 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniCam: Unified Multimodal Video Generation via Camera Control
Apr 03, 2025Camera control, which achieves diverse visual effects by changing camera position and pose, has attracted widespread attention. However, existing methods face challenges such as complex interaction and limited control capabilities. To address these issues, we present OmniCam, a unified multimodal camera control framework. Leveraging large language models and video diffusion models, OmniCam generates spatio-temporally consistent videos. It supports various combinations of input modalities: the user can provide text or video with expected trajectory as camera path guidance, and image or video as content reference, enabling precise control over camera motion. To facilitate the training of OmniCam, we introduce the OmniTr dataset, which contains a large collection of high-quality long-sequence trajectories, videos, and corresponding descriptions. Experimental results demonstrate that our model achieves state-of-the-art performance in high-quality camera-controlled video generation across various metrics.
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
Mar 05, 2025Scaling up imitation learning for real-world applications requires efficient and cost-effective demonstration collection methods. Current teleoperation approaches, though effective, are expensive and inefficient due to the dependency on physical robot platforms. Alternative data sources like in-the-wild demonstrations can eliminate the need for physical robots and offer more scalable solutions. However, existing in-the-wild data collection devices have limitations: handheld devices offer restricted in-hand camera observation, while whole-body devices often require fine-tuning with robot data due to action inaccuracies. In this paper, we propose AirExo-2, a low-cost exoskeleton system for large-scale in-the-wild demonstration collection. By introducing the demonstration adaptor to transform the collected in-the-wild demonstrations into pseudo-robot demonstrations, our system addresses key challenges in utilizing in-the-wild demonstrations for downstream imitation learning in real-world environments. Additionally, we present RISE-2, a generalizable policy that integrates 2D and 3D perceptions, outperforming previous imitation learning policies in both in-domain and out-of-domain tasks, even with limited demonstrations. By leveraging in-the-wild demonstrations collected and transformed by the AirExo-2 system, without the need for additional robot demonstrations, RISE-2 achieves comparable or superior performance to policies trained with teleoperated data, highlighting the potential of AirExo-2 for scalable and generalizable imitation learning. Project page: https://airexo.tech/airexo2
Motion Before Action: Diffusing Object Motion as Manipulation Condition
Nov 14, 2024



Inferring object motion representations from observations enhances the performance of robotic manipulation tasks. This paper introduces a new paradigm for robot imitation learning that generates action sequences by reasoning about object motion from visual observations. We propose MBA (Motion Before Action), a novel module that employs two cascaded diffusion processes for object motion generation and robot action generation under object motion guidance. MBA first predicts the future pose sequence of the object based on observations, then uses this sequence as a condition to guide robot action generation. Designed as a plug-and-play component, MBA can be flexibly integrated into existing robotic manipulation policies with diffusion action heads. Extensive experiments in both simulated and real-world environments demonstrate that our approach substantially improves the performance of existing policies across a wide range of manipulation tasks.
Multi-view Hand Reconstruction with a Point-Embedded Transformer
Aug 20, 2024



This work introduces a novel and generalizable multi-view Hand Mesh Reconstruction (HMR) model, named POEM, designed for practical use in real-world hand motion capture scenarios. The advances of the POEM model consist of two main aspects. First, concerning the modeling of the problem, we propose embedding a static basis point within the multi-view stereo space. A point represents a natural form of 3D information and serves as an ideal medium for fusing features across different views, given its varied projections across these views. Consequently, our method harnesses a simple yet effective idea: a complex 3D hand mesh can be represented by a set of 3D basis points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encompass the hand in it. The second advance lies in the training strategy. We utilize a combination of five large-scale multi-view datasets and employ randomization in the number, order, and poses of the cameras. By processing such a vast amount of data and a diverse array of camera configurations, our model demonstrates notable generalizability in the real-world applications. As a result, POEM presents a highly practical, plug-and-play solution that enables user-friendly, cost-effective multi-view motion capture for both left and right hands. The model and source codes are available at https://github.com/JubSteven/POEM-v2.
