 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePan-LUT: Efficient Pan-sharpening via Learnable Look-Up Tables
Mar 31, 2025
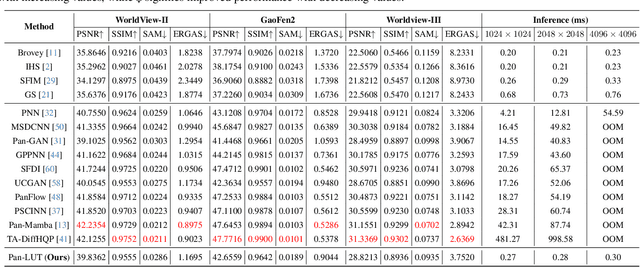
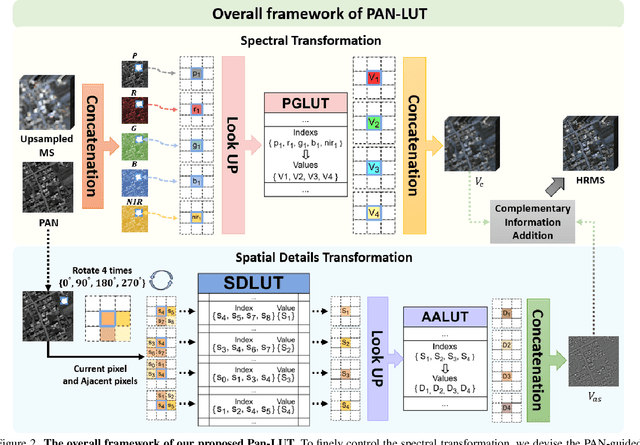

Recently, deep learning-based pan-sharpening algorithms have achieved notable advancements over traditional methods. However, many deep learning-based approaches incur substantial computational overhead during inference, especially with high-resolution images. This excessive computational demand limits the applicability of these methods in real-world scenarios, particularly in the absence of dedicated computing devices such as GPUs and TPUs. To address these challenges, we propose Pan-LUT, a novel learnable look-up table (LUT) framework for pan-sharpening that strikes a balance between performance and computational efficiency for high-resolution remote sensing images. To finely control the spectral transformation, we devise the PAN-guided look-up table (PGLUT) for channel-wise spectral mapping. To effectively capture fine-grained spatial details and adaptively learn local contexts, we introduce the spatial details look-up table (SDLUT) and adaptive aggregation look-up table (AALUT). Our proposed method contains fewer than 300K parameters and processes a 8K resolution image in under 1 ms using a single NVIDIA GeForce RTX 2080 Ti GPU, demonstrating significantly faster performance compared to other methods. Experiments reveal that Pan-LUT efficiently processes large remote sensing images in a lightweight manner, bridging the gap to real-world applications. Furthermore, our model surpasses SOTA methods in full-resolution scenes under real-world conditions, highlighting its effectiveness and efficiency.
ModelGrow: Continual Text-to-Video Pre-training with Model Expansion and Language Understanding Enhancement
Dec 25, 2024Text-to-video (T2V) generation has gained significant attention recently. However, the costs of training a T2V model from scratch remain persistently high, and there is considerable room for improving the generation performance, especially under limited computation resources. This work explores the continual general pre-training of text-to-video models, enabling the model to "grow" its abilities based on a pre-trained foundation, analogous to how humans acquire new knowledge based on past experiences. There is a lack of extensive study of the continual pre-training techniques in T2V generation. In this work, we take the initial step toward exploring this task systematically and propose ModelGrow. Specifically, we break this task into two key aspects: increasing model capacity and improving semantic understanding. For model capacity, we introduce several novel techniques to expand the model size, enabling it to store new knowledge and improve generation performance. For semantic understanding, we propose a method that leverages large language models as advanced text encoders, integrating them into T2V models to enhance language comprehension and guide generation results according to detailed prompts. This approach enables the model to achieve better semantic alignment, particularly in response to complex user prompts. Extensive experiments demonstrate the effectiveness of our method across various metrics. The source code and the model of ModelGrow will be publicly available.
Large Motion Video Autoencoding with Cross-modal Video VAE
Dec 23, 2024



