 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2K Retrofit: Entropy-Guided Efficient Sparse Refinement for High-Resolution 3D Geometry Prediction
Mar 23, 2026High-resolution geometric prediction is essential for robust perception in autonomous driving, robotics, and AR/MR, but current foundation models are fundamentally limited by their scalability to real-world, high-resolution scenarios. Direct inference on 2K images with these models incurs prohibitive computational and memory demands, making practical deployment challenging. To tackle the issue, we present 2K Retrofit, a novel framework that enables efficient 2K-resolution inference for any geometric foundation model, without modifying or retraining the backbone. Our approach leverages fast coarse predictions and an entropy-based sparse refinement to selectively enhance high-uncertainty regions, achieving precise and high-fidelity 2K outputs with minimal overhead. Extensive experiments on widely used benchmark demonstrate that 2K Retrofit consistently achieves state-of-the-art accuracy and speed, bridging the gap between research advances and scalable deployment in high-resolution 3D vision applications. Code will be released upon acceptance.
TinyAlign: Boosting Lightweight Vision-Language Models by Mitigating Modal Alignment Bottlenecks
May 19, 2025Lightweight Vision-Language Models (VLMs) are indispensable for resource-constrained applications. The prevailing approach to aligning vision and language models involves freezing both the vision encoder and the language model while training small connector modules. However, this strategy heavily depends on the intrinsic capabilities of the language model, which can be suboptimal for lightweight models with limited representational capacity. In this work, we investigate this alignment bottleneck through the lens of mutual information, demonstrating that the constrained capacity of the language model inherently limits the Effective Mutual Information (EMI) between multimodal inputs and outputs, thereby compromising alignment quality. To address this challenge, we propose TinyAlign, a novel framework inspired by Retrieval-Augmented Generation, which strategically retrieves relevant context from a memory bank to enrich multimodal inputs and enhance their alignment. Extensive empirical evaluations reveal that TinyAlign significantly reduces training loss, accelerates convergence, and enhances task performance. Remarkably, it allows models to achieve baseline-level performance with only 40\% of the fine-tuning data, highlighting exceptional data efficiency. Our work thus offers a practical pathway for developing more capable lightweight VLMs while introducing a fresh theoretical lens to better understand and address alignment bottlenecks in constrained multimodal systems.
Unveiling Hidden Vulnerabilities in Digital Human Generation via Adversarial Attacks
Apr 24, 2025



Expressive human pose and shape estimation (EHPS) is crucial for digital human generation, especially in applications like live streaming. While existing research primarily focuses on reducing estimation errors, it largely neglects robustness and security aspects, leaving these systems vulnerable to adversarial attacks. To address this significant challenge, we propose the \textbf{Tangible Attack (TBA)}, a novel framework designed to generate adversarial examples capable of effectively compromising any digital human generation model. Our approach introduces a \textbf{Dual Heterogeneous Noise Generator (DHNG)}, which leverages Variational Autoencoders (VAE) and ControlNet to produce diverse, targeted noise tailored to the original image features. Additionally, we design a custom \textbf{adversarial loss function} to optimize the noise, ensuring both high controllability and potent disruption. By iteratively refining the adversarial sample through multi-gradient signals from both the noise and the state-of-the-art EHPS model, TBA substantially improves the effectiveness of adversarial attacks. Extensive experiments demonstrate TBA's superiority, achieving a remarkable 41.0\% increase in estimation error, with an average improvement of approximately 17.0\%. These findings expose significant security vulnerabilities in current EHPS models and highlight the need for stronger defenses in digital human generation systems.
Unicorn: Text-Only Data Synthesis for Vision Language Model Training
Mar 28, 2025Training vision-language models (VLMs) typically requires large-scale, high-quality image-text pairs, but collecting or synthesizing such data is costly. In contrast, text data is abundant and inexpensive, prompting the question: can high-quality multimodal training data be synthesized purely from text? To tackle this, we propose a cross-integrated three-stage multimodal data synthesis framework, which generates two datasets: Unicorn-1.2M and Unicorn-471K-Instruction. In Stage 1: Diverse Caption Data Synthesis, we construct 1.2M semantically diverse high-quality captions by expanding sparse caption seeds using large language models (LLMs). In Stage 2: Instruction-Tuning Data Generation, we further process 471K captions into multi-turn instruction-tuning tasks to support complex reasoning. Finally, in Stage 3: Modality Representation Transfer, these textual captions representations are transformed into visual representations, resulting in diverse synthetic image representations. This three-stage process enables us to construct Unicorn-1.2M for pretraining and Unicorn-471K-Instruction for instruction-tuning, without relying on real images. By eliminating the dependency on real images while maintaining data quality and diversity, our framework offers a cost-effective and scalable solution for VLMs training. Code is available at https://github.com/Yu-xm/Unicorn.git.
Meta-Learning Empowered Meta-Face: Personalized Speaking Style Adaptation for Audio-Driven 3D Talking Face Animation
Aug 18, 2024



