 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD&D: Learning Human Dynamics from Dynamic Camera
Paper and Code

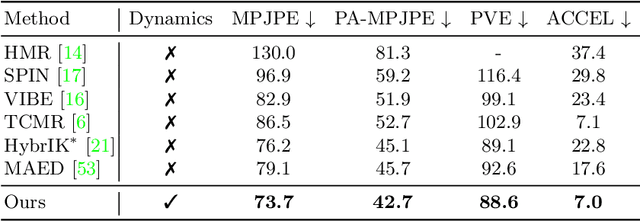


3D human pose estimation from a monocular video has recently seen significant improvements. However, most state-of-the-art methods are kinematics-based, which are prone to physically implausible motions with pronounced artifacts. Current dynamics-based methods can predict physically plausible motion but are restricted to simple scenarios with static camera view. In this work, we present D&D (Learning Human Dynamics from Dynamic Camera), which leverages the laws of physics to reconstruct 3D human motion from the in-the-wild videos with a moving camera. D&D introduces inertial force control (IFC) to explain the 3D human motion in the non-inertial local frame by considering the inertial forces of the dynamic camera. To learn the ground contact with limited annotations, we develop probabilistic contact torque (PCT), which is computed by differentiable sampling from contact probabilities and used to generate motions. The contact state can be weakly supervised by encouraging the model to generate correct motions. Furthermore, we propose an attentive PD controller that adjusts target pose states using temporal information to obtain smooth and accurate pose control. Our approach is entirely neural-based and runs without offline optimization or simulation in physics engines. Experiments on large-scale 3D human motion benchmarks demonstrate the effectiveness of D&D, where we exhibit superior performance against both state-of-the-art kinematics-based and dynamics-based methods. Code is available at https://github.com/Jeffsjtu/DnD