Learning a robust video Variational Autoencoder (VAE) is essential for reducing video redundancy and facilitating efficient video generation. Directly applying image VAEs to individual frames in isolation can result in temporal inconsistencies and suboptimal compression rates due to a lack of temporal compression. Existing Video VAEs have begun to address temporal compression; however, they often suffer from inadequate reconstruction performance. In this paper, we present a novel and powerful video autoencoder capable of high-fidelity video encoding. First, we observe that entangling spatial and temporal compression by merely extending the image VAE to a 3D VAE can introduce motion blur and detail distortion artifacts. Thus, we propose temporal-aware spatial compression to better encode and decode the spatial information. Additionally, we integrate a lightweight motion compression model for further temporal compression. Second, we propose to leverage the textual information inherent in text-to-video datasets and incorporate text guidance into our model. This significantly enhances reconstruction quality, particularly in terms of detail preservation and temporal stability. Third, we further improve the versatility of our model through joint training on both images and videos, which not only enhances reconstruction quality but also enables the model to perform both image and video autoencoding. Extensive evaluations against strong recent baselines demonstrate the superior performance of our method. The project website can be found at~\href{https://yzxing87.github.io/vae/}{https://yzxing87.github.io/vae/}.
High-fidelity 3D GAN Inversion by Pseudo-multi-view Optimization
Nov 29, 2022We present a high-fidelity 3D generative adversarial network (GAN) inversion framework that can synthesize photo-realistic novel views while preserving specific details of the input image. High-fidelity 3D GAN inversion is inherently challenging due to the geometry-texture trade-off in 3D inversion, where overfitting to a single view input image often damages the estimated geometry during the latent optimization. To solve this challenge, we propose a novel pipeline that builds on the pseudo-multi-view estimation with visibility analysis. We keep the original textures for the visible parts and utilize generative priors for the occluded parts. Extensive experiments show that our approach achieves advantageous reconstruction and novel view synthesis quality over state-of-the-art methods, even for images with out-of-distribution textures. The proposed pipeline also enables image attribute editing with the inverted latent code and 3D-aware texture modification. Our approach enables high-fidelity 3D rendering from a single image, which is promising for various applications of AI-generated 3D content.
Shape from Polarization for Complex Scenes in the Wild
Dec 21, 2021


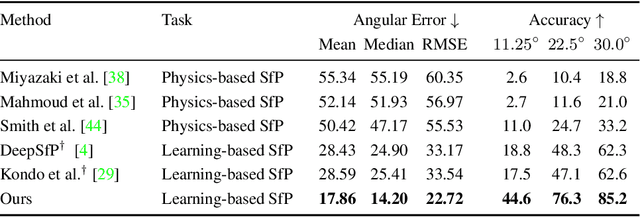
We present a new data-driven approach with physics-based priors to scene-level normal estimation from a single polarization image. Existing shape from polarization (SfP) works mainly focus on estimating the normal of a single object rather than complex scenes in the wild. A key barrier to high-quality scene-level SfP is the lack of real-world SfP data in complex scenes. Hence, we contribute the first real-world scene-level SfP dataset with paired input polarization images and ground-truth normal maps. Then we propose a learning-based framework with a multi-head self-attention module and viewing encoding, which is designed to handle increasing polarization ambiguities caused by complex materials and non-orthographic projection in scene-level SfP. Our trained model can be generalized to far-field outdoor scenes as the relationship between polarized light and surface normals is not affected by distance. Experimental results demonstrate that our approach significantly outperforms existing SfP models on two datasets. Our dataset and source code will be publicly available at \url{https://github.com/ChenyangLEI/sfp-wild}.
Dual-Camera Super-Resolution with Aligned Attention Modules
Sep 06, 2021



