 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars
Feb 02, 2026Generating talking avatars is a fundamental task in video generation. Although existing methods can generate full-body talking avatars with simple human motion, extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects. This challenge stems from the need for environmental perception and the control-quality dilemma in GHOI generation. To address this, we propose a novel dual-stream framework, InteractAvatar, which decouples perception and planning from video synthesis for grounded human-object interaction. Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions. Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions. With a specially designed motion-to-video aligner, PIM and AIM share a similar network structure and enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma. Finally, we establish a benchmark, GroundedInter, for evaluating GHOI video generation. Extensive experiments and comparisons demonstrate the effectiveness of our method in generating grounded human-object interactions for talking avatars. Project page: https://interactavatar.github.io
StreamAvatar: Streaming Diffusion Models for Real-Time Interactive Human Avatars
Dec 26, 2025Real-time, streaming interactive avatars represent a critical yet challenging goal in digital human research. Although diffusion-based human avatar generation methods achieve remarkable success, their non-causal architecture and high computational costs make them unsuitable for streaming. Moreover, existing interactive approaches are typically limited to head-and-shoulder region, limiting their ability to produce gestures and body motions. To address these challenges, we propose a two-stage autoregressive adaptation and acceleration framework that applies autoregressive distillation and adversarial refinement to adapt a high-fidelity human video diffusion model for real-time, interactive streaming. To ensure long-term stability and consistency, we introduce three key components: a Reference Sink, a Reference-Anchored Positional Re-encoding (RAPR) strategy, and a Consistency-Aware Discriminator. Building on this framework, we develop a one-shot, interactive, human avatar model capable of generating both natural talking and listening behaviors with coherent gestures. Extensive experiments demonstrate that our method achieves state-of-the-art performance, surpassing existing approaches in generation quality, real-time efficiency, and interaction naturalness. Project page: https://streamavatar.github.io .
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Dec 22, 2025Despite significant advances in talking avatar generation, existing methods face critical challenges: insufficient text-following capability for diverse actions, lack of temporal alignment between actions and audio content, and dependency on additional control signals such as pose skeletons. We present ActAvatar, a framework that achieves phase-level precision in action control through textual guidance by capturing both action semantics and temporal context. Our approach introduces three core innovations: (1) Phase-Aware Cross-Attention (PACA), which decomposes prompts into a global base block and temporally-anchored phase blocks, enabling the model to concentrate on phase-relevant tokens for precise temporal-semantic alignment; (2) Progressive Audio-Visual Alignment, which aligns modality influence with the hierarchical feature learning process-early layers prioritize text for establishing action structure while deeper layers emphasize audio for refining lip movements, preventing modality interference; (3) A two-stage training strategy that first establishes robust audio-visual correspondence on diverse data, then injects action control through fine-tuning on structured annotations, maintaining both audio-visual alignment and the model's text-following capabilities. Extensive experiments demonstrate that ActAvatar significantly outperforms state-of-the-art methods in both action control and visual quality.
