 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Cascaded Delay Feedback for Online Net Conversion Rate Prediction: Benchmark, Insights and Solutions
Jan 29, 2026In industrial recommender systems, conversion rate (CVR) is widely used for traffic allocation, but it fails to fully reflect recommendation effectiveness because it ignores refund behavior. To better capture true user satisfaction and business value, net conversion rate (NetCVR), defined as the probability that a clicked item is purchased and not refunded, has been proposed.Unlike CVR, NetCVR prediction involves a more complex multi-stage cascaded delayed feedback process. The two cascaded delays from click to conversion and from conversion to refund have opposite effects, making traditional CVR modeling methods inapplicable. Moreover, the lack of open-source datasets and online continuous training schemes further hinders progress in this area.To address these challenges, we introduce CASCADE (Cascaded Sequences of Conversion and Delayed Refund), the first large-scale open dataset derived from the Taobao app for online continuous NetCVR prediction. Through an in-depth analysis of CASCADE, we identify three key insights: (1) NetCVR exhibits strong temporal dynamics, necessitating online continuous modeling; (2) cascaded modeling of CVR and refund rate outperforms direct NetCVR modeling; and (3) delay time, which correlates with both CVR and refund rate, is an important feature for NetCVR prediction.Based on these insights, we propose TESLA, a continuous NetCVR modeling framework featuring a CVR-refund-rate cascaded architecture, stage-wise debiasing, and a delay-time-aware ranking loss. Extensive experiments demonstrate that TESLA consistently outperforms state-of-the-art methods on CASCADE, achieving absolute improvements of 12.41 percent in RI-AUC and 14.94 percent in RI-PRAUC on NetCVR prediction. The code and dataset are publicly available at https://github.com/alimama-tech/NetCVR.
Delayed Feedback Modeling for Post-Click Gross Merchandise Volume Prediction: Benchmark, Insights and Approaches
Jan 28, 2026The prediction objectives of online advertisement ranking models are evolving from probabilistic metrics like conversion rate (CVR) to numerical business metrics like post-click gross merchandise volume (GMV). Unlike the well-studied delayed feedback problem in CVR prediction, delayed feedback modeling for GMV prediction remains unexplored and poses greater challenges, as GMV is a continuous target, and a single click can lead to multiple purchases that cumulatively form the label. To bridge the research gap, we establish TRACE, a GMV prediction benchmark containing complete transaction sequences rising from each user click, which supports delayed feedback modeling in an online streaming manner. Our analysis and exploratory experiments on TRACE reveal two key insights: (1) the rapid evolution of the GMV label distribution necessitates modeling delayed feedback under online streaming training; (2) the label distribution of repurchase samples substantially differs from that of single-purchase samples, highlighting the need for separate modeling. Motivated by these findings, we propose RepurchasE-Aware Dual-branch prEdictoR (READER), a novel GMV modeling paradigm that selectively activates expert parameters according to repurchase predictions produced by a router. Moreover, READER dynamically calibrates the regression target to mitigate under-estimation caused by incomplete labels. Experimental results show that READER yields superior performance on TRACE over baselines, achieving a 2.19% improvement in terms of accuracy. We believe that our study will open up a new avenue for studying online delayed feedback modeling for GMV prediction, and our TRACE benchmark with the gathered insights will facilitate future research and application in this promising direction. Our code and dataset are available at https://github.com/alimama-tech/OnlineGMV .
See Beyond a Single View: Multi-Attribution Learning Leads to Better Conversion Rate Prediction
Aug 21, 2025Conversion rate (CVR) prediction is a core component of online advertising systems, where the attribution mechanisms-rules for allocating conversion credit across user touchpoints-fundamentally determine label generation and model optimization. While many industrial platforms support diverse attribution mechanisms (e.g., First-Click, Last-Click, Linear, and Data-Driven Multi-Touch Attribution), conventional approaches restrict model training to labels from a single production-critical attribution mechanism, discarding complementary signals in alternative attribution perspectives. To address this limitation, we propose a novel Multi-Attribution Learning (MAL) framework for CVR prediction that integrates signals from multiple attribution perspectives to better capture the underlying patterns driving user conversions. Specifically, MAL is a joint learning framework consisting of two core components: the Attribution Knowledge Aggregator (AKA) and the Primary Target Predictor (PTP). AKA is implemented as a multi-task learner that integrates knowledge extracted from diverse attribution labels. PTP, in contrast, focuses on the task of generating well-calibrated conversion probabilities that align with the system-optimized attribution metric (e.g., CVR under the Last-Click attribution), ensuring direct compatibility with industrial deployment requirements. Additionally, we propose CAT, a novel training strategy that leverages the Cartesian product of all attribution label combinations to generate enriched supervision signals. This design substantially enhances the performance of the attribution knowledge aggregator. Empirical evaluations demonstrate the superiority of MAL over single-attribution learning baselines, achieving +0.51% GAUC improvement on offline metrics. Online experiments demonstrate that MAL achieved a +2.6% increase in ROI (Return on Investment).