SemGrasp: Semantic Grasp Generation via Language Aligned Discretization
Apr 04, 2024Generating natural human grasps necessitates consideration of not just object geometry but also semantic information. Solely depending on object shape for grasp generation confines the applications of prior methods in downstream tasks. This paper presents a novel semantic-based grasp generation method, termed SemGrasp, which generates a static human grasp pose by incorporating semantic information into the grasp representation. We introduce a discrete representation that aligns the grasp space with semantic space, enabling the generation of grasp postures in accordance with language instructions. A Multimodal Large Language Model (MLLM) is subsequently fine-tuned, integrating object, grasp, and language within a unified semantic space. To facilitate the training of SemGrasp, we have compiled a large-scale, grasp-text-aligned dataset named CapGrasp, featuring about 260k detailed captions and 50k diverse grasps. Experimental findings demonstrate that SemGrasp efficiently generates natural human grasps in alignment with linguistic intentions. Our code, models, and dataset are available publicly at: https://kailinli.github.io/SemGrasp.
OAKINK2: A Dataset of Bimanual Hands-Object Manipulation in Complex Task Completion
Mar 28, 2024



We present OAKINK2, a dataset of bimanual object manipulation tasks for complex daily activities. In pursuit of constructing the complex tasks into a structured representation, OAKINK2 introduces three level of abstraction to organize the manipulation tasks: Affordance, Primitive Task, and Complex Task. OAKINK2 features on an object-centric perspective for decoding the complex tasks, treating them as a sequence of object affordance fulfillment. The first level, Affordance, outlines the functionalities that objects in the scene can afford, the second level, Primitive Task, describes the minimal interaction units that humans interact with the object to achieve its affordance, and the third level, Complex Task, illustrates how Primitive Tasks are composed and interdependent. OAKINK2 dataset provides multi-view image streams and precise pose annotations for the human body, hands and various interacting objects. This extensive collection supports applications such as interaction reconstruction and motion synthesis. Based on the 3-level abstraction of OAKINK2, we explore a task-oriented framework for Complex Task Completion (CTC). CTC aims to generate a sequence of bimanual manipulation to achieve task objectives. Within the CTC framework, we employ Large Language Models (LLMs) to decompose the complex task objectives into sequences of Primitive Tasks and have developed a Motion Fulfillment Model that generates bimanual hand motion for each Primitive Task. OAKINK2 datasets and models are available at https://oakink.net/v2.
UniMAP: Universal SMILES-Graph Representation Learning
Oct 22, 2023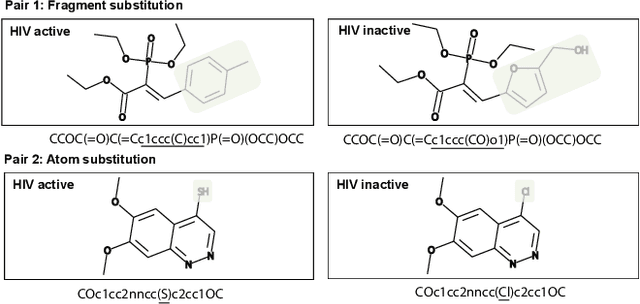
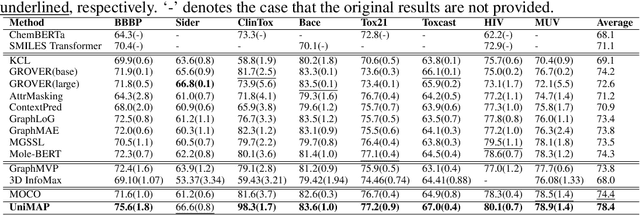
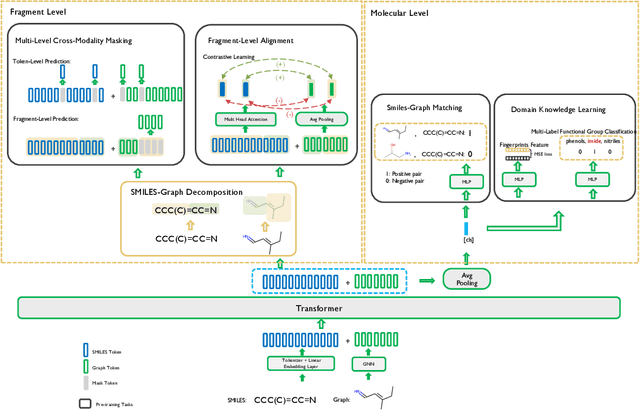
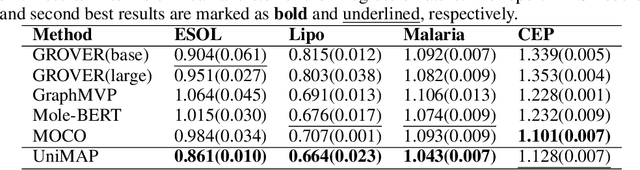
Molecular representation learning is fundamental for many drug related applications. Most existing molecular pre-training models are limited in using single molecular modality, either SMILES or graph representation. To effectively leverage both modalities, we argue that it is critical to capture the fine-grained 'semantics' between SMILES and graph, because subtle sequence/graph differences may lead to contrary molecular properties. In this paper, we propose a universal SMILE-graph representation learning model, namely UniMAP. Firstly, an embedding layer is employed to obtain the token and node/edge representation in SMILES and