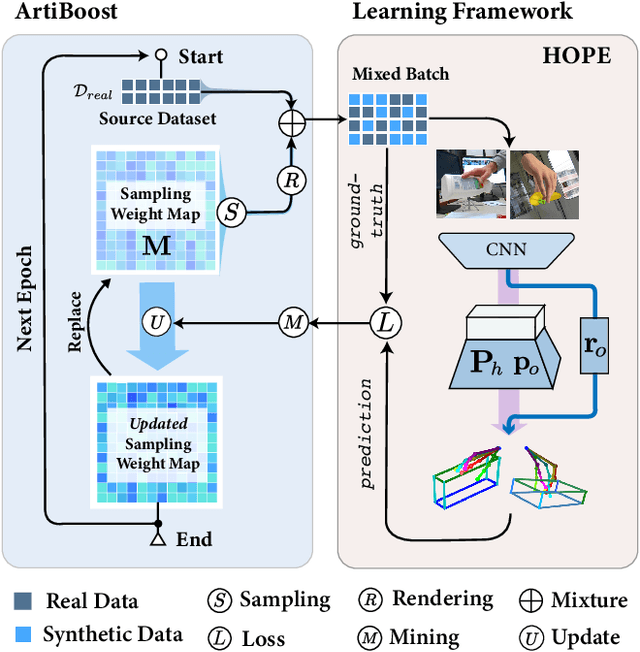
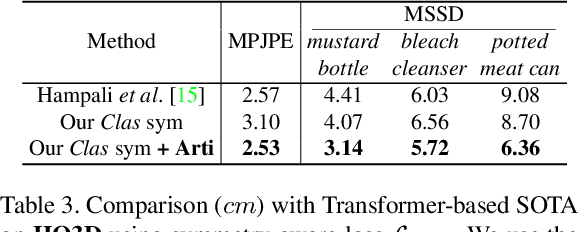
Estimating the articulated 3D hand-object pose from a single RGB image is a highly ambiguous and challenging problem requiring large-scale datasets that contain diverse hand poses, object poses, and camera viewpoints. Most real-world datasets lack this diversity. In contrast, synthetic datasets can easily ensure vast diversity, but learning from them is inefficient and suffers from heavy training consumption. To address the above issues, we propose ArtiBoost, a lightweight online data enrichment method that boosts articulated hand-object pose estimation from the data perspective. ArtiBoost is employed along with a real-world source dataset. During training, ArtiBoost alternatively performs data exploration and synthesis. ArtiBoost can cover various hand-object poses and camera viewpoints based on a Compositional hand-object Configuration and Viewpoint space (CCV-space) and can adaptively enrich the current hard-discernable samples by a mining strategy. We apply ArtiBoost on a simple learning baseline network and demonstrate the performance boost on several hand-object benchmarks. As an illustrative example, with ArtiBoost, even a simple baseline network can outperform the previous start-of-the-art based on Transformer on the HO3D dataset. Our code is available at https://github.com/MVIG-SJTU/ArtiBoost.