 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
Geometric-Mean Policy Optimization
Jul 28, 2025Recent advancements, such as Group Relative Policy Optimization (GRPO), have enhanced the reasoning capabilities of large language models by optimizing the arithmetic mean of token-level rewards. However, GRPO suffers from unstable policy updates when processing tokens with outlier importance-weighted rewards, which manifests as extreme importance sampling ratios during training, i.e., the ratio between the sampling probabilities assigned to a token by the current and old policies. In this work, we propose Geometric-Mean Policy Optimization (GMPO), a stabilized variant of GRPO. Instead of optimizing the arithmetic mean, GMPO maximizes the geometric mean of token-level rewards, which is inherently less sensitive to outliers and maintains a more stable range of importance sampling ratio. In addition, we provide comprehensive theoretical and experimental analysis to justify the design and stability benefits of GMPO. Beyond improved stability, GMPO-7B outperforms GRPO by an average of 4.1% on multiple mathematical benchmarks and 1.4% on multimodal reasoning benchmark, including AIME24, AMC, MATH500, OlympiadBench, Minerva, and Geometry3K. Code is available at https://github.com/callsys/GMPO.
Model as a Game: On Numerical and Spatial Consistency for Generative Games
Mar 27, 2025Recent advances in generative models have significantly impacted game generation. However, despite producing high-quality graphics and adequately receiving player input, existing models often fail to maintain fundamental game properties such as numerical and spatial consistency. Numerical consistency ensures gameplay mechanics correctly reflect score changes and other quantitative elements, while spatial consistency prevents jarring scene transitions, providing seamless player experiences. In this paper, we revisit the paradigm of generative games to explore what truly constitutes a Model as a Game (MaaG) with a well-developed mechanism. We begin with an empirical study on ``Traveler'', a 2D game created by an LLM featuring minimalist rules yet challenging generative models in maintaining consistency. Based on the DiT architecture, we design two specialized modules: (1) a numerical module that integrates a LogicNet to determine event triggers, with calculations processed externally as conditions for image generation; and (2) a spatial module that maintains a map of explored areas, retrieving location-specific information during generation and linking new observations to ensure continuity. Experiments across three games demonstrate that our integrated modules significantly enhance performance on consistency metrics compared to baselines, while incurring minimal time overhead during inference.
AvatarArtist: Open-Domain 4D Avatarization
Mar 26, 2025This work focuses on open-domain 4D avatarization, with the purpose of creating a 4D avatar from a portrait image in an arbitrary style. We select parametric triplanes as the intermediate 4D representation and propose a practical training paradigm that takes advantage of both generative adversarial networks (GANs) and diffusion models. Our design stems from the observation that 4D GANs excel at bridging images and triplanes without supervision yet usually face challenges in handling diverse data distributions. A robust 2D diffusion prior emerges as the solution, assisting the GAN in transferring its expertise across various domains. The synergy between these experts permits the construction of a multi-domain image-triplane dataset, which drives the development of a general 4D avatar creator. Extensive experiments suggest that our model, AvatarArtist, is capable of producing high-quality 4D avatars with strong robustness to various source image domains. The code, the data, and the models will be made publicly available to facilitate future studies.
Large Motion Video Autoencoding with Cross-modal Video VAE
Dec 23, 2024



Learning a robust video Variational Autoencoder (VAE) is essential for reducing video redundancy and facilitating efficient video generation. Directly applying image VAEs to individual frames in isolation can result in temporal inconsistencies and suboptimal compression rates due to a lack of temporal compression. Existing Video VAEs have begun to address temporal compression; however, they often suffer from inadequate reconstruction performance. In this paper, we present a novel and powerful video autoencoder capable of high-fidelity video encoding. First, we observe that entangling spatial and temporal compression by merely extending the image VAE to a 3D VAE can introduce motion blur and detail distortion artifacts. Thus, we propose temporal-aware spatial compression to better encode and decode the spatial information. Additionally, we integrate a lightweight motion compression model for further temporal compression. Second, we propose to leverage the textual information inherent in text-to-video datasets and incorporate text guidance into our model. This significantly enhances reconstruction quality, particularly in terms of detail preservation and temporal stability. Third, we further improve the versatility of our model through joint training on both images and videos, which not only enhances reconstruction quality but also enables the model to perform both image and video autoencoding. Extensive evaluations against strong recent baselines demonstrate the superior performance of our method. The project website can be found at~\href{https://yzxing87.github.io/vae/}{https://yzxing87.github.io/vae/}.
