 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LLM-Based RTL Code Optimization Via Timing Logic Metamorphosis
Jul 22, 2025



Register Transfer Level(RTL) code optimization is crucial for achieving high performance and low power consumption in digital circuit design. However, traditional optimization methods often rely on manual tuning and heuristics, which can be time-consuming and error-prone. Recent studies proposed to leverage Large Language Models(LLMs) to assist in RTL code optimization. LLMs can generate optimized code snippets based on natural language descriptions, potentially speeding up the optimization process. However, existing approaches have not thoroughly evaluated the effectiveness of LLM-Based code optimization methods for RTL code with complex timing logic. To address this gap, we conducted a comprehensive empirical investigation to assess the capability of LLM-Based RTL code optimization methods in handling RTL code with complex timing logic. In this study, we first propose a new benchmark for RTL optimization evaluation. It comprises four subsets, each corresponding to a specific area of RTL code optimization. Then we introduce a method based on metamorphosis to systematically evaluate the effectiveness of LLM-Based RTL code optimization methods.Our key insight is that the optimization effectiveness should remain consistent for semantically equivalent but more complex code. After intensive experiments, we revealed several key findings. (1) LLM-Based RTL optimization methods can effectively optimize logic operations and outperform existing compiler-based methods. (2) LLM-Based RTL optimization methods do not perform better than existing compiler-based methods on RTL code with complex timing logic, particularly in timing control flow optimization and clock domain optimization. This is primarily attributed to the challenges LLMs face in understanding timing logic in RTL code. Based on these findings, we provide insights for further research in leveraging LLMs for RTL code optimization.
SGDPO: Self-Guided Direct Preference Optimization for Language Model Alignment
May 18, 2025Direct Preference Optimization (DPO) is broadly utilized for aligning Large Language Models (LLMs) with human values because of its flexibility. Despite its effectiveness, it has been observed that the capability of DPO to generate human-preferred response is limited and the results of DPO are far from resilient. To address these limitations, in this paper we propose a novel Self-Guided Direct Preference Optimization algorithm, i.e., SGDPO, which incorporates a pilot term to steer the gradient flow during the optimization process, allowing for fine-grained control over the updates of chosen and rejected rewards. We provide a detailed theoretical analysis of our proposed method and elucidate its operational mechanism. Furthermore, we conduct comprehensive experiments on various models and benchmarks. The extensive experimental results demonstrate the consistency between the empirical results and our theoretical analysis and confirm the effectiveness of our proposed approach (up to 9.19% higher score).
PSC: Extending Context Window of Large Language Models via Phase Shift Calibration
May 18, 2025Rotary Position Embedding (RoPE) is an efficient position encoding approach and is widely utilized in numerous large language models (LLMs). Recently, a lot of methods have been put forward to further expand the context window based on RoPE. The core concept of those methods is to predefine or search for a set of factors to rescale the base frequencies of RoPE. Nevertheless, it is quite a challenge for existing methods to predefine an optimal factor due to the exponential search space. In view of this, we introduce PSC (Phase Shift Calibration), a small module for calibrating the frequencies predefined by existing methods. With the employment of PSC, we demonstrate that many existing methods can be further enhanced, like PI, YaRN, and LongRoPE. We conducted extensive experiments across multiple models and tasks. The results demonstrate that (1) when PSC is enabled, the comparative reductions in perplexity increase as the context window size is varied from 16k, to 32k, and up to 64k. (2) Our approach is broadly applicable and exhibits robustness across a variety of models and tasks. The code can be found at https://github.com/WNQzhu/PSC.
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024



With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.
DPSUR: Accelerating Differentially Private Stochastic Gradient Descent Using Selective Update and Release
Nov 29, 2023Machine learning models are known to memorize private data to reduce their training loss, which can be inadvertently exploited by privacy attacks such as model inversion and membership inference. To protect against these attacks, differential privacy (DP) has become the de facto standard for privacy-preserving machine learning, particularly those popular training algorithms using stochastic gradient descent, such as DPSGD. Nonetheless, DPSGD still suffers from severe utility loss due to its slow convergence. This is partially caused by the random sampling, which brings bias and variance to the gradient, and partially by the Gaussian noise, which leads to fluctuation of gradient updates. Our key idea to address these issues is to apply selective updates to the model training, while discarding those useless or even harmful updates. Motivated by this, this paper proposes DPSUR, a Differentially Private training framework based on Selective Updates and Release, where the gradient from each iteration is evaluated based on a validation test, and only those updates leading to convergence are applied to the model. As such, DPSUR ensures the training in the right direction and thus can achieve faster convergence than DPSGD. The main challenges lie in two aspects -- privacy concerns arising from gradient evaluation, and gradient selection strategy for model update. To address the challenges, DPSUR introduces a clipping strategy for update randomization and a threshold mechanism for gradient selection. Experiments conducted on MNIST, FMNIST, CIFAR-10, and IMDB datasets show that DPSUR significantly outperforms previous works in terms of convergence speed and model utility.