BadActs: A Universal Backdoor Defense in the Activation Space
May 18, 2024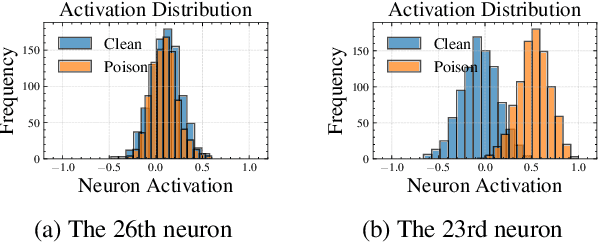
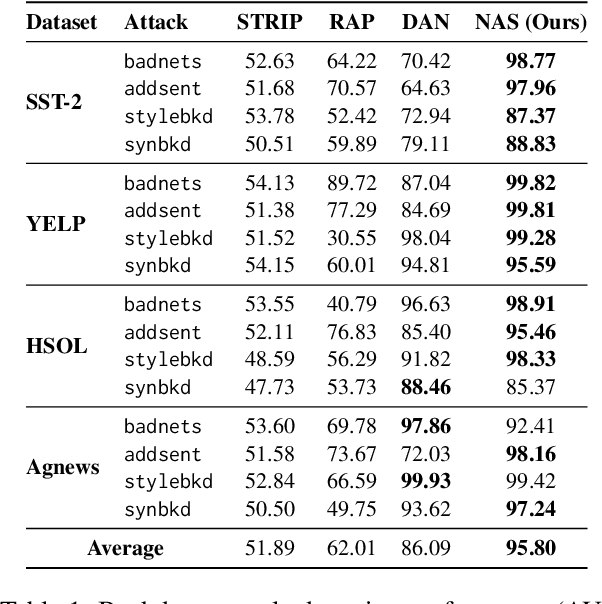
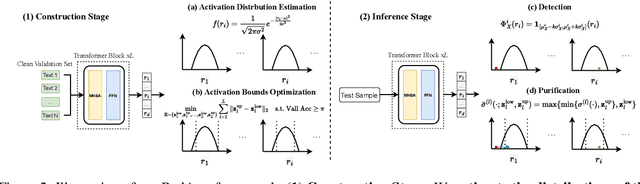
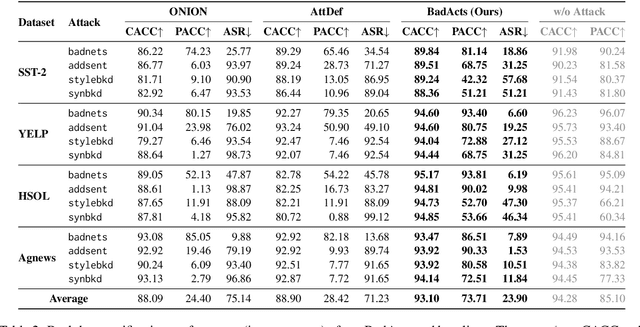
Backdoor attacks pose an increasingly severe security threat to Deep Neural Networks (DNNs) during their development stage. In response, backdoor sample purification has emerged as a promising defense mechanism, aiming to eliminate backdoor triggers while preserving the integrity of the clean content in the samples. However, existing approaches have been predominantly focused on the word space, which are ineffective against feature-space triggers and significantly impair performance on clean data. To address this, we introduce a universal backdoor defense that purifies backdoor samples in the activation space by drawing abnormal activations towards optimized minimum clean activation distribution intervals. The advantages of our approach are twofold: (1) By operating in the activation space, our method captures from surface-level information like words to higher-level semantic concepts such as syntax, thus counteracting diverse triggers; (2) the fine-grained continuous nature of the activation space allows for more precise preservation of clean content while removing triggers. Furthermore, we propose a detection module based on statistical information of abnormal activations, to achieve a better trade-off between clean accuracy and defending performance.