graph, respectively. A multi-layer Transformer is then utilized to conduct deep cross-modality fusion. Specially, four kinds of pre-training tasks are designed for UniMAP, including Multi-Level Cross-Modality Masking (CMM), SMILES-Graph Matching (SGM), Fragment-Level Alignment (FLA), and Domain Knowledge Learning (DKL). In this way, both global (i.e. SGM and DKL) and local (i.e. CMM and FLA) alignments are integrated to achieve comprehensive cross-modality fusion. We evaluate UniMAP on various downstream tasks, i.e. molecular property prediction, drug-target affinity prediction and drug-drug interaction. Experimental results show that UniMAP outperforms current state-of-the-art pre-training methods.We also visualize the learned representations to demonstrate the effect of multi-modality integration.
CHORD: Category-level Hand-held Object Reconstruction via Shape Deformation
Aug 21, 2023



In daily life, humans utilize hands to manipulate objects. Modeling the shape of objects that are manipulated by the hand is essential for AI to comprehend daily tasks and to learn manipulation skills. However, previous approaches have encountered difficulties in reconstructing the precise shapes of hand-held objects, primarily owing to a deficiency in prior shape knowledge and inadequate data for training. As illustrated, given a particular type of tool, such as a mug, despite its infinite variations in shape and appearance, humans have a limited number of 'effective' modes and poses for its manipulation. This can be attributed to the fact that humans have mastered the shape prior of the 'mug' category, and can quickly establish the corresponding relations between different mug instances and the prior, such as where the rim and handle are located. In light of this, we propose a new method, CHORD, for Category-level Hand-held Object Reconstruction via shape Deformation. CHORD deforms a categorical shape prior for reconstructing the intra-class objects. To ensure accurate reconstruction, we empower CHORD with three types of awareness: appearance, shape, and interacting pose. In addition, we have constructed a new dataset, COMIC, of category-level hand-object interaction. COMIC contains a rich array of object instances, materials, hand interactions, and viewing directions. Extensive evaluation shows that CHORD outperforms state-of-the-art approaches in both quantitative and qualitative measures. Code, model, and datasets are available at https://kailinli.github.io/CHORD.
Color-NeuS: Reconstructing Neural Implicit Surfaces with Color
Aug 14, 2023The reconstruction of object surfaces from multi-view images or monocular video is a fundamental issue in computer vision. However, much of the recent research concentrates on reconstructing geometry through implicit or explicit methods. In this paper, we shift our focus towards reconstructing mesh in conjunction with color. We remove the view-dependent color from neural volume rendering while retaining volume rendering performance through a relighting network. Mesh is extracted from the signed distance function (SDF) network for the surface, and color for each surface vertex is drawn from the global color network. To evaluate our approach, we conceived a in hand object scanning task featuring numerous occlusions and dramatic shifts in lighting conditions. We've gathered several videos for this task, and the results surpass those of any existing methods capable of reconstructing mesh alongside color. Additionally, our method's performance was assessed using public datasets, including DTU, BlendedMVS, and OmniObject3D. The results indicated that our method performs well across all these datasets. Project page: https://colmar-zlicheng.github.io/color_neus.