Center-of-Mass-based Robust Grasp Pose Adaptation Using RGBD Camera and Force/Torque Sensing
May 02, 2022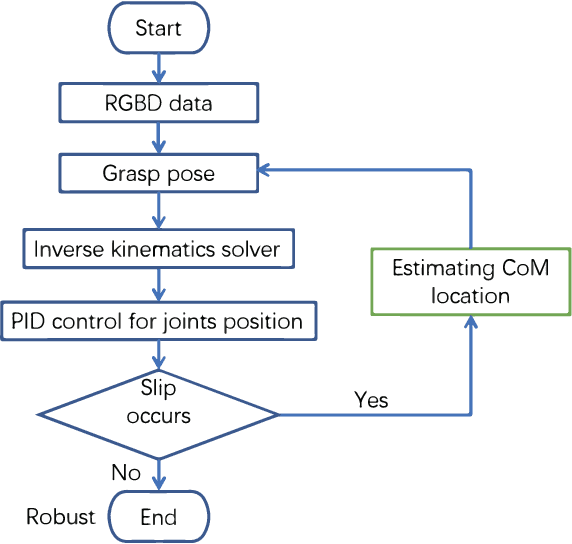
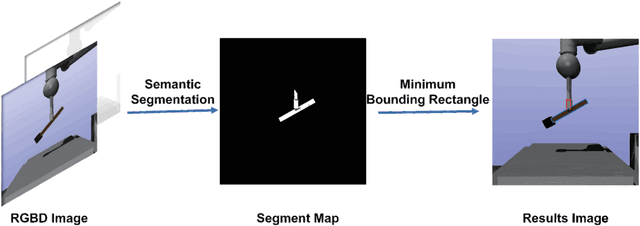
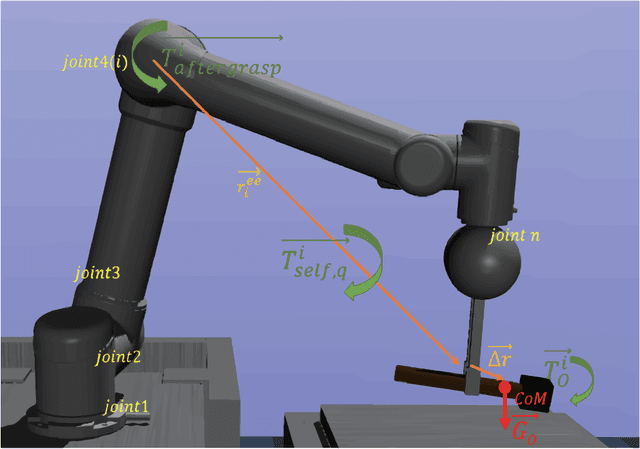
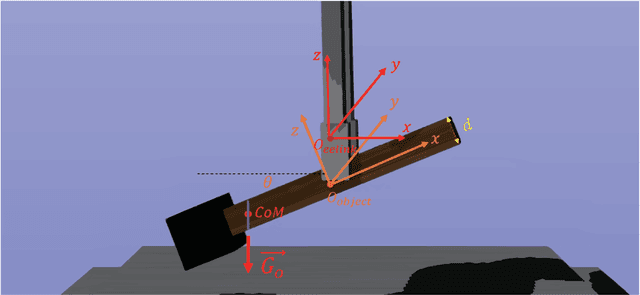
Object dropping may occur when the robotic arm grasps objects with uneven mass distribution due to additional moments generated by objects' gravity. To solve this problem, we present a novel work that does not require extra wrist and tactile sensors and large amounts of experiments for learning. First, we obtain the center-of-mass position of the rod object using the widely fixed joint torque sensors on the robot arm and RGBD camera. Further, we give the strategy of grasping to improve grasp stability. Simulation experiments are performed in "Mujoco". Results demonstrate that our work is effective in enhancing grasping robustness.