Audio-driven 3D face animation is increasingly vital in live streaming and augmented reality applications. While remarkable progress has been observed, most existing approaches are designed for specific individuals with predefined speaking styles, thus neglecting the adaptability to varied speaking styles. To address this limitation, this paper introduces MetaFace, a novel methodology meticulously crafted for speaking style adaptation. Grounded in the novel concept of meta-learning, MetaFace is composed of several key components: the Robust Meta Initialization Stage (RMIS) for fundamental speaking style adaptation, the Dynamic Relation Mining Neural Process (DRMN) for forging connections between observed and unobserved speaking styles, and the Low-rank Matrix Memory Reduction Approach to enhance the efficiency of model optimization as well as learning style details. Leveraging these novel designs, MetaFace not only significantly outperforms robust existing baselines but also establishes a new state-of-the-art, as substantiated by our experimental results.
RPBG: Towards Robust Neural Point-based Graphics in the Wild
May 09, 2024
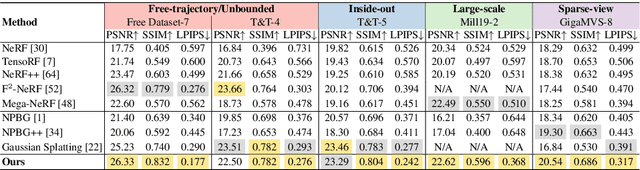

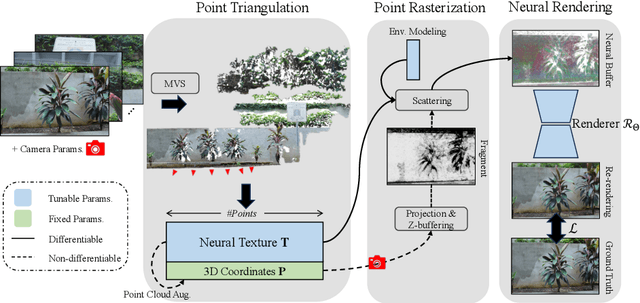
Point-based representations have recently gained popularity in novel view synthesis, for their unique advantages, e.g., intuitive geometric representation, simple manipulation, and faster convergence. However, based on our observation, these point-based neural re-rendering methods are only expected to perform well under ideal conditions and suffer from noisy, patchy points and unbounded scenes, which are challenging to handle but defacto common in real applications. To this end, we revisit one such influential method, known as Neural Point-based Graphics (NPBG), as our baseline, and propose Robust Point-based Graphics (RPBG). We in-depth analyze the factors that prevent NPBG from achieving satisfactory renderings on generic datasets, and accordingly reform the pipeline to make it more robust to varying datasets in-the-wild. Inspired by the practices in image restoration, we greatly enhance the neural renderer to enable the attention-based correction of point visibility and the inpainting of incomplete rasterization, with only acceptable overheads. We also seek for a simple and lightweight alternative for environment modeling and an iterative method to alleviate the problem of poor geometry. By thorough evaluation on a wide range of datasets with different shooting conditions and camera trajectories, RPBG stably outperforms the baseline by a large margin, and exhibits its great robustness over state-of-the-art NeRF-based variants. Code available at https://github.com/QT-Zhu/RPBG.
CHORD: Category-level Hand-held Object Reconstruction via Shape Deformation
Aug 21, 2023



In daily life, humans utilize hands to manipulate objects. Modeling the shape of objects that are manipulated by the hand is essential for AI to comprehend daily tasks and to learn manipulation skills. However, previous approaches have encountered difficulties in reconstructing the precise shapes of hand-held objects, primarily owing to a deficiency in prior shape knowledge and inadequate data for training. As illustrated, given a particular type of tool, such as a mug, despite its infinite variations in shape and appearance, humans have a limited number of 'effective' modes and poses for its manipulation. This can be attributed to the fact that humans have mastered the shape prior of the 'mug' category, and can quickly establish the corresponding relations between different mug instances and the prior, such as where the rim and handle are located. In light of this, we propose a new method, CHORD, for Category-level Hand-held Object Reconstruction via shape Deformation. CHORD deforms a categorical shape prior for reconstructing the intra-class objects. To ensure accurate reconstruction, we empower CHORD with three types of awareness: appearance, shape, and interacting pose. In addition, we have constructed a new dataset, COMIC, of category-level hand-object interaction. COMIC contains a rich array of object instances, materials, hand interactions, and viewing directions. Extensive evaluation shows that CHORD outperforms state-of-the-art approaches in both quantitative and qualitative measures. Code, model, and datasets are available at https://kailinli.github.io/CHORD.
POEM: Reconstructing Hand in a Point Embedded Multi-view Stereo
Apr 08, 2023



