 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse-Engineering Model Editing on Language Models
Feb 07, 2026Large language models (LLMs) are pretrained on corpora containing trillions of tokens and, therefore, inevitably memorize sensitive information. Locate-then-edit methods, as a mainstream paradigm of model editing, offer a promising solution by modifying model parameters without retraining. However, in this work, we reveal a critical vulnerability of this paradigm: the parameter updates inadvertently serve as a side channel, enabling attackers to recover the edited data. We propose a two-stage reverse-engineering attack named \textit{KSTER} (\textbf{K}ey\textbf{S}paceRecons\textbf{T}ruction-then-\textbf{E}ntropy\textbf{R}eduction) that leverages the low-rank structure of these updates. First, we theoretically show that the row space of the update matrix encodes a ``fingerprint" of the edited subjects, enabling accurate subject recovery via spectral analysis. Second, we introduce an entropy-based prompt recovery attack that reconstructs the semantic context of the edit. Extensive experiments on multiple LLMs demonstrate that our attacks can recover edited data with high success rates. Furthermore, we propose \textit{subspace camouflage}, a defense strategy that obfuscates the update fingerprint with semantic decoys. This approach effectively mitigates reconstruction risks without compromising editing utility. Our code is available at https://github.com/reanatom/EditingAtk.git.
NetRoller: Interfacing General and Specialized Models for End-to-End Autonomous Driving
Jun 17, 2025Integrating General Models (GMs) such as Large Language Models (LLMs), with Specialized Models (SMs) in autonomous driving tasks presents a promising approach to mitigating challenges in data diversity and model capacity of existing specialized driving models. However, this integration leads to problems of asynchronous systems, which arise from the distinct characteristics inherent in GMs and SMs. To tackle this challenge, we propose NetRoller, an adapter that incorporates a set of novel mechanisms to facilitate the seamless integration of GMs and specialized driving models. Specifically, our mechanisms for interfacing the asynchronous GMs and SMs are organized into three key stages. NetRoller first harvests semantically rich and computationally efficient representations from the reasoning processes of LLMs using an early stopping mechanism, which preserves critical insights on driving context while maintaining low overhead. It then applies learnable query embeddings, nonsensical embeddings, and positional layer embeddings to facilitate robust and efficient cross-modality translation. At last, it employs computationally efficient Query Shift and Feature Shift mechanisms to enhance the performance of SMs through few-epoch fine-tuning. Based on the mechanisms formalized in these three stages, NetRoller enables specialized driving models to operate at their native frequencies while maintaining situational awareness of the GM. Experiments conducted on the nuScenes dataset demonstrate that integrating GM through NetRoller significantly improves human similarity and safety in planning tasks, and it also achieves noticeable precision improvements in detection and mapping tasks for end-to-end autonomous driving. The code and models are available at https://github.com/Rex-sys-hk/NetRoller .
EC-LDA : Label Distribution Inference Attack against Federated Graph Learning with Embedding Compression
May 21, 2025Graph Neural Networks (GNNs) have been widely used for graph analysis. Federated Graph Learning (FGL) is an emerging learning framework to collaboratively train graph data from various clients. However, since clients are required to upload model parameters to the server in each round, this provides the server with an opportunity to infer each client's data privacy. In this paper, we focus on label distribution attacks(LDAs) that aim to infer the label distributions of the clients' local data. We take the first step to attack client's label distributions in FGL. Firstly, we observe that the effectiveness of LDA is closely related to the variance of node embeddings in GNNs. Next, we analyze the relation between them and we propose a new attack named EC-LDA, which significantly improves the attack effectiveness by compressing node embeddings. Thirdly, extensive experiments on node classification and link prediction tasks across six widely used graph datasets show that EC-LDA outperforms the SOTA LDAs. For example, EC-LDA attains optimal values under both Cos-sim and JS-div evaluation metrics in the CoraFull and LastFM datasets. Finally, we explore the robustness of EC-LDA under differential privacy protection.
CBNN: 3-Party Secure Framework for Customized Binary Neural Networks Inference
Dec 21, 2024



