 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Using Clothes Style Transfer for Scenario-aware Person Video Generation
Paper and Code
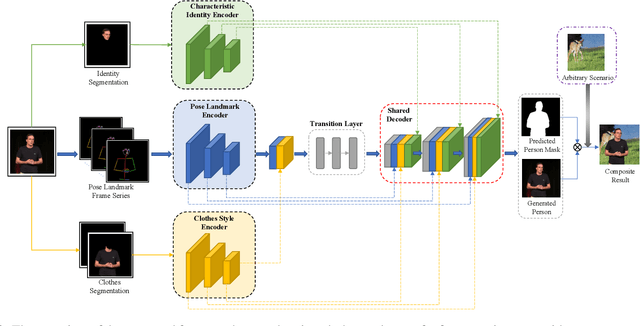
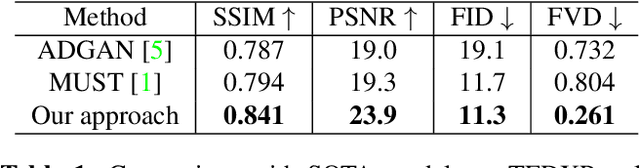
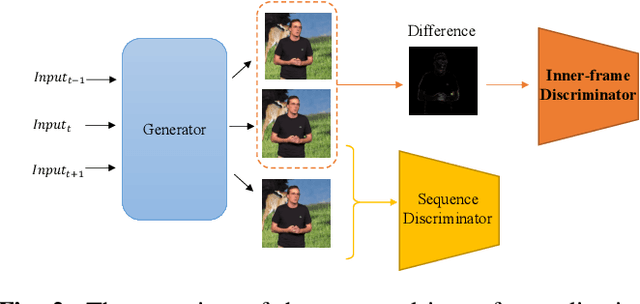
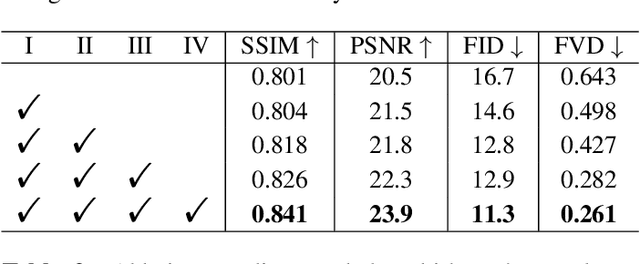
Clothes style transfer for person video generation is a challenging task, due to drastic variations of intra-person appearance and video scenarios. To tackle this problem, most recent AdaIN-based architectures are proposed to extract clothes and scenario features for generation. However, these approaches suffer from being short of fine-grained details and are prone to distort the origin person. To further improve the generation performance, we propose a novel framework with disentangled multi-branch encoders and a shared decoder. Moreover, to pursue the strong video spatio-temporal consistency, an inner-frame discriminator is delicately designed with input being cross-frame difference. Besides, the proposed framework possesses the property of scenario adaptation. Extensive experiments on the TEDXPeople benchmark demonstrate the superiority of our method over state-of-the-art approaches in terms of image quality and video coherence.