TALE: Training-free Cross-domain Image Composition via Adaptive Latent Manipulation and Energy-guided Optimization
Aug 07, 2024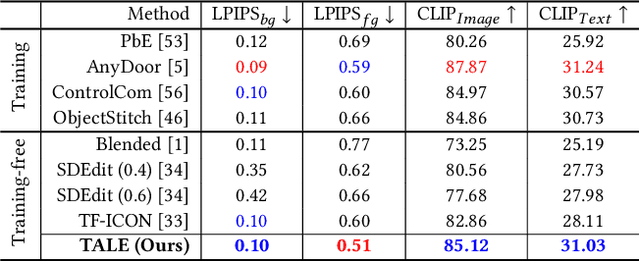
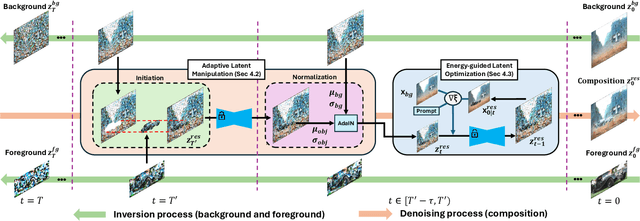

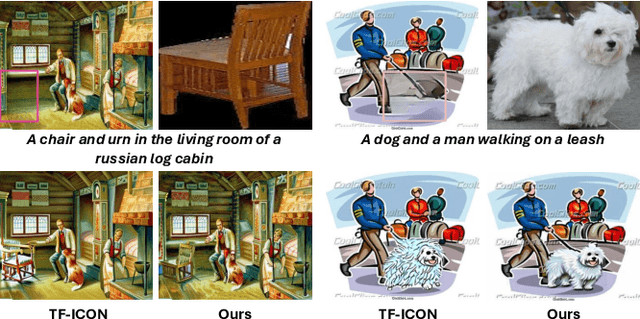
We present TALE, a novel training-free framework harnessing the generative capabilities of text-to-image diffusion models to address the cross-domain image composition task that focuses on flawlessly incorporating user-specified objects into a designated visual contexts regardless of domain disparity. Previous methods often involve either training auxiliary networks or finetuning diffusion models on customized datasets, which are expensive and may undermine the robust textual and visual priors of pre-trained diffusion models. Some recent works attempt to break the barrier by proposing training-free workarounds that rely on manipulating attention maps to tame the denoising process implicitly. However, composing via attention maps does not necessarily yield desired compositional outcomes. These approaches could only retain some semantic information and usually fall short in preserving identity characteristics of input objects or exhibit limited background-object style adaptation in generated images. In contrast, TALE is a novel method that operates directly on latent space to provide explicit and effective guidance for the composition process to resolve these problems. Specifically, we equip TALE with two mechanisms dubbed Adaptive Latent Manipulation and Energy-guided Latent Optimization. The former formulates noisy latents conducive to initiating and steering the composition process by directly leveraging background and foreground latents at corresponding timesteps, and the latter exploits designated energy functions to further optimize intermediate latents conforming to specific conditions that complement the former to generate desired final results. Our experiments demonstrate that TALE surpasses prior baselines and attains state-of-the-art performance in image-guided composition across various photorealistic and artistic domains.