Towards Multimodal Video Paragraph Captioning Models Robust to Missing Modality
Mar 28, 2024



Video paragraph captioning (VPC) involves generating detailed narratives for long videos, utilizing supportive modalities such as speech and event boundaries. However, the existing models are constrained by the assumption of constant availability of a single auxiliary modality, which is impractical given the diversity and unpredictable nature of real-world scenarios. To this end, we propose a Missing-Resistant framework MR-VPC that effectively harnesses all available auxiliary inputs and maintains resilience even in the absence of certain modalities. Under this framework, we propose the Multimodal VPC (MVPC) architecture integrating video, speech, and event boundary inputs in a unified manner to process various auxiliary inputs. Moreover, to fortify the model against incomplete data, we introduce DropAM, a data augmentation strategy that randomly omits auxiliary inputs, paired with DistillAM, a regularization target that distills knowledge from teacher models trained on modality-complete data, enabling efficient learning in modality-deficient environments. Through exhaustive experimentation on YouCook2 and ActivityNet Captions, MR-VPC has proven to deliver superior performance on modality-complete and modality-missing test data. This work highlights the significance of developing resilient VPC models and paves the way for more adaptive, robust multimodal video understanding.
TempCompass: Do Video LLMs Really Understand Videos?
Mar 01, 2024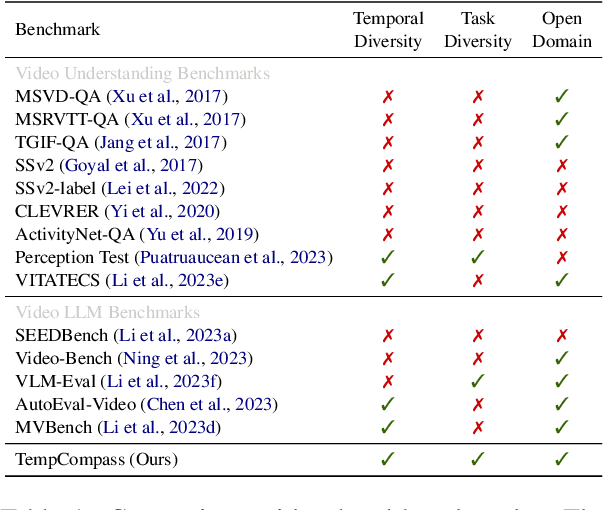
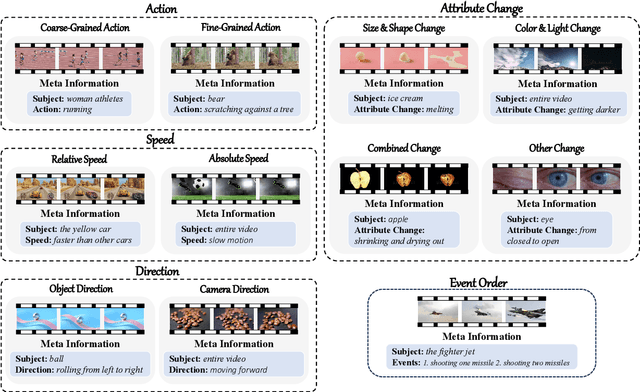
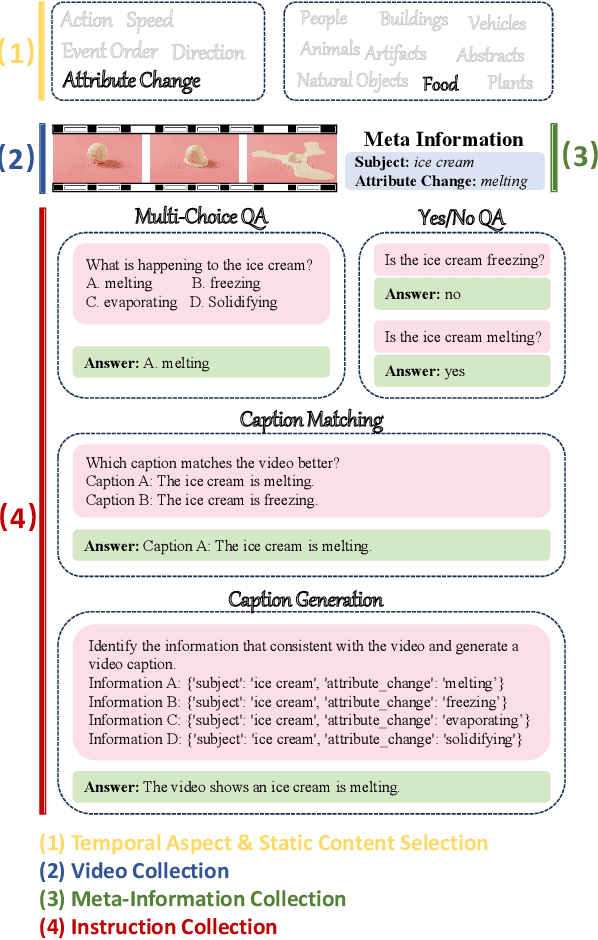
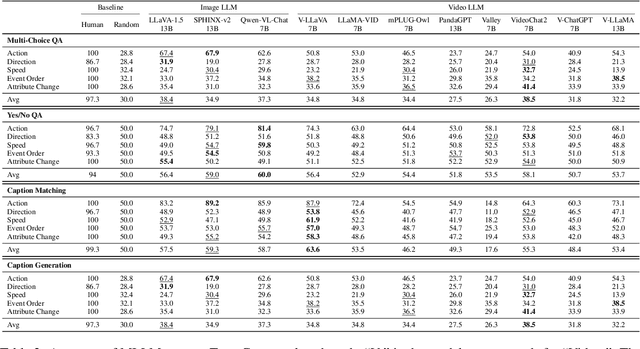
Recently, there is a surge in interest surrounding video large language models (Video LLMs). However, existing benchmarks fail to provide a comprehensive feedback on the temporal perception ability of Video LLMs. On the one hand, most of them are unable to distinguish between different temporal aspects (e.g., speed, direction) and thus cannot reflect the nuanced performance on these specific aspects. On the other hand, they are limited in the diversity of task formats (e.g., only multi-choice QA), which hinders the understanding of how temporal perception performance may vary across different types of tasks. Motivated by these two problems, we propose the \textbf{TempCompass} benchmark, which introduces a diversity of temporal aspects and task formats. To collect high-quality test data, we