 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaGen: A DSL, Database, and Benchmark for VLM-Assisted Metamaterial Generation
Aug 25, 2025Metamaterials are micro-architected structures whose geometry imparts highly tunable-often counter-intuitive-bulk properties. Yet their design is difficult because of geometric complexity and a non-trivial mapping from architecture to behaviour. We address these challenges with three complementary contributions. (i) MetaDSL: a compact, semantically rich domain-specific language that captures diverse metamaterial designs in a form that is both human-readable and machine-parsable. (ii) MetaDB: a curated repository of more than 150,000 parameterized MetaDSL programs together with their derivatives-three-dimensional geometry, multi-view renderings, and simulated elastic properties. (iii) MetaBench: benchmark suites that test three core capabilities of vision-language metamaterial assistants-structure reconstruction, property-driven inverse design, and performance prediction. We establish baselines by fine-tuning state-of-the-art vision-language models and deploy an omni-model within an interactive, CAD-like interface. Case studies show that our framework provides a strong first step toward integrated design and understanding of structure-representation-property relationships.
ChatGarment: Garment Estimation, Generation and Editing via Large Language Models
Dec 23, 2024We introduce ChatGarment, a novel approach that leverages large vision-language models (VLMs) to automate the estimation, generation, and editing of 3D garments from images or text descriptions. Unlike previous methods that struggle in real-world scenarios or lack interactive editing capabilities, ChatGarment can estimate sewing patterns from in-the-wild images or sketches, generate them from text descriptions, and edit garments based on user instructions, all within an interactive dialogue. These sewing patterns can then be draped into 3D garments, which are easily animatable and simulatable. This is achieved by finetuning a VLM to directly generate a JSON file that includes both textual descriptions of garment types and styles, as well as continuous numerical attributes. This JSON file is then used to create sewing patterns through a programming parametric model. To support this, we refine the existing programming model, GarmentCode, by expanding its garment type coverage and simplifying its structure for efficient VLM fine-tuning. Additionally, we construct a large-scale dataset of image-to-sewing-pattern and text-to-sewing-pattern pairs through an automated data pipeline. Extensive evaluations demonstrate ChatGarment's ability to accurately reconstruct, generate, and edit garments from multimodal inputs, highlighting its potential to revolutionize workflows in fashion and gaming applications. Code and data will be available at https://chatgarment.github.io/.
ShapeBoost: Boosting Human Shape Estimation with Part-Based Parameterization and Clothing-Preserving Augmentation
Mar 02, 2024



Accurate human shape recovery from a monocular RGB image is a challenging task because humans come in different shapes and sizes and wear different clothes. In this paper, we propose ShapeBoost, a new human shape recovery framework that achieves pixel-level alignment even for rare body shapes and high accuracy for people wearing different types of clothes. Unlike previous approaches that rely on the use of PCA-based shape coefficients, we adopt a new human shape parameterization that decomposes the human shape into bone lengths and the mean width of each part slice. This part-based parameterization technique achieves a balance between flexibility and validity using a semi-analytical shape reconstruction algorithm. Based on this new parameterization, a clothing-preserving data augmentation module is proposed to generate realistic images with diverse body shapes and accurate annotations. Experimental results show that our method outperforms other state-of-the-art methods in diverse body shape situations as well as in varied clothing situations.
Domain Invariant Learning for Gaussian Processes and Bayesian Exploration
Dec 18, 2023Out-of-distribution (OOD) generalization has long been a challenging problem that remains largely unsolved. Gaussian processes (GP), as popular probabilistic model classes, especially in the small data regime, presume strong OOD generalization abilities. Surprisingly, their OOD generalization abilities have been under-explored before compared with other lines of GP research. In this paper, we identify that GP is not free from the problem and propose a domain invariant learning algorithm for Gaussian processes (DIL-GP) with a min-max optimization on the likelihood. DIL-GP discovers the heterogeneity in the data and forces invariance across partitioned subsets of data. We further extend the DIL-GP to improve Bayesian optimization's adaptability on changing environments. Numerical experiments demonstrate the superiority of DIL-GP for predictions on several synthetic and real-world datasets. We further demonstrate the effectiveness of the DIL-GP Bayesian optimization method on a PID parameters tuning experiment for a quadrotor. The full version and source code are available at: https://github.com/Billzxl/DIL-GP.
