 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Adapt: Few-shot Bimanual Adaptation for Novel Categories of 3D Objects via Semantic Correspondence
Feb 09, 2026Bimanual manipulation is imperative yet challenging for robots to execute complex tasks, requiring coordinated collaboration between two arms. However, existing methods for bimanual manipulation often rely on costly data collection and training, struggling to generalize to unseen objects in novel categories efficiently. In this paper, we present Bi-Adapt, a novel framework designed for efficient generalization for bimanual manipulation via semantic correspondence. Bi-Adapt achieves cross-category affordance mapping by leveraging the strong capability of vision foundation models. Fine-tuning with restricted data on novel categories, Bi-Adapt exhibits notable generalization to out-of-category objects in a zero-shot manner. Extensive experiments conducted in both simulation and real-world environments validate the effectiveness of our approach and demonstrate its high efficiency, achieving a high success rate on different benchmark tasks across novel categories with limited data. Project website: https://biadapt-project.github.io/
Mimicking-Bench: A Benchmark for Generalizable Humanoid-Scene Interaction Learning via Human Mimicking
Dec 23, 2024Learning generic skills for humanoid robots interacting with 3D scenes by mimicking human data is a key research challenge with significant implications for robotics and real-world applications. However, existing methodologies and benchmarks are constrained by the use of small-scale, manually collected demonstrations, lacking the general dataset and benchmark support necessary to explore scene geometry generalization effectively. To address this gap, we introduce Mimicking-Bench, the first comprehensive benchmark designed for generalizable humanoid-scene interaction learning through mimicking large-scale human animation references. Mimicking-Bench includes six household full-body humanoid-scene interaction tasks, covering 11K diverse object shapes, along with 20K synthetic and 3K real-world human interaction skill references. We construct a complete humanoid skill learning pipeline and benchmark approaches for motion retargeting, motion tracking, imitation learning, and their various combinations. Extensive experiments highlight the value of human mimicking for skill learning, revealing key challenges and research directions.
Multi-view Hand Reconstruction with a Point-Embedded Transformer
Aug 20, 2024



This work introduces a novel and generalizable multi-view Hand Mesh Reconstruction (HMR) model, named POEM, designed for practical use in real-world hand motion capture scenarios. The advances of the POEM model consist of two main aspects. First, concerning the modeling of the problem, we propose embedding a static basis point within the multi-view stereo space. A point represents a natural form of 3D information and serves as an ideal medium for fusing features across different views, given its varied projections across these views. Consequently, our method harnesses a simple yet effective idea: a complex 3D hand mesh can be represented by a set of 3D basis points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encompass the hand in it. The second advance lies in the training strategy. We utilize a combination of five large-scale multi-view datasets and employ randomization in the number, order, and poses of the cameras. By processing such a vast amount of data and a diverse array of camera configurations, our model demonstrates notable generalizability in the real-world applications. As a result, POEM presents a highly practical, plug-and-play solution that enables user-friendly, cost-effective multi-view motion capture for both left and right hands. The model and source codes are available at https://github.com/JubSteven/POEM-v2.
Reconstruction and Simulation of Elastic Objects with Spring-Mass 3D Gaussians
Mar 14, 2024Reconstructing and simulating elastic objects from visual observations is crucial for applications in computer vision and robotics. Existing methods, such as 3D Gaussians, provide modeling for 3D appearance and geometry but lack the ability to simulate physical properties or optimize parameters for heterogeneous objects. We propose Spring-Gaus, a novel framework that integrates 3D Gaussians with physics-based simulation for reconstructing and simulating elastic objects from multi-view videos. Our method utilizes a 3D Spring-Mass model, enabling the optimization of physical parameters at the individual point level while decoupling the learning of physics and appearance. This approach achieves great sample efficiency, enhances generalization, and reduces sensitivity to the distribution of simulation particles. We evaluate Spring-Gaus on both synthetic and real-world datasets, demonstrating accurate reconstruction and simulation of elastic objects. This includes future prediction and simulation under varying initial states and environmental parameters. Project page: https://zlicheng.com/spring_gaus.
CHORD: Category-level Hand-held Object Reconstruction via Shape Deformation
Aug 21, 2023