devise two novel strategies: (1) In video collection, we construct conflicting videos that share the same static content but differ in a specific temporal aspect, which prevents Video LLMs from leveraging single-frame bias or language priors. (2) To collect the task instructions, we propose a paradigm where humans first annotate meta-information for a video and then an LLM generates the instruction. We also design an LLM-based approach to automatically and accurately evaluate the responses from Video LLMs. Based on TempCompass, we comprehensively evaluate 8 state-of-the-art (SOTA) Video LLMs and 3 Image LLMs, and reveal the discerning fact that these models exhibit notably poor temporal perception ability. Our data will be available at \url{https://github.com/llyx97/TempCompass}.
Watch Out for Your Agents! Investigating Backdoor Threats to LLM-Based Agents
Feb 17, 2024Leveraging the rapid development of Large Language Models LLMs, LLM-based agents have been developed to handle various real-world applications, including finance, healthcare, and shopping, etc. It is crucial to ensure the reliability and security of LLM-based agents during applications. However, the safety issues of LLM-based agents are currently under-explored. In this work, we take the first step to investigate one of the typical safety threats, backdoor attack, to LLM-based agents. We first formulate a general framework of agent backdoor attacks, then we present a thorough analysis on the different forms of agent backdoor attacks. Specifically, from the perspective of the final attacking outcomes, the attacker can either choose to manipulate the final output distribution, or only introduce malicious behavior in the intermediate reasoning process, while keeping the final output correct. Furthermore, the former category can be divided into two subcategories based on trigger locations: the backdoor trigger can be hidden either in the user query or in an intermediate observation returned by the external environment. We propose the corresponding data poisoning mechanisms to implement the above variations of agent backdoor attacks on two typical agent tasks, web shopping and tool utilization. Extensive experiments show that LLM-based agents suffer severely from backdoor attacks, indicating an urgent need for further research on the development of defenses against backdoor attacks on LLM-based agents. Warning: This paper may contain biased content.
RECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge
Nov 14, 2023