NIKI: Neural Inverse Kinematics with Invertible Neural Networks for 3D Human Pose and Shape Estimation
May 15, 2023With the progress of 3D human pose and shape estimation, state-of-the-art methods can either be robust to occlusions or obtain pixel-aligned accuracy in non-occlusion cases. However, they cannot obtain robustness and mesh-image alignment at the same time. In this work, we present NIKI (Neural Inverse Kinematics with Invertible Neural Network), which models bi-directional errors to improve the robustness to occlusions and obtain pixel-aligned accuracy. NIKI can learn from both the forward and inverse processes with invertible networks. In the inverse process, the model separates the error from the plausible 3D pose manifold for a robust 3D human pose estimation. In the forward process, we enforce the zero-error boundary conditions to improve the sensitivity to reliable joint positions for better mesh-image alignment. Furthermore, NIKI emulates the analytical inverse kinematics algorithms with the twist-and-swing decomposition for better interpretability. Experiments on standard and occlusion-specific benchmarks demonstrate the effectiveness of NIKI, where we exhibit robust and well-aligned results simultaneously. Code is available at https://github.com/Jeff-sjtu/NIKI
HybrIK-X: Hybrid Analytical-Neural Inverse Kinematics for Whole-body Mesh Recovery
Apr 12, 2023Recovering whole-body mesh by inferring the abstract pose and shape parameters from visual content can obtain 3D bodies with realistic structures. However, the inferring process is highly non-linear and suffers from image-mesh misalignment, resulting in inaccurate reconstruction. In contrast, 3D keypoint estimation methods utilize the volumetric representation to achieve pixel-level accuracy but may predict unrealistic body structures. To address these issues, this paper presents a novel hybrid inverse kinematics solution, HybrIK, that integrates the merits of 3D keypoint estimation and body mesh recovery in a unified framework. HybrIK directly transforms accurate 3D joints to body-part rotations via twist-and-swing decomposition. The swing rotations are analytically solved with 3D joints, while the twist rotations are derived from visual cues through neural networks. To capture comprehensive whole-body details, we further develop a holistic framework, HybrIK-X, which enhances HybrIK with articulated hands and an expressive face. HybrIK-X is fast and accurate by solving the whole-body pose with a one-stage model. Experiments demonstrate that HybrIK and HybrIK-X preserve both the accuracy of 3D joints and the realistic structure of the parametric human model, leading to pixel-aligned whole-body mesh recovery. The proposed method significantly surpasses the state-of-the-art methods on various benchmarks for body-only, hand-only, and whole-body scenarios. Code and results can be found at https://jeffli.site/HybrIK-X/
D&D: Learning Human Dynamics from Dynamic Camera
Sep 19, 2022
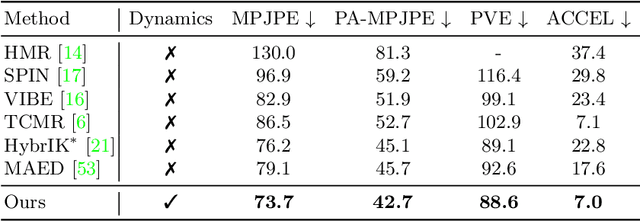


3D human pose estimation from a monocular video has recently seen significant improvements. However, most state-of-the-art methods are kinematics-based, which are prone to physically implausible motions with pronounced artifacts. Current dynamics-based methods can predict physically plausible motion but are restricted to simple scenarios with static camera view. In this work, we present D&D (Learning Human Dynamics from Dynamic Camera), which leverages the laws of physics to reconstruct 3D human motion from the in-the-wild videos with a moving camera. D&D introduces inertial force control (IFC) to explain the 3D human motion in the non-inertial local frame by considering the inertial forces of the dynamic camera. To learn the ground contact with limited annotations, we develop probabilistic contact torque (PCT), which is computed by differentiable sampling from contact probabilities and used to generate motions. The contact state can be weakly supervised by encouraging the model to generate correct motions. Furthermore, we propose an attentive PD controller that adjusts target pose states using temporal information to obtain smooth and accurate pose control. Our approach is entirely neural-based and runs without offline optimization or simulation in physics engines. Experiments on large-scale 3D human motion benchmarks demonstrate the effectiveness of D&D, where we exhibit superior performance against both state-of-the-art kinematics-based and dynamics-based methods. Code is available at https://github.com/Jeffsjtu/DnD
Towards Using Clothes Style Transfer for Scenario-aware Person Video Generation
Oct 25, 2021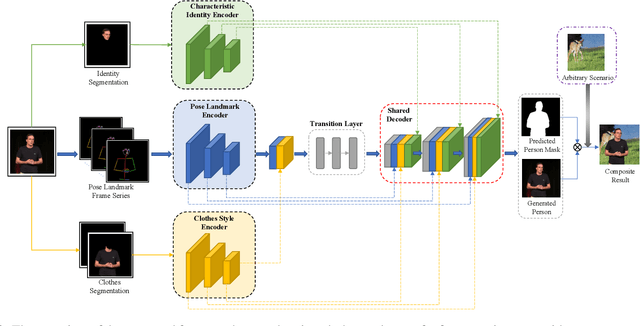
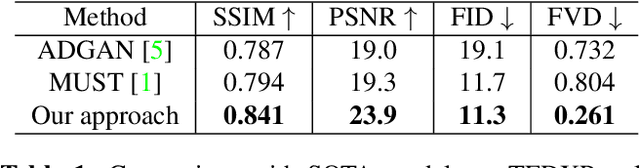
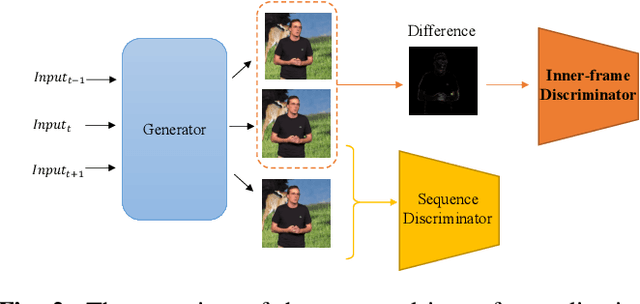
Clothes style transfer for person video generation is a challenging task, due to drastic variations of intra-person appearance and video scenarios. To tackle this problem, most recent AdaIN-based architectures are proposed to extract clothes and scenario features for generation. However, these approaches suffer from being short of fine-grained details and are prone to distort the origin person. To further improve the generation performance, we propose a novel framework with disentangled multi-branch encoders and a shared decoder. Moreover, to pursue the strong video spatio-temporal consistency, an inner-frame discriminator is delicately designed with input being cross-frame difference. Besides, the proposed framework possesses the property of scenario adaptation. Extensive experiments on the TEDXPeople benchmark demonstrate the superiority of our method over state-of-the-art approaches in terms of image quality and video coherence.