LLMs Meet Multimodal Generation and Editing: A Survey
May 29, 2024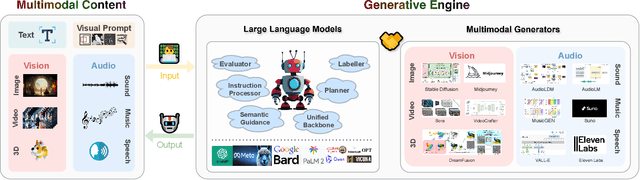
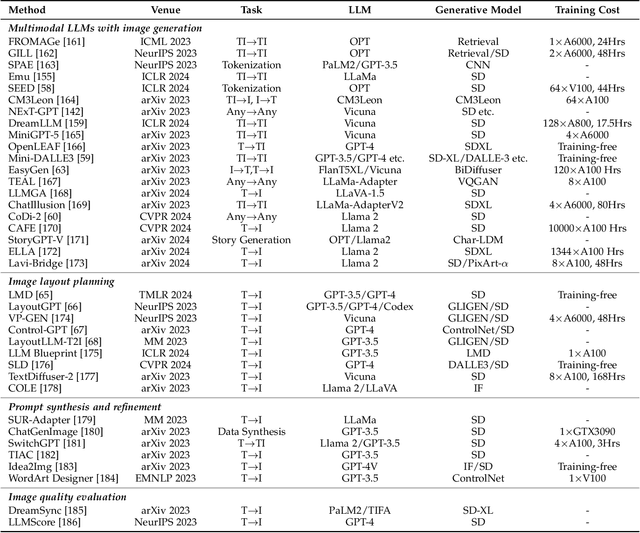
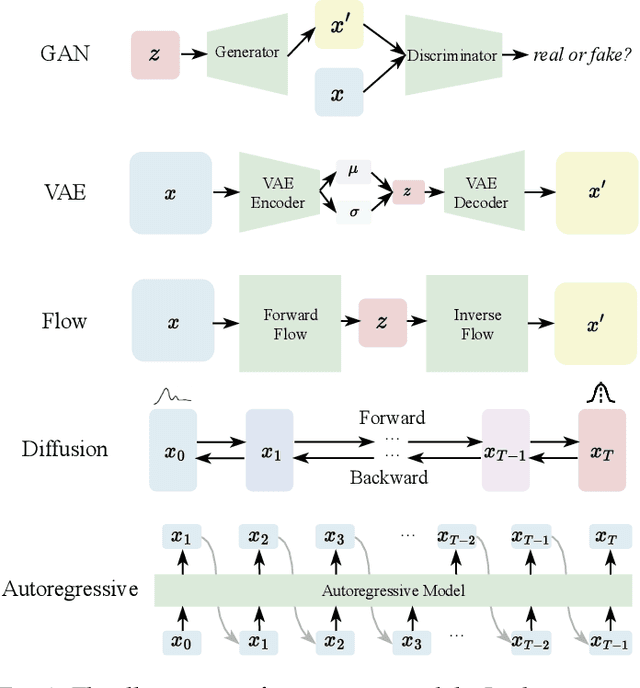
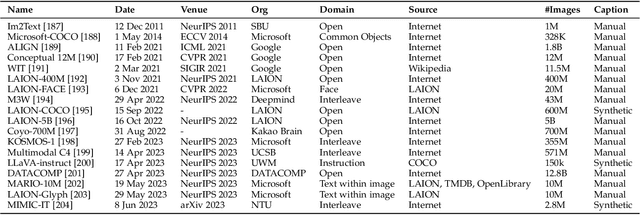
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on understanding. This survey elaborates on multimodal generation across different domains, including image, video, 3D, and audio, where we highlight the notable advancements with milestone works in these fields. Specifically, we exhaustively investigate the key technical components behind methods and multimodal datasets utilized in these studies. Moreover, we dig into tool-augmented multimodal agents that can use existing generative models for human-computer interaction. Lastly, we also comprehensively discuss the advancement in AI safety and investigate emerging applications as well as future prospects. Our work provides a systematic and insightful overview of multimodal generation, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
Nov 28, 2023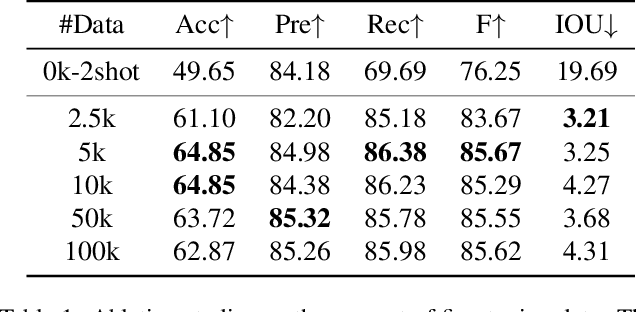
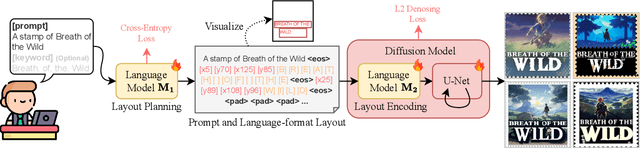
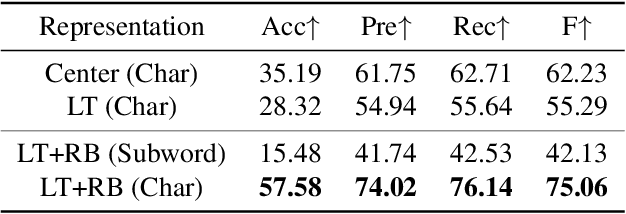
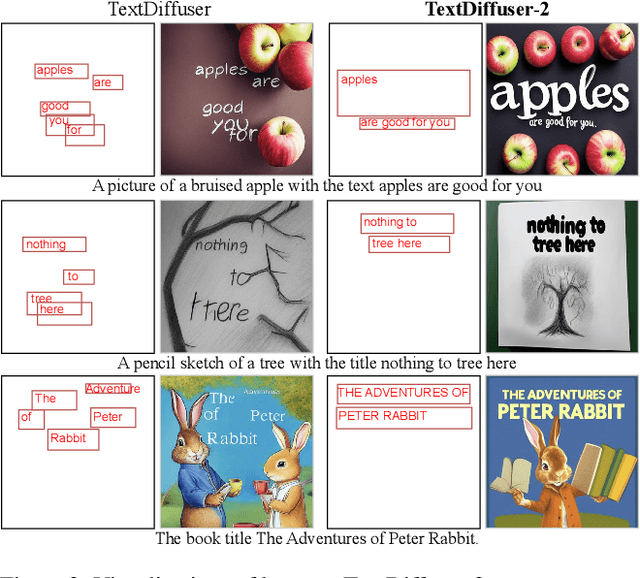
The diffusion model has been proven a powerful generative model in recent years, yet remains a challenge in generating visual text. Several methods alleviated this issue by incorporating explicit text position and content as guidance on where and what text to render. However, these methods still suffer from several drawbacks, such as limited flexibility and automation, constrained capability of layout prediction, and restricted style diversity. In this paper, we present TextDiffuser-2, aiming to unleash the power of language models for text rendering. Firstly, we fine-tune a large language model for layout planning. The large language model is capable of automatically generating keywords for text rendering and also supports layout modification through