 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpA2V: Harnessing Spatial Auditory Cues for Audio-driven Spatially-aware Video Generation
Aug 01, 2025Audio-driven video generation aims to synthesize realistic videos that align with input audio recordings, akin to the human ability to visualize scenes from auditory input. However, existing approaches predominantly focus on exploring semantic information, such as the classes of sounding sources present in the audio, limiting their ability to generate videos with accurate content and spatial composition. In contrast, we humans can not only naturally identify the semantic categories of sounding sources but also determine their deeply encoded spatial attributes, including locations and movement directions. This useful information can be elucidated by considering specific spatial indicators derived from the inherent physical properties of sound, such as loudness or frequency. As prior methods largely ignore this factor, we present SpA2V, the first framework explicitly exploits these spatial auditory cues from audios to generate videos with high semantic and spatial correspondence. SpA2V decomposes the generation process into two stages: 1) Audio-guided Video Planning: We meticulously adapt a state-of-the-art MLLM for a novel task of harnessing spatial and semantic cues from input audio to construct Video Scene Layouts (VSLs). This serves as an intermediate representation to bridge the gap between the audio and video modalities. 2) Layout-grounded Video Generation: We develop an efficient and effective approach to seamlessly integrate VSLs as conditional guidance into pre-trained diffusion models, enabling VSL-grounded video generation in a training-free manner. Extensive experiments demonstrate that SpA2V excels in generating realistic videos with semantic and spatial alignment to the input audios.
TALE: Training-free Cross-domain Image Composition via Adaptive Latent Manipulation and Energy-guided Optimization
Aug 07, 2024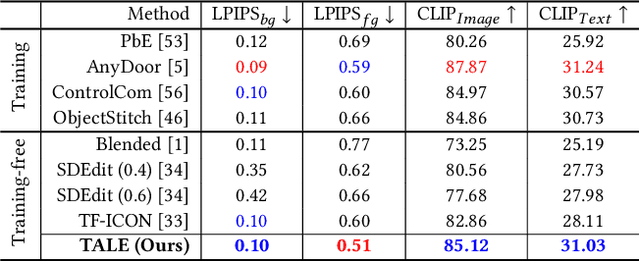
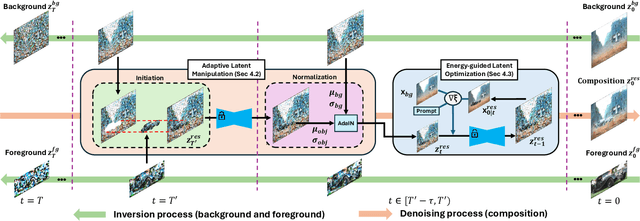

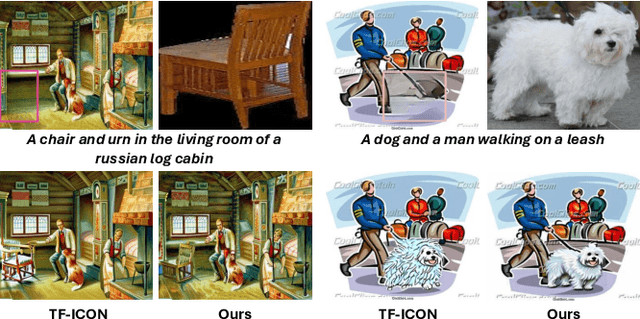
We present TALE, a novel training-free framework harnessing the generative capabilities of text-to-image diffusion models to address the cross-domain image composition task that focuses on flawlessly incorporating user-specified objects into a designated visual contexts regardless of domain disparity. Previous methods often involve either training auxiliary networks or finetuning diffusion models on customized datasets, which are expensive and may undermine the robust textual and visual priors of pre-trained diffusion models. Some recent works attempt to break the barrier by proposing training-free workarounds that rely on manipulating attention maps to tame the denoising process implicitly. However, composing via attention maps does not necessarily yield desired compositional outcomes. These approaches could only retain some semantic information and usually fall short in preserving identity characteristics of input objects or exhibit limited background-object style adaptation in generated images. In contrast, TALE is a novel method that operates directly on latent space to provide explicit and effective guidance for the composition process to resolve these problems. Specifically, we equip TALE with two mechanisms dubbed Adaptive Latent Manipulation and Energy-guided Latent Optimization. The former formulates noisy latents conducive to initiating and steering the composition process by directly leveraging background and foreground latents at corresponding timesteps, and the latter exploits designated energy functions to further optimize intermediate latents conforming to specific conditions that complement the former to generate desired final results. Our experiments demonstrate that TALE surpasses prior baselines and attains state-of-the-art performance in image-guided composition across various photorealistic and artistic domains.
Cross-Cluster Shifting for Efficient and Effective 3D Object Detection in Autonomous Driving
Mar 10, 2024



We present a new 3D point-based detector model, named Shift-SSD, for precise 3D object detection in autonomous driving. Traditional point-based 3D object detectors often employ architectures that rely on a progressive downsampling of points. While this method effectively reduces computational demands and increases receptive fields, it will compromise the preservation of crucial non-local information for accurate 3D object detection, especially in the complex driving scenarios. To address this, we introduce an intriguing Cross-Cluster Shifting operation to unleash the representation capacity of the point-based detector by efficiently modeling longer-range inter-dependency while including only a negligible overhead. Concretely, the Cross-Cluster Shifting operation enhances the conventional design by shifting partial channels from neighboring clusters, which enables richer interaction with non-local regions and thus enlarges the receptive field of clusters. We conduct extensive experiments on the KITTI, Waymo, and nuScenes datasets, and the results demonstrate the state-of-the-art performance of Shift-SSD in both detection accuracy and runtime efficiency.