 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlyAware: Inertia-Aware Aerial Manipulation via Vision-Based Estimation and Post-Grasp Adaptation
Jan 30, 2026Aerial manipulators (AMs) are gaining increasing attention in automated transportation and emergency services due to their superior dexterity compared to conventional multirotor drones. However, their practical deployment is challenged by the complexity of time-varying inertial parameters, which are highly sensitive to payload variations and manipulator configurations. Inspired by human strategies for interacting with unknown objects, this letter presents a novel onboard framework for robust aerial manipulation. The proposed system integrates a vision-based pre-grasp inertia estimation module with a post-grasp adaptation mechanism, enabling real-time estimation and adaptation of inertial dynamics. For control, we develop an inertia-aware adaptive control strategy based on gain scheduling, and assess its robustness via frequency-domain system identification. Our study provides new insights into post-grasp control for AMs, and real-world experiments validate the effectiveness and feasibility of the proposed framework.
Design and Implementation of a High-Precision Wind-Estimation UAV with Onboard Sensors
Dec 11, 2025Accurate real-time wind vector estimation is essential for enhancing the safety, navigation accuracy, and energy efficiency of unmanned aerial vehicles (UAVs). Traditional approaches rely on external sensors or simplify vehicle dynamics, which limits their applicability during agile flight or in resource-constrained platforms. This paper proposes a real-time wind estimation method based solely on onboard sensors. The approach first estimates external aerodynamic forces using a disturbance observer (DOB), and then maps these forces to wind vectors using a thin-plate spline (TPS) model. A custom-designed wind barrel mounted on the UAV enhances aerodynamic sensitivity, further improving estimation accuracy. The system is validated through comprehensive experiments in wind tunnels, indoor and outdoor flights. Experimental results demonstrate that the proposed method achieves consistently high-accuracy wind estimation across controlled and real-world conditions, with speed RMSEs as low as \SI{0.06}{m/s} in wind tunnel tests, \SI{0.22}{m/s} during outdoor hover, and below \SI{0.38}{m/s} in indoor and outdoor dynamic flights, and direction RMSEs under \ang{7.3} across all scenarios, outperforming existing baselines. Moreover, the method provides vertical wind estimates -- unavailable in baselines -- with RMSEs below \SI{0.17}{m/s} even during fast indoor translations.
Shape from Polarization for Complex Scenes in the Wild
Dec 21, 2021


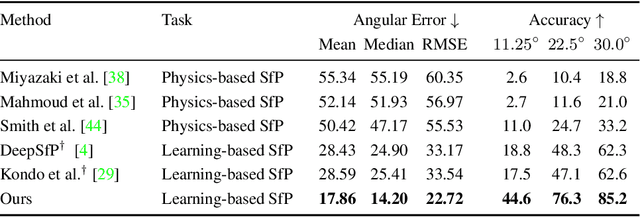
We present a new data-driven approach with physics-based priors to scene-level normal estimation from a single polarization image. Existing shape from polarization (SfP) works mainly focus on estimating the normal of a single object rather than complex scenes in the wild. A key barrier to high-quality scene-level SfP is the lack of real-world SfP data in complex scenes. Hence, we contribute the first real-world scene-level SfP dataset with paired input polarization images and ground-truth normal maps. Then we propose a learning-based framework with a multi-head self-attention module and viewing encoding, which is designed to handle increasing polarization ambiguities caused by complex materials and non-orthographic projection in scene-level SfP. Our trained model can be generalized to far-field outdoor scenes as the relationship between polarized light and surface normals is not affected by distance. Experimental results demonstrate that our approach significantly outperforms existing SfP models on two datasets. Our dataset and source code will be publicly available at \url{https://github.com/ChenyangLEI/sfp-wild}.
Joint Depth and Normal Estimation from Real-world Time-of-flight Raw Data
Aug 08, 2021



We present a novel approach to joint depth and normal estimation for time-of-flight (ToF) sensors. Our model learns to predict the high-quality depth and normal maps jointly from ToF raw sensor data. To achieve this, we meticulously constructed the first large-scale dataset (named ToF-100) with paired raw ToF data and ground-truth high-resolution depth maps provided by an industrial depth camera. In addition, we also design a simple but effective framework for joint depth and normal estimation, applying a robust Chamfer loss via jittering to improve the performance of our model. Our experiments demonstrate that our proposed method can efficiently reconstruct high-resolution depth and normal maps and significantly outperforms state-of-the-art approaches. Our code and data will be available at \url{https://github.com/hkustVisionRr/JointlyDepthNormalEstimation}
Stereo Waterdrop Removal with Row-wise Dilated Attention
Aug 07, 2021
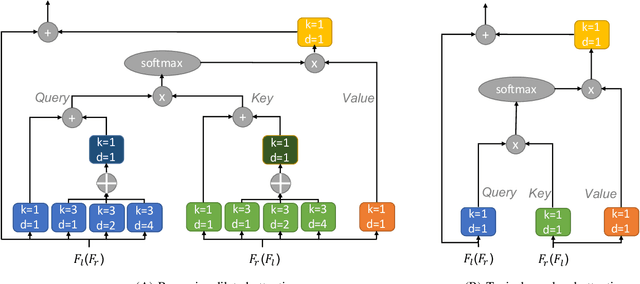


Existing vision systems for autonomous driving or robots are sensitive to waterdrops adhered to windows or camera lenses. Most recent waterdrop removal approaches take a single image as input and often fail to recover the missing content behind waterdrops faithfully. Thus, we propose a learning-based model for waterdrop removal with stereo images. To better detect and remove waterdrops from stereo images, we propose a novel row-wise dilated attention module to enlarge attention's receptive field for effective information propagation between the two stereo images. In addition, we propose an attention consistency loss between the ground-truth disparity map and attention scores to enhance the left-right consistency in stereo images. Because of related datasets' unavailability, we collect a real-world dataset that contains stereo images with and without waterdrops. Extensive experiments on our dataset suggest that our model outperforms state-of-the-art methods both quantitatively and qualitatively. Our source code and the stereo waterdrop dataset are available at \href{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}