Binarized Neural Networks (BNN) offer efficient implementations for machine learning tasks and facilitate Privacy-Preserving Machine Learning (PPML) by simplifying operations with binary values. Nevertheless, challenges persist in terms of communication and accuracy in their application scenarios. In this work, we introduce CBNN, a three-party secure computation framework tailored for efficient BNN inference. Leveraging knowledge distillation and separable convolutions, CBNN transforms standard BNNs into MPC-friendly customized BNNs, maintaining high utility. It performs secure inference using optimized protocols for basic operations. Specifically, CBNN enhances linear operations with replicated secret sharing and MPC-friendly convolutions, while introducing a novel secure activation function to optimize non-linear operations. We demonstrate the effectiveness of CBNN by transforming and securely implementing several typical BNN models. Experimental results indicate that CBNN maintains impressive performance even after customized binarization and security measures
Hints of Prompt: Enhancing Visual Representation for Multimodal LLMs in Autonomous Driving
Nov 20, 2024



In light of the dynamic nature of autonomous driving environments and stringent safety requirements, general MLLMs combined with CLIP alone often struggle to represent driving-specific scenarios accurately, particularly in complex interactions and long-tail cases. To address this, we propose the Hints of Prompt (HoP) framework, which introduces three key enhancements: Affinity hint to emphasize instance-level structure by strengthening token-wise connections, Semantic hint to incorporate high-level information relevant to driving-specific cases, such as complex interactions among vehicles and traffic signs, and Question hint to align visual features with the query context, focusing on question-relevant regions. These hints are fused through a Hint Fusion module, enriching visual representations and enhancing multimodal reasoning for autonomous driving VQA tasks. Extensive experiments confirm the effectiveness of the HoP framework, showing it significantly outperforms previous state-of-the-art methods across all key metrics.
Single-cell Curriculum Learning-based Deep Graph Embedding Clustering
Aug 20, 2024



The swift advancement of single-cell RNA sequencing (scRNA-seq) technologies enables the investigation of cellular-level tissue heterogeneity. Cell annotation significantly contributes to the extensive downstream analysis of scRNA-seq data. However, The analysis of scRNA-seq for biological inference presents challenges owing to its intricate and indeterminate data distribution, characterized by a substantial volume and a high frequency of dropout events. Furthermore, the quality of training samples varies greatly, and the performance of the popular scRNA-seq data clustering solution GNN could be harmed by two types of low-quality training nodes: 1) nodes on the boundary; 2) nodes that contribute little additional information to the graph. To address these problems, we propose a single-cell curriculum learning-based deep graph embedding clustering (scCLG). We first propose a Chebyshev graph convolutional autoencoder with multi-decoder (ChebAE) that combines three optimization objectives corresponding to three decoders, including topology reconstruction loss of cell graphs, zero-inflated negative binomial (ZINB) loss, and clustering loss, to learn cell-cell topology representation. Meanwhile, we employ a selective training strategy to train GNN based on the features and entropy of nodes and prune the difficult nodes based on the difficulty scores to keep the high-quality graph. Empirical results on a variety of gene expression datasets show that our model outperforms state-of-the-art methods.
Learning High-resolution Vector Representation from Multi-Camera Images for 3D Object Detection
Jul 22, 2024The Bird's-Eye-View (BEV) representation is a critical factor that directly impacts the 3D object detection performance, but the traditional BEV grid representation induces quadratic computational cost as the spatial resolution grows. To address this limitation, we present a new camera-based 3D object detector with high-resolution vector representation: VectorFormer. The presented high-resolution vector representation is combined with the lower-resolution BEV representation to efficiently exploit 3D geometry from multi-camera images at a high resolution through our two novel modules: vector scattering and gathering. To this end, the learned vector representation with richer scene contexts can serve as the decoding query for final predictions. We conduct extensive experiments on the nuScenes dataset and demonstrate state-of-the-art performance in NDS and inference time. Furthermore, we investigate query-BEV-based methods incorporated with our proposed vector representation and observe a consistent performance improvement.
Cross-Cluster Shifting for Efficient and Effective 3D Object Detection in Autonomous Driving
Mar 10, 2024