Human Pose Regression with Residual Log-likelihood Estimation
Jul 31, 2021



Heatmap-based methods dominate in the field of human pose estimation by modelling the output distribution through likelihood heatmaps. In contrast, regression-based methods are more efficient but suffer from inferior performance. In this work, we explore maximum likelihood estimation (MLE) to develop an efficient and effective regression-based methods. From the perspective of MLE, adopting different regression losses is making different assumptions about the output density function. A density function closer to the true distribution leads to a better regression performance. In light of this, we propose a novel regression paradigm with Residual Log-likelihood Estimation (RLE) to capture the underlying output distribution. Concretely, RLE learns the change of the distribution instead of the unreferenced underlying distribution to facilitate the training process. With the proposed reparameterization design, our method is compatible with off-the-shelf flow models. The proposed method is effective, efficient and flexible. We show its potential in various human pose estimation tasks with comprehensive experiments. Compared to the conventional regression paradigm, regression with RLE bring 12.4 mAP improvement on MSCOCO without any test-time overhead. Moreover, for the first time, especially on multi-person pose estimation, our regression method is superior to the heatmap-based methods. Our code is available at https://github.com/Jeff-sjtu/res-loglikelihood-regression
HybrIK: A Hybrid Analytical-Neural Inverse Kinematics Solution for 3D Human Pose and Shape Estimation
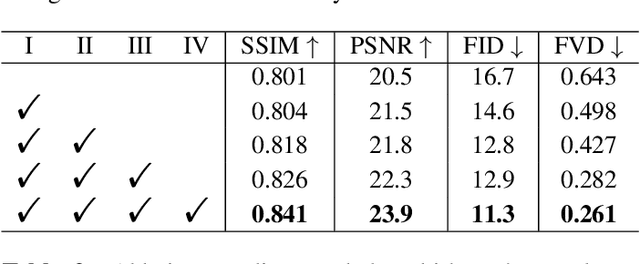
Nov 30, 2020
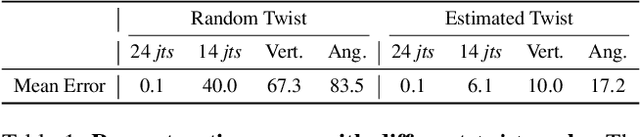
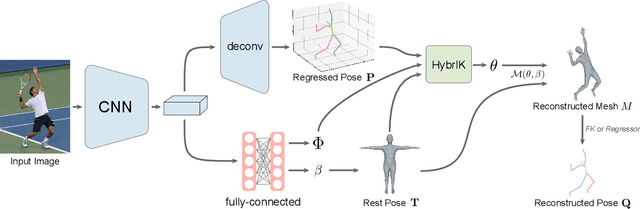

Model-based 3D pose and shape estimation methods reconstruct a full 3D mesh for the human body by estimating several parameters. However, learning the abstract parameters is a highly non-linear process and suffers from image-model misalignment, leading to mediocre model performance. In contrast, 3D keypoint estimation methods combine deep CNN network with the volumetric representation to achieve pixel-level localization accuracy but may predict unrealistic body structure. In this paper, we address the above issues by bridging the gap between body mesh estimation and 3D keypoint estimation. We propose a novel hybrid inverse kinematics solution (HybrIK). HybrIK directly transforms accurate 3D joints to relative body-part rotations for 3D body mesh reconstruction, via the twist-and-swing decomposition. The swing rotation is analytically solved with 3D joints, and the twist rotation is derived from the visual cues through the neural network. We show that HybrIK preserves both the accuracy of 3D pose and the realistic body structure of the parametric human model, leading to a pixel-aligned 3D body mesh and a more accurate 3D pose than the pure 3D keypoint estimation methods. Without bells and whistles, the proposed method surpasses the state-of-the-art methods by a large margin on various 3D human pose and shape benchmarks. As an illustrative example, HybrIK outperforms all the previous methods by 13.2 mm MPJPE and 21.9 mm PVE on 3DPW dataset. Our code is available at https://github.com/Jeff-sjtu/HybrIK.