Feature Space Singularity for Out-of-Distribution Detection
Dec 16, 2020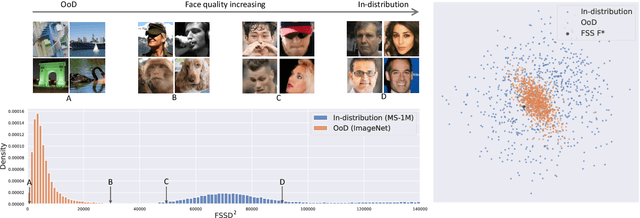
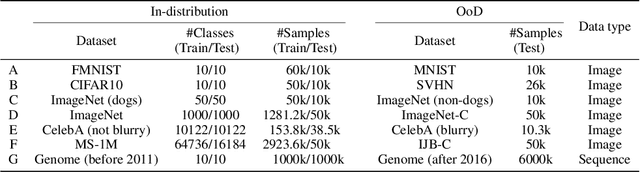
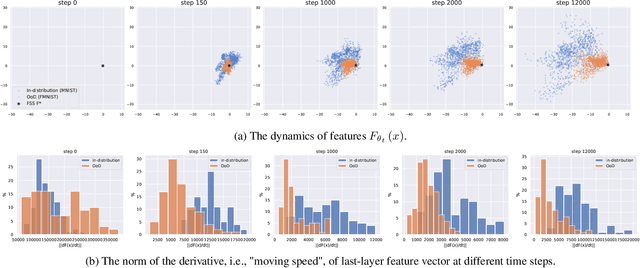
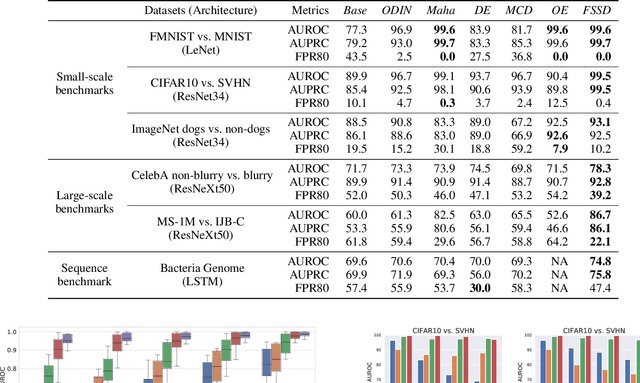
Out-of-Distribution (OoD) detection is important for building safe artificial intelligence systems. However, current OoD detection methods still cannot meet the performance requirements for practical deployment. In this paper, we propose a simple yet effective algorithm based on a novel observation: in a trained neural network, OoD samples with bounded norms well concentrate in the feature space. We call the center of OoD features the Feature Space Singularity (FSS), and denote the distance of a sample feature to FSS as FSSD. Then, OoD samples can be identified by taking a threshold on the FSSD. Our analysis of the phenomenon reveals why our algorithm works. We demonstrate that our algorithm achieves state-of-the-art performance on various OoD detection benchmarks. Besides, FSSD also enjoys robustness to slight corruption in test data and can be further enhanced by ensembling. These make FSSD a promising algorithm to be employed in real world. We release our code at \url{https://github.com/megvii-research/FSSD_OoD_Detection}.
Learning Theory and Algorithms for Revenue Management in Sponsored Search
Jul 05, 2018
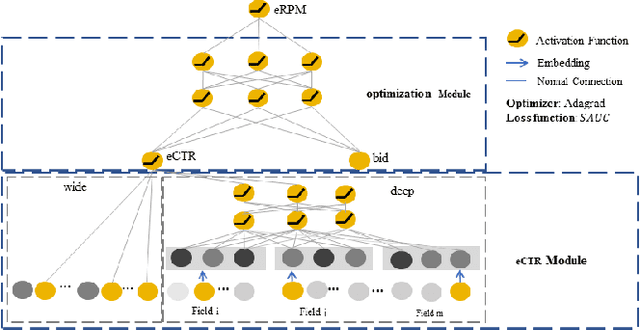
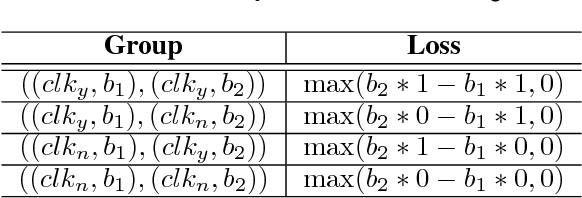

Online advertisement is the main source of revenue for Internet business. Advertisers are typically ranked according to a score that takes into account their bids and potential click-through rates(eCTR). Generally, the likelihood that a user clicks on an ad is often modeled by optimizing for the click through rates rather than the performance of the auction in which the click through rates will be used. This paper attempts to eliminate this dis-connection by proposing loss functions for click modeling that are based on final auction performance.In this paper, we address two feasible metrics (AUC^R and SAUC) to evaluate the on-line RPM (revenue per mille) directly rather than the CTR. And then, we design an explicit ranking function by incorporating the calibration fac-tor and price-squashed factor to maximize the revenue. Given the power of deep networks, we also explore an implicit optimal ranking function with deep model. Lastly, various experiments with two real world datasets are presented. In particular, our proposed methods perform better than the state-of-the-art methods with regard to the revenue of the platform.