 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMA: Unifying Parametric Human Body Models
Mar 17, 2026Parametric human body models are foundational to human reconstruction, animation, and simulation, yet they remain mutually incompatible: SMPL, SMPL-X, MHR, Anny, and related models each diverge in mesh topology, skeletal structure, shape parameterization, and unit convention, making it impractical to exploit their complementary strengths within a single pipeline. We present SOMA, a unified body layer that bridges these heterogeneous representations through three abstraction layers. Mesh topology abstraction maps any source model's identity to a shared canonical mesh in constant time per vertex. Skeletal abstraction recovers a full set of identity-adapted joint transforms from any body shape, whether in rest pose or an arbitrary posed configuration, in a single closed-form pass, with no iterative optimization or per-model training. Pose abstraction inverts the skinning pipeline to recover unified skeleton rotations directly from posed vertices of any supported model, enabling heterogeneous motion datasets to be consumed without custom retargeting. Together, these layers reduce the $O(M^2)$ per-pair adapter problem to $O(M)$ single-backend connectors, letting practitioners freely mix identity sources and pose data at inference time. The entire pipeline is fully differentiable end-to-end and GPU-accelerated via NVIDIA-Warp.
Kimodo: Scaling Controllable Human Motion Generation
Mar 16, 2026High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
CARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction
Dec 12, 2025Accurate capture of human-object interaction from ubiquitous sensors like RGB cameras is important for applications in human understanding, gaming, and robot learning. However, inferring 4D interactions from a single RGB view is highly challenging due to the unknown object and human information, depth ambiguity, occlusion, and complex motion, which hinder consistent 3D and temporal reconstruction. Previous methods simplify the setup by assuming ground truth object template or constraining to a limited set of object categories. We present CARI4D, the first category-agnostic method that reconstructs spatially and temporarily consistent 4D human-object interaction at metric scale from monocular RGB videos. To this end, we propose a pose hypothesis selection algorithm that robustly integrates the individual predictions from foundation models, jointly refine them through a learned render-and-compare paradigm to ensure spatial, temporal and pixel alignment, and finally reasoning about intricate contacts for further refinement satisfying physical constraints. Experiments show that our method outperforms prior art by 38% on in-distribution dataset and 36% on unseen dataset in terms of reconstruction error. Our model generalizes beyond the training categories and thus can be applied zero-shot to in-the-wild internet videos. Our code and pretrained models will be publicly released.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
GENMO: A GENeralist Model for Human MOtion
May 02, 2025



Human motion modeling traditionally separates motion generation and estimation into distinct tasks with specialized models. Motion generation models focus on creating diverse, realistic motions from inputs like text, audio, or keyframes, while motion estimation models aim to reconstruct accurate motion trajectories from observations like videos. Despite sharing underlying representations of temporal dynamics and kinematics, this separation limits knowledge transfer between tasks and requires maintaining separate models. We present GENMO, a unified Generalist Model for Human Motion that bridges motion estimation and generation in a single framework. Our key insight is to reformulate motion estimation as constrained motion generation, where the output motion must precisely satisfy observed conditioning signals. Leveraging the synergy between regression and diffusion, GENMO achieves accurate global motion estimation while enabling diverse motion generation. We also introduce an estimation-guided training objective that exploits in-the-wild videos with 2D annotations and text descriptions to enhance generative diversity. Furthermore, our novel architecture handles variable-length motions and mixed multimodal conditions (text, audio, video) at different time intervals, offering flexible control. This unified approach creates synergistic benefits: generative priors improve estimated motions under challenging conditions like occlusions, while diverse video data enhances generation capabilities. Extensive experiments demonstrate GENMO's effectiveness as a generalist framework that successfully handles multiple human motion tasks within a single model.