We present a novel approach to reference-based super-resolution (RefSR) with the focus on dual-camera super-resolution (DCSR), which utilizes reference images for high-quality and high-fidelity results. Our proposed method generalizes the standard patch-based feature matching with spatial alignment operations. We further explore the dual-camera super-resolution that is one promising application of RefSR, and build a dataset that consists of 146 image pairs from the main and telephoto cameras in a smartphone. To bridge the domain gaps between real-world images and the training images, we propose a self-supervised domain adaptation strategy for real-world images. Extensive experiments on our dataset and a public benchmark demonstrate clear improvement achieved by our method over state of the art in both quantitative evaluation and visual comparisons.
Depth Sensing Beyond LiDAR Range
Apr 07, 2020

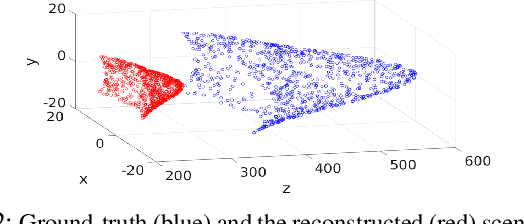

Depth sensing is a critical component of autonomous driving technologies, but today's LiDAR- or stereo camera-based solutions have limited range. We seek to increase the maximum range of self-driving vehicles' depth perception modules for the sake of better safety. To that end, we propose a novel three-camera system that utilizes small field of view cameras. Our system, along with our novel algorithm for computing metric depth, does not require full pre-calibration and can output dense depth maps with practically acceptable accuracy for scenes and objects at long distances not well covered by most commercial LiDARs.
Video Depth Estimation by Fusing Flow-to-Depth Proposals
Dec 30, 2019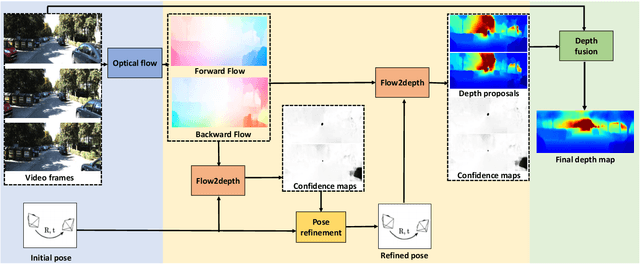
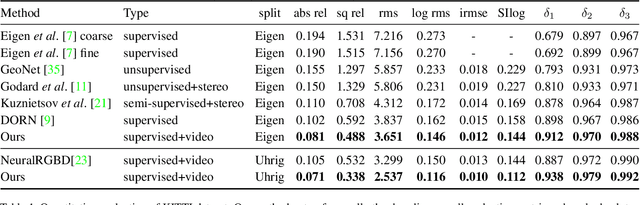
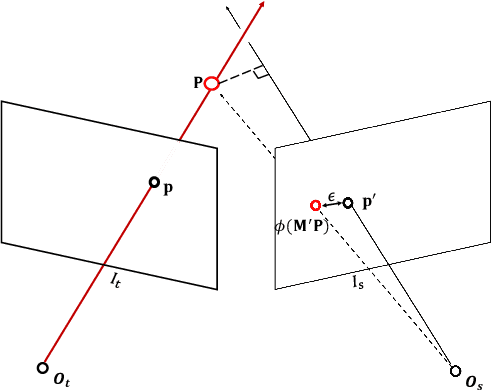

We present an approach with a novel differentiable flow-to-depth layer for video depth estimation. The model consists of a flow-to-depth layer, a camera pose refinement module, and a depth fusion network. Given optical flow and camera pose, our flow-to-depth layer generates depth proposals and the corresponding confidence maps by explicitly solving an epipolar geometry optimization problem. Unlike other methods, our flow-to-depth layer is differentiable, and thus we can refine camera poses by maximizing the aggregated confidence in camera pose refinement module. Our depth fusion network can utilize depth proposals and their confidence maps inferred from different adjacent frames to produce the final depth map. Furthermore, the depth fusion network can additionally take the depth proposals generated by other methods to improve the results further. The experiments on three public datasets show that our approach outperforms state-of-the-art depth estimation methods, and has strong generalization capability: our model trained on KITTI performs well on the unseen Waymo dataset while other methods degenerate a lot.