In daily life, humans utilize hands to manipulate objects. Modeling the shape of objects that are manipulated by the hand is essential for AI to comprehend daily tasks and to learn manipulation skills. However, previous approaches have encountered difficulties in reconstructing the precise shapes of hand-held objects, primarily owing to a deficiency in prior shape knowledge and inadequate data for training. As illustrated, given a particular type of tool, such as a mug, despite its infinite variations in shape and appearance, humans have a limited number of 'effective' modes and poses for its manipulation. This can be attributed to the fact that humans have mastered the shape prior of the 'mug' category, and can quickly establish the corresponding relations between different mug instances and the prior, such as where the rim and handle are located. In light of this, we propose a new method, CHORD, for Category-level Hand-held Object Reconstruction via shape Deformation. CHORD deforms a categorical shape prior for reconstructing the intra-class objects. To ensure accurate reconstruction, we empower CHORD with three types of awareness: appearance, shape, and interacting pose. In addition, we have constructed a new dataset, COMIC, of category-level hand-object interaction. COMIC contains a rich array of object instances, materials, hand interactions, and viewing directions. Extensive evaluation shows that CHORD outperforms state-of-the-art approaches in both quantitative and qualitative measures. Code, model, and datasets are available at https://kailinli.github.io/CHORD.
Color-NeuS: Reconstructing Neural Implicit Surfaces with Color
Aug 14, 2023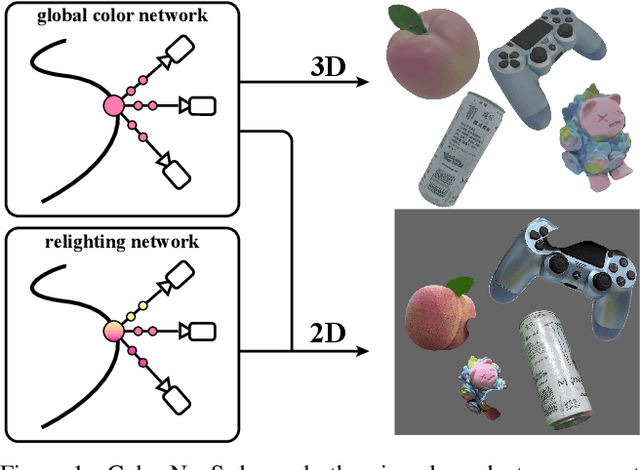

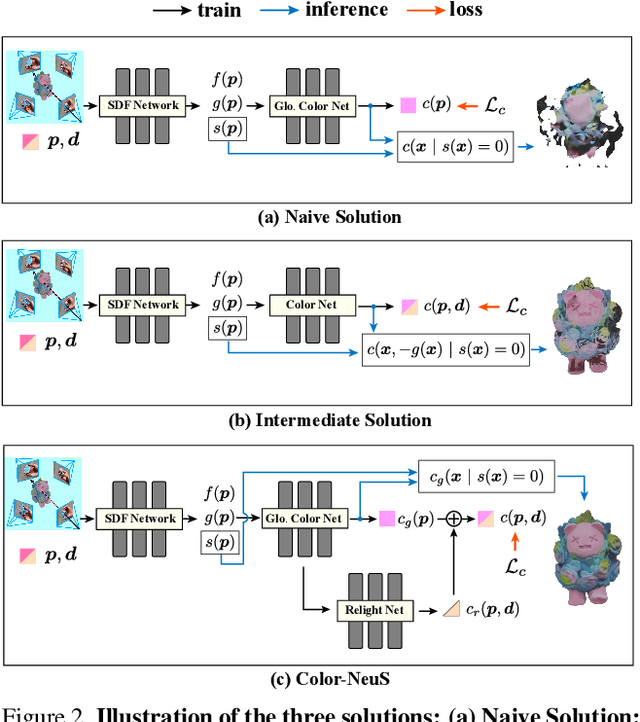

The reconstruction of object surfaces from multi-view images or monocular video is a fundamental issue in computer vision. However, much of the recent research concentrates on reconstructing geometry through implicit or explicit methods. In this paper, we shift our focus towards reconstructing mesh in conjunction with color. We remove the view-dependent color from neural volume rendering while retaining volume rendering performance through a relighting network. Mesh is extracted from the signed distance function (SDF) network for the surface, and color for each surface vertex is drawn from the global color network. To evaluate our approach, we conceived a in hand object scanning task featuring numerous occlusions and dramatic shifts in lighting conditions. We've gathered several videos for this task, and the results surpass those of any existing methods capable of reconstructing mesh alongside color. Additionally, our method's performance was assessed using public datasets, including DTU, BlendedMVS, and OmniObject3D. The results indicated that our method performs well across all these datasets. Project page: https://colmar-zlicheng.github.io/color_neus.
POEM: Reconstructing Hand in a Point Embedded Multi-view Stereo
Apr 08, 2023



Enable neural networks to capture 3D geometrical-aware features is essential in multi-view based vision tasks. Previous methods usually encode the 3D information of multi-view stereo into the 2D features. In contrast, we present a novel method, named POEM, that directly operates on the 3D POints Embedded in the Multi-view stereo for reconstructing hand mesh in it. Point is a natural form of 3D information and an ideal medium for fusing features across views, as it has different projections on different views. Our method is thus in light of a simple yet effective idea, that a complex 3D hand mesh can be represented by a set of 3D points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encircle the hand. To leverage the power of points, we design two operations: point-based feature fusion and cross-set point attention mechanism. Evaluation on three challenging multi-view datasets shows that POEM outperforms the state-of-the-art in hand mesh reconstruction. Code and models are available for research at https://github.com/lixiny/POEM.