BLADE: Single-view Body Mesh Learning through Accurate Depth Estimation
Dec 11, 2024



Single-image human mesh recovery is a challenging task due to the ill-posed nature of simultaneous body shape, pose, and camera estimation. Existing estimators work well on images taken from afar, but they break down as the person moves close to the camera. Moreover, current methods fail to achieve both accurate 3D pose and 2D alignment at the same time. Error is mainly introduced by inaccurate perspective projection heuristically derived from orthographic parameters. To resolve this long-standing challenge, we present our method BLADE which accurately recovers perspective parameters from a single image without heuristic assumptions. We start from the inverse relationship between perspective distortion and the person's Z-translation Tz, and we show that Tz can be reliably estimated from the image. We then discuss the important role of Tz for accurate human mesh recovery estimated from close-range images. Finally, we show that, once Tz and the 3D human mesh are estimated, one can accurately recover the focal length and full 3D translation. Extensive experiments on standard benchmarks and real-world close-range images show that our method is the first to accurately recover projection parameters from a single image, and consequently attain state-of-the-art accuracy on 3D pose estimation and 2D alignment for a wide range of images. https://research.nvidia.com/labs/amri/projects/blade/
From Prohibition to Adoption: How Hong Kong Universities Are Navigating ChatGPT in Academic Workflows
Oct 02, 2024This paper aims at comparing the time when Hong Kong universities used to ban ChatGPT to the current periods where it has become integrated in the academic processes. Bolted by concerns of integrity and ethical issues in technologies, institutions have adapted by moving towards the center adopting AI literacy and responsibility policies. This study examines new paradigms which have been developed to help implement these positives while preventing negative effects on academia. Keywords: ChatGPT, Academic Integrity, AI Literacy, Ethical AI Use, Generative AI in Education, University Policy, AI Integration in Academia, Higher Education and Technology
COIN: Control-Inpainting Diffusion Prior for Human and Camera Motion Estimation
Aug 29, 2024



Estimating global human motion from moving cameras is challenging due to the entanglement of human and camera motions. To mitigate the ambiguity, existing methods leverage learned human motion priors, which however often result in oversmoothed motions with misaligned 2D projections. To tackle this problem, we propose COIN, a control-inpainting motion diffusion prior that enables fine-grained control to disentangle human and camera motions. Although pre-trained motion diffusion models encode rich motion priors, we find it non-trivial to leverage such knowledge to guide global motion estimation from RGB videos. COIN introduces a novel control-inpainting score distillation sampling method to ensure well-aligned, consistent, and high-quality motion from the diffusion prior within a joint optimization framework. Furthermore, we introduce a new human-scene relation loss to alleviate the scale ambiguity by enforcing consistency among the humans, camera, and scene. Experiments on three challenging benchmarks demonstrate the effectiveness of COIN, which outperforms the state-of-the-art methods in terms of global human motion estimation and camera motion estimation. As an illustrative example, COIN outperforms the state-of-the-art method by 33% in world joint position error (W-MPJPE) on the RICH dataset.
ShapeBoost: Boosting Human Shape Estimation with Part-Based Parameterization and Clothing-Preserving Augmentation
Mar 02, 2024



Accurate human shape recovery from a monocular RGB image is a challenging task because humans come in different shapes and sizes and wear different clothes. In this paper, we propose ShapeBoost, a new human shape recovery framework that achieves pixel-level alignment even for rare body shapes and high accuracy for people wearing different types of clothes. Unlike previous approaches that rely on the use of PCA-based shape coefficients, we adopt a new human shape parameterization that decomposes the human shape into bone lengths and the mean width of each part slice. This part-based parameterization technique achieves a balance between flexibility and validity using a semi-analytical shape reconstruction algorithm. Based on this new parameterization, a clothing-preserving data augmentation module is proposed to generate realistic images with diverse body shapes and accurate annotations. Experimental results show that our method outperforms other state-of-the-art methods in diverse body shape situations as well as in varied clothing situations.