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Dec 20, 2025


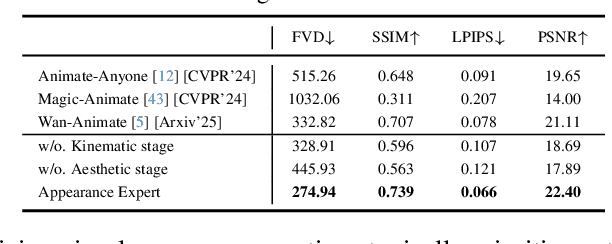
With the rise of online dance-video platforms and rapid advances in AI-generated content (AIGC), music-driven dance generation has emerged as a compelling research direction. Despite substantial progress in related domains such as music-driven 3D dance generation, pose-driven image animation, and audio-driven talking-head synthesis, existing methods cannot be directly adapted to this task. Moreover, the limited studies in this area still struggle to jointly achieve high-quality visual appearance and realistic human motion. Accordingly, we present MACE-Dance, a music-driven dance video generation framework with cascaded Mixture-of-Experts (MoE). The Motion Expert performs music-to-3D motion generation while enforcing kinematic plausibility and artistic expressiveness, whereas the Appearance Expert carries out motion- and reference-conditioned video synthesis, preserving visual identity with spatiotemporal coherence. Specifically, the Motion Expert adopts a diffusion model with a BiMamba-Transformer hybrid architecture and a Guidance-Free Training (GFT) strategy, achieving state-of-the-art (SOTA) performance in 3D dance generation. The Appearance Expert employs a decoupled kinematic-aesthetic fine-tuning strategy, achieving state-of-the-art (SOTA) performance in pose-driven image animation. To better benchmark this task, we curate a large-scale and diverse dataset and design a motion-appearance evaluation protocol. Based on this protocol, MACE-Dance also achieves state-of-the-art performance. Project page: https://macedance.github.io/
Morpheus: A Neural-driven Animatronic Face with Hybrid Actuation and Diverse Emotion Control
Jul 22, 2025Previous animatronic faces struggle to express emotions effectively due to hardware and software limitations. On the hardware side, earlier approaches either use rigid-driven mechanisms, which provide precise control but are difficult to design within constrained spaces, or tendon-driven mechanisms, which are more space-efficient but challenging to control. In contrast, we propose a hybrid actuation approach that combines the best of both worlds. The eyes and mouth-key areas for emotional expression-are controlled using rigid mechanisms for precise movement, while the nose and cheek, which convey subtle facial microexpressions, are driven by strings. This design allows us to build a compact yet versatile hardware platform capable of expressing a wide range of emotions. On the algorithmic side, our method introduces a self-modeling network that maps motor actions to facial landmarks, allowing us to automatically establish the relationship between blendshape coefficients for different facial expressions and the corresponding motor control signals through gradient backpropagation. We then train a neural network to map speech input to corresponding blendshape controls. With our method, we can generate distinct emotional expressions such as happiness, fear, disgust, and anger, from any given sentence, each with nuanced, emotion-specific control signals-a feature that has not been demonstrated in earlier systems. We release the hardware design and code at https://github.com/ZZongzheng0918/Morpheus-Hardware and https://github.com/ZZongzheng0918/Morpheus-Software.
GGTalker: Talking Head Systhesis with Generalizable Gaussian Priors and Identity-Specific Adaptation
Jun 26, 2025Creating high-quality, generalizable speech-driven 3D talking heads remains a persistent challenge. Previous methods achieve satisfactory results for fixed viewpoints and small-scale audio variations, but they struggle with large head rotations and out-of-distribution (OOD) audio. Moreover, they are constrained by the need for time-consuming, identity-specific training. We believe the core issue lies in the lack of sufficient 3D priors, which limits the extrapolation capabilities of synthesized talking heads. To address this, we propose GGTalker, which synthesizes talking heads through a combination of generalizable priors and identity-specific adaptation. We introduce a two-stage Prior-Adaptation training strategy to learn Gaussian head priors and adapt to individual characteristics. We train Audio-Expression and Expression-Visual priors to capture the universal patterns of lip movements and the general distribution of head textures. During the Customized Adaptation, individual speaking styles and texture details are precisely modeled. Additionally, we introduce a color MLP to generate fine-grained, motion-aligned textures and a Body Inpainter to blend rendered results with the background, producing indistinguishable, photorealistic video frames. Comprehensive experiments show that GGTalker achieves state-of-the-art performance in rendering quality, 3D consistency, lip-sync accuracy, and training efficiency.
SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
Jun 17, 2025



Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic results. To address the critical issue of synchronization, identified as the ''devil'' in creating realistic talking heads, we introduce SyncTalk++, which features a Dynamic Portrait Renderer with Gaussian Splatting to ensure consistent subject identity preservation and a Face-Sync Controller that aligns lip movements with speech while innovatively using a 3D facial blendshape model to reconstruct accurate facial expressions. To ensure natural head movements, we propose a Head-Sync Stabilizer, which optimizes head poses for greater stability. Additionally, SyncTalk++ enhances robustness to out-of-distribution (OOD) audio by incorporating an Expression Generator and a Torso Restorer, which generate speech-matched facial expressions and seamless torso regions. Our approach maintains consistency and continuity in visual details across frames and significantly improves rendering speed and quality, achieving up to 101 frames per second. Extensive experiments and user studies demonstrate that SyncTalk++ outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk++.
OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers
May 27, 2025Lip synchronization is the task of aligning a speaker's lip movements in video with corresponding speech audio, and it is essential for creating realistic, expressive video content. However, existing methods often rely on reference frames and masked-frame inpainting, which limit their robustness to identity consistency, pose variations, facial occlusions, and stylized content. In addition, since audio signals provide weaker conditioning than visual cues, lip shape leakage from the original video will affect lip sync quality. In this paper, we present OmniSync, a universal lip synchronization framework for diverse visual scenarios. Our approach introduces a mask-free training paradigm using Diffusion Transformer models for direct frame editing without explicit masks, enabling unlimited-duration inference while maintaining natural facial dynamics and preserving character identity. During inference, we propose a flow-matching-based progressive noise initialization to ensure pose and identity consistency, while allowing precise mouth-region editing. To address the weak conditioning signal of audio, we develop a Dynamic Spatiotemporal Classifier-Free Guidance (DS-CFG) mechanism that adaptively adjusts guidance strength over time and space. We also establish the AIGC-LipSync Benchmark, the first evaluation suite for lip synchronization in diverse AI-generated videos. Extensive experiments demonstrate that OmniSync significantly outperforms prior methods in both visual quality and lip sync accuracy, achieving superior results in both real-world and AI-generated videos.
DualTalk: Dual-Speaker Interaction for 3D Talking Head Conversations
May 26, 2025In face-to-face conversations, individuals need to switch between speaking and listening roles seamlessly. Existing 3D talking head generation models focus solely on speaking or listening, neglecting the natural dynamics of interactive conversation, which leads to unnatural interactions and awkward transitions. To address this issue, we propose a new task -- multi-round dual-speaker interaction for 3D talking head generation -- which requires models to handle and generate both speaking and listening behaviors in continuous conversation. To solve this task, we introduce DualTalk, a novel unified framework that integrates the dynamic behaviors of speakers and listeners to simulate realistic and coherent dialogue interactions. This framework not only synthesizes lifelike talking heads when speaking but also generates continuous and vivid non-verbal feedback when listening, effectively capturing the interplay between the roles. We also create a new dataset featuring 50 hours of multi-round conversations with over 1,000 characters, where participants continuously switch between speaking and listening roles. Extensive experiments demonstrate that our method significantly enhances the naturalness and expressiveness of 3D talking heads in dual-speaker conversations. We recommend watching the supplementary video: https://ziqiaopeng.github.io/dualtalk.
MEGADance: Mixture-of-Experts Architecture for Genre-Aware 3D Dance Generation
May 23, 2025



Music-driven 3D dance generation has attracted increasing attention in recent years, with promising applications in choreography, virtual reality, and creative content creation. Previous research has generated promising realistic dance movement from audio signals. However, traditional methods underutilize genre conditioning, often treating it as auxiliary modifiers rather than core semantic drivers. This oversight compromises music-motion synchronization and disrupts dance genre continuity, particularly during complex rhythmic transitions, thereby leading to visually unsatisfactory effects. To address the challenge, we propose MEGADance, a novel architecture for music-driven 3D dance generation. By decoupling choreographic consistency into dance generality and genre specificity, MEGADance demonstrates significant dance quality and strong genre controllability. It consists of two stages: (1) High-Fidelity Dance Quantization Stage (HFDQ), which encodes dance motions into a latent representation by Finite Scalar Quantization (FSQ) and reconstructs them with kinematic-dynamic constraints, and (2) Genre-Aware Dance Generation Stage (GADG), which maps music into the latent representation by synergistic utilization of Mixture-of-Experts (MoE) mechanism with Mamba-Transformer hybrid backbone. Extensive experiments on the FineDance and AIST++ dataset demonstrate the state-of-the-art performance of MEGADance both qualitatively and quantitatively. Code will be released upon acceptance.