Enable neural networks to capture 3D geometrical-aware features is essential in multi-view based vision tasks. Previous methods usually encode the 3D information of multi-view stereo into the 2D features. In contrast, we present a novel method, named POEM, that directly operates on the 3D POints Embedded in the Multi-view stereo for reconstructing hand mesh in it. Point is a natural form of 3D information and an ideal medium for fusing features across views, as it has different projections on different views. Our method is thus in light of a simple yet effective idea, that a complex 3D hand mesh can be represented by a set of 3D points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encircle the hand. To leverage the power of points, we design two operations: point-based feature fusion and cross-set point attention mechanism. Evaluation on three challenging multi-view datasets shows that POEM outperforms the state-of-the-art in hand mesh reconstruction. Code and models are available for research at https://github.com/lixiny/POEM.
FuRPE: Learning Full-body Reconstruction from Part Experts
Nov 30, 2022



Full-body reconstruction is a fundamental but challenging task. Owing to the lack of annotated data, the performances of existing methods are largely limited. In this paper, we propose a novel method named Full-body Reconstruction from Part Experts~(FuRPE) to tackle this issue. In FuRPE, the network is trained using pseudo labels and features generated from part-experts. An simple yet effective pseudo ground-truth selection scheme is proposed to extract high-quality pseudo labels. In this way, a large-scale of existing human body reconstruction datasets can be leveraged and contribute to the model training. In addition, an exponential moving average training strategy is introduced to train the network in a self-supervised manner, further boosting the performance of the model. Extensive experiments on several widely used datasets demonstrate the effectiveness of our method over the baseline. Our method achieves the state-of-the-art performance. Code will be publicly available for further research.
MonoPCNS: Monocular 3D Object Detection via Point Cloud Network Simulation
Aug 19, 2022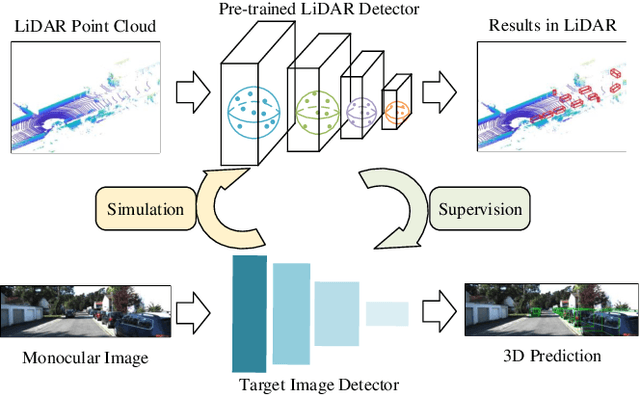
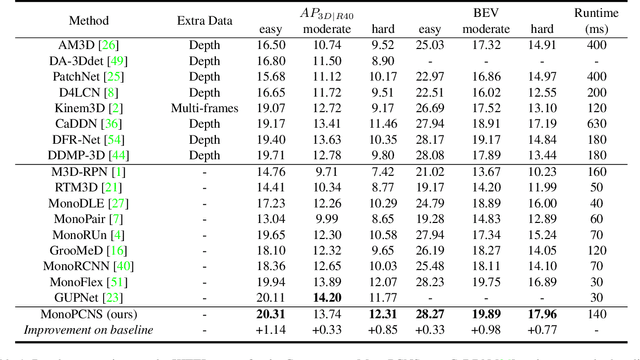
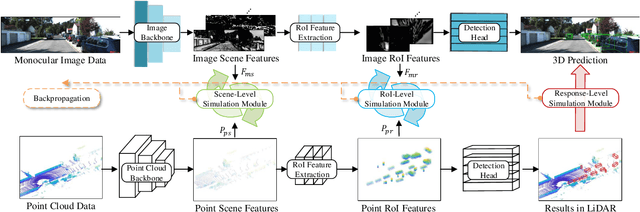
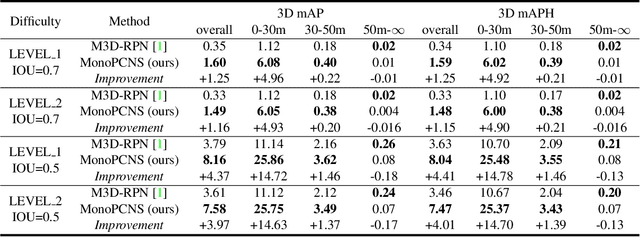
Monocular 3D object detection is a fundamental but very important task to many applications including autonomous driving, robotic grasping and augmented reality. Existing leading methods tend to estimate the depth of the input image first, and detect the 3D object based on point cloud. This routine suffers from the inherent gap between depth estimation and object detection. Besides, the prediction error accumulation would also affect the performance. In this paper, a novel method named MonoPCNS is proposed. The insight behind introducing MonoPCNS is that we propose to simulate the feature learning behavior of a point cloud based detector for monocular detector during the training period. Hence, during inference period, the learned features and prediction would be similar to the point cloud based detector as possible. To achieve it, we propose one scene-level simulation module, one RoI-level simulation module and one response-level simulation module, which are progressively used for the detector's full feature learning and prediction pipeline. We apply our method to the famous M3D-RPN detector and CaDDN detector, conducting extensive experiments on KITTI and Waymo Open dataset. Results show that our method consistently improves the performance of different monocular detectors for a large margin without changing their network architectures. Our method finally achieves state-of-the-art performance.