 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Dec 12, 2025
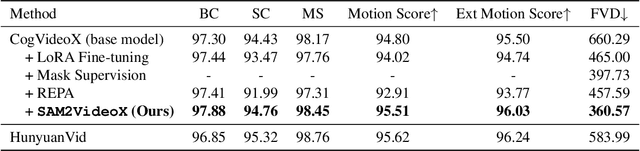
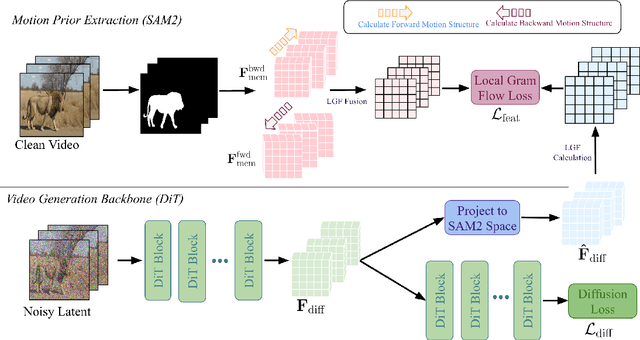
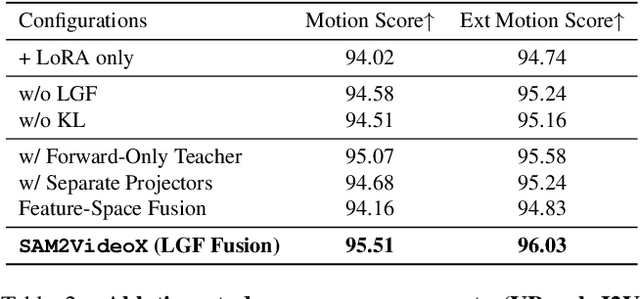
Reality is a dance between rigid constraints and deformable structures. For video models, that means generating motion that preserves fidelity as well as structure. Despite progress in diffusion models, producing realistic structure-preserving motion remains challenging, especially for articulated and deformable objects such as humans and animals. Scaling training data alone, so far, has failed to resolve physically implausible transitions. Existing approaches rely on conditioning with noisy motion representations, such as optical flow or skeletons extracted using an external imperfect model. To address these challenges, we introduce an algorithm to distill structure-preserving motion priors from an autoregressive video tracking model (SAM2) into a bidirectional video diffusion model (CogVideoX). With our method, we train SAM2VideoX, which contains two innovations: (1) a bidirectional feature fusion module that extracts global structure-preserving motion priors from a recurrent model like SAM2; (2) a Local Gram Flow loss that aligns how local features move together. Experiments on VBench and in human studies show that SAM2VideoX delivers consistent gains (+2.60\% on VBench, 21-22\% lower FVD, and 71.4\% human preference) over prior baselines. Specifically, on VBench, we achieve 95.51\%, surpassing REPA (92.91\%) by 2.60\%, and reduce FVD to 360.57, a 21.20\% and 22.46\% improvement over REPA- and LoRA-finetuning, respectively. The project website can be found at https://sam2videox.github.io/ .
You Are What You Bought: Generating Customer Personas for E-commerce Applications
Apr 24, 2025In e-commerce, user representations are essential for various applications. Existing methods often use deep learning techniques to convert customer behaviors into implicit embeddings. However, these embeddings are difficult to understand and integrate with external knowledge, limiting the effectiveness of applications such as customer segmentation, search navigation, and product recommendations. To address this, our paper introduces the concept of the customer persona. Condensed from a customer's numerous purchasing histories, a customer persona provides a multi-faceted and human-readable characterization of specific purchase behaviors and preferences, such as Busy Parents or Bargain Hunters. This work then focuses on representing each customer by multiple personas from a predefined set, achieving readable and informative explicit user representations. To this end, we propose an effective and efficient solution GPLR. To ensure effectiveness, GPLR leverages pre-trained LLMs to infer personas for customers. To reduce overhead, GPLR applies LLM-based labeling to only a fraction of users and utilizes a random walk technique to predict personas for the remaining customers. We further propose RevAff, which provides an absolute error $\epsilon$ guarantee while improving the time complexity of the exact solution by a factor of at least $O(\frac{\epsilon\cdot|E|N}{|E|+N\log N})$, where $N$ represents the number of customers and products, and $E$ represents the interactions between them. We evaluate the performance of our persona-based representation in terms of accuracy and robustness for recommendation and customer segmentation tasks using three real-world e-commerce datasets. Most notably, we find that integrating customer persona representations improves the state-of-the-art graph convolution-based recommendation model by up to 12% in terms of NDCG@K and F1-Score@K.
Large Motion Video Autoencoding with Cross-modal Video VAE
Dec 23, 2024



Learning a robust video Variational Autoencoder (VAE) is essential for reducing video redundancy and facilitating efficient video generation. Directly applying image VAEs to individual frames in isolation can result in temporal inconsistencies and suboptimal compression rates due to a lack of temporal compression. Existing Video VAEs have begun to address temporal compression; however, they often suffer from inadequate reconstruction performance. In this paper, we present a novel and powerful video autoencoder capable of high-fidelity video encoding. First, we observe that entangling spatial and temporal compression by merely extending the image VAE to a 3D VAE can introduce motion blur and detail distortion artifacts. Thus, we propose temporal-aware spatial compression to better encode and decode the spatial information. Additionally, we integrate a lightweight motion compression model for further temporal compression. Second, we propose to leverage the textual information inherent in text-to-video datasets and incorporate text guidance into our model. This significantly enhances reconstruction quality, particularly in terms of detail preservation and temporal stability. Third, we further improve the versatility of our model through joint training on both images and videos, which not only enhances reconstruction quality but also enables the model to perform both image and video autoencoding. Extensive evaluations against strong recent baselines demonstrate the superior performance of our method. The project website can be found at~\href{https://yzxing87.github.io/vae/}{https://yzxing87.github.io/vae/}.
DOZE: A Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments
Feb 29, 2024Zero-Shot Object Navigation (ZSON) requires agents to autonomously locate and approach unseen objects in unfamiliar environments and has emerged as a particularly challenging task within the domain of Embodied AI. Existing datasets for developing ZSON algorithms lack consideration of dynamic obstacles, object attribute diversity, and scene texts, thus exhibiting noticeable discrepancy from real-world situations. To address these issues, we propose a Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments (DOZE) that comprises ten high-fidelity 3D scenes with over 18k tasks, aiming to mimic complex, dynamic real-world scenarios. Specifically, DOZE scenes feature multiple moving humanoid obstacles, a wide array of open-vocabulary objects, diverse distinct-attribute objects, and valuable textual hints. Besides, different from existing datasets that only provide collision checking between the agent and static obstacles, we enhance DOZE by integrating capabilities for detecting collisions between the agent and moving obstacles. This novel functionality enables evaluation of the agents' collision avoidance abilities in dynamic environments. We test four representative ZSON methods on DOZE, revealing substantial room for improvement in existing approaches concerning navigation efficiency, safety, and object recognition accuracy. Our dataset could be found at https://DOZE-Dataset.github.io/.