We present a new 3D point-based detector model, named Shift-SSD, for precise 3D object detection in autonomous driving. Traditional point-based 3D object detectors often employ architectures that rely on a progressive downsampling of points. While this method effectively reduces computational demands and increases receptive fields, it will compromise the preservation of crucial non-local information for accurate 3D object detection, especially in the complex driving scenarios. To address this, we introduce an intriguing Cross-Cluster Shifting operation to unleash the representation capacity of the point-based detector by efficiently modeling longer-range inter-dependency while including only a negligible overhead. Concretely, the Cross-Cluster Shifting operation enhances the conventional design by shifting partial channels from neighboring clusters, which enables richer interaction with non-local regions and thus enlarges the receptive field of clusters. We conduct extensive experiments on the KITTI, Waymo, and nuScenes datasets, and the results demonstrate the state-of-the-art performance of Shift-SSD in both detection accuracy and runtime efficiency.
DPSUR: Accelerating Differentially Private Stochastic Gradient Descent Using Selective Update and Release
Nov 29, 2023Machine learning models are known to memorize private data to reduce their training loss, which can be inadvertently exploited by privacy attacks such as model inversion and membership inference. To protect against these attacks, differential privacy (DP) has become the de facto standard for privacy-preserving machine learning, particularly those popular training algorithms using stochastic gradient descent, such as DPSGD. Nonetheless, DPSGD still suffers from severe utility loss due to its slow convergence. This is partially caused by the random sampling, which brings bias and variance to the gradient, and partially by the Gaussian noise, which leads to fluctuation of gradient updates. Our key idea to address these issues is to apply selective updates to the model training, while discarding those useless or even harmful updates. Motivated by this, this paper proposes DPSUR, a Differentially Private training framework based on Selective Updates and Release, where the gradient from each iteration is evaluated based on a validation test, and only those updates leading to convergence are applied to the model. As such, DPSUR ensures the training in the right direction and thus can achieve faster convergence than DPSGD. The main challenges lie in two aspects -- privacy concerns arising from gradient evaluation, and gradient selection strategy for model update. To address the challenges, DPSUR introduces a clipping strategy for update randomization and a threshold mechanism for gradient selection. Experiments conducted on MNIST, FMNIST, CIFAR-10, and IMDB datasets show that DPSUR significantly outperforms previous works in terms of convergence speed and model utility.
DeepEMplanner: An End-to-End EM Motion Planner with Iterative Interactions
Nov 29, 2023

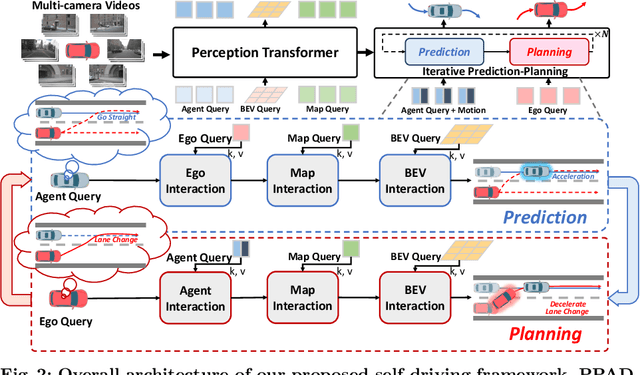

Motion planning is a computational problem that finds a sequence of valid trajectories, often based on surrounding agents' forecasting, environmental understanding, and historical and future contexts. It can also be viewed as a game in which agents continuously plan their next move according to other agents' intentions and the encountering environment, further achieving their ultimate goals through incremental actions. To model the dynamic planning and interaction process, we propose a novel framework, DeepEMplanner, which takes the stepwise interaction into account for fine-grained behavior learning. The ego vehicle maximizes each step motion to reach its eventual driving outcome based on the stepwise expectation from agents and its upcoming road conditions. On the other hand, the agents also follow the same philosophy to maximize their stepwise behavior under the encountering environment and the expectations from ego and other agents. Our DeepEMplanner models the interactions among ego, agents, and the dynamic environment in an autoregressive manner by interleaving the Expectation and Maximization processes. Further, we design ego-to-agents, ego-to-map, and ego-to-BEV interaction mechanisms with hierarchical dynamic key objects attention to better model the interactions. Experiments on the nuScenes benchmark show that our approach achieves state-of-the-art results.