Denoising Vision Transformers
Jan 05, 2024
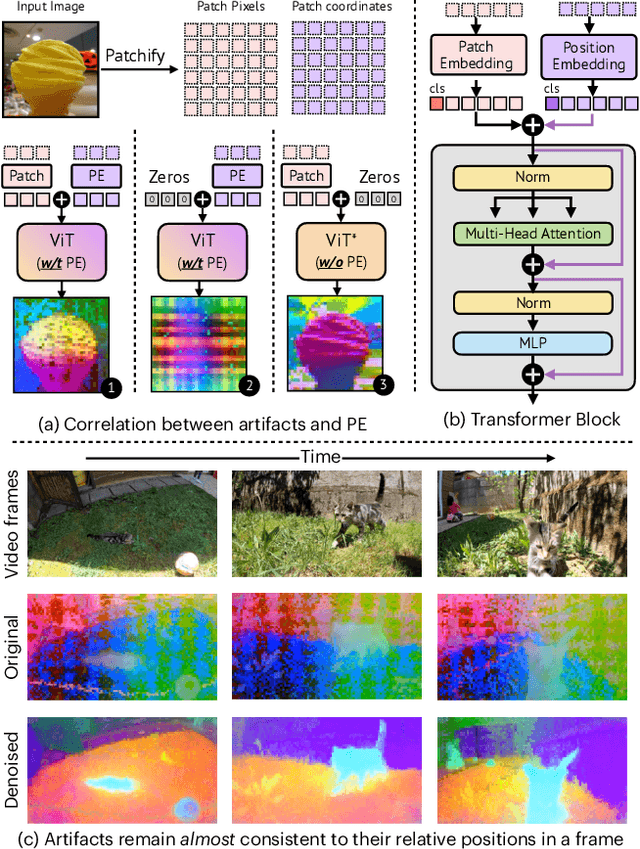
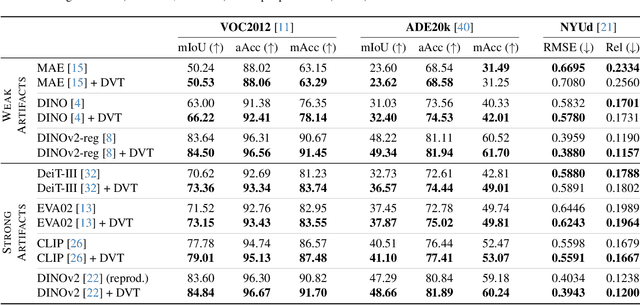
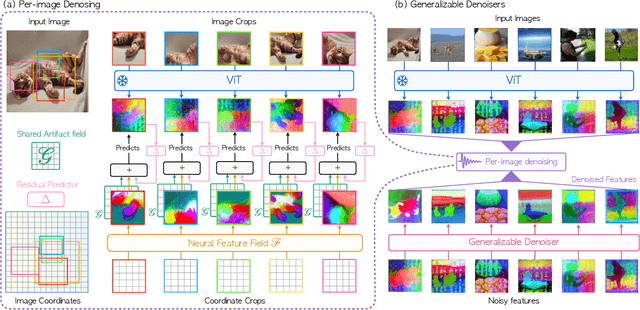
We delve into a nuanced but significant challenge inherent to Vision Transformers (ViTs): feature maps of these models exhibit grid-like artifacts, which detrimentally hurt the performance of ViTs in downstream tasks. Our investigations trace this fundamental issue down to the positional embeddings at the input stage. To address this, we propose a novel noise model, which is universally applicable to all ViTs. Specifically, the noise model dissects ViT outputs into three components: a semantics term free from noise artifacts and two artifact-related terms that are conditioned on pixel locations. Such a decomposition is achieved by enforcing cross-view feature consistency with neural fields in a per-image basis. This per-image optimization process extracts artifact-free features from raw ViT outputs, providing clean features for offline applications. Expanding the scope of our solution to support online functionality, we introduce a learnable denoiser to predict artifact-free features directly from unprocessed ViT outputs, which shows remarkable generalization capabilities to novel data without the need for per-image optimization. Our two-stage approach, termed Denoising Vision Transformers (DVT), does not require re-training existing pre-trained ViTs and is immediately applicable to any Transformer-based architecture. We evaluate our method on a variety of representative ViTs (DINO, MAE, DeiT-III, EVA02, CLIP, DINOv2, DINOv2-reg). Extensive evaluations demonstrate that our DVT consistently and significantly improves existing state-of-the-art general-purpose models in semantic and geometric tasks across multiple datasets (e.g., +3.84 mIoU). We hope our study will encourage a re-evaluation of ViT design, especially regarding the naive use of positional embeddings.