chatting. Secondly, we utilize the language model within the diffusion model to encode the position and texts at the line level. Unlike previous methods that employed tight character-level guidance, this approach generates more diverse text images. We conduct extensive experiments and incorporate user studies involving human participants as well as GPT-4V, validating TextDiffuser-2's capacity to achieve a more rational text layout and generation with enhanced diversity. The code and model will be available at \url{https://aka.ms/textdiffuser-2}.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
TextDiffuser: Diffusion Models as Text Painters
May 24, 2023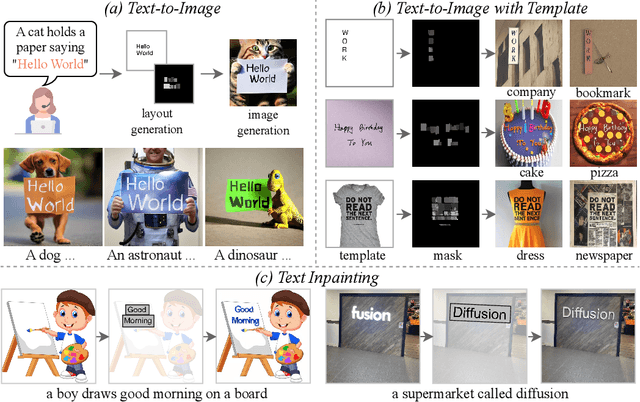
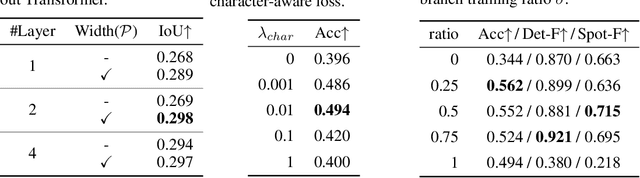
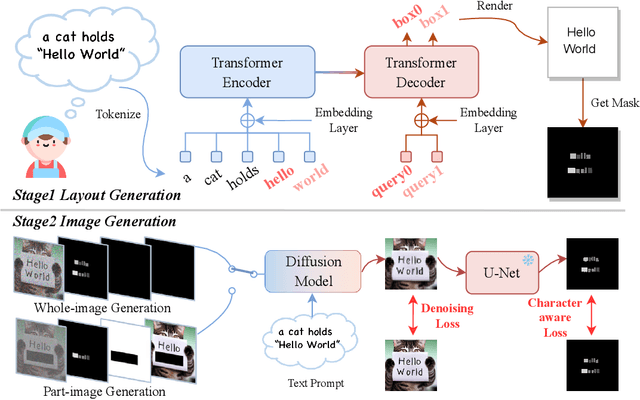
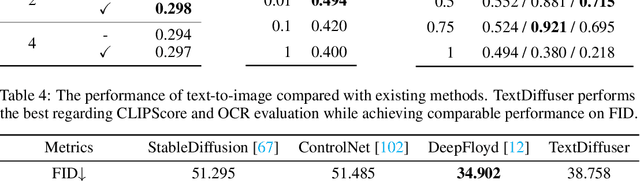
Diffusion models have gained increasing attention for their impressive generation abilities but currently struggle with rendering accurate and coherent text. To address this issue, we introduce TextDiffuser, focusing on generating images with visually appealing text that is coherent with backgrounds. TextDiffuser consists of two stages: first, a Transformer model generates the layout of keywords extracted from text prompts, and then diffusion models generate images conditioned on the text prompt and the generated layout. Additionally, we contribute the first large-scale text images dataset with OCR annotations, MARIO-10M, containing 10 million image-text pairs with text recognition, detection, and character-level segmentation annotations. We further collect the MARIO-Eval benchmark to serve as a comprehensive tool for evaluating text rendering quality. Through experiments and user studies, we show that TextDiffuser is flexible and controllable to create high-quality text images using text prompts alone or together with text template images, and conduct text inpainting to reconstruct incomplete images with text. The code, model, and dataset will be available at \url{https://aka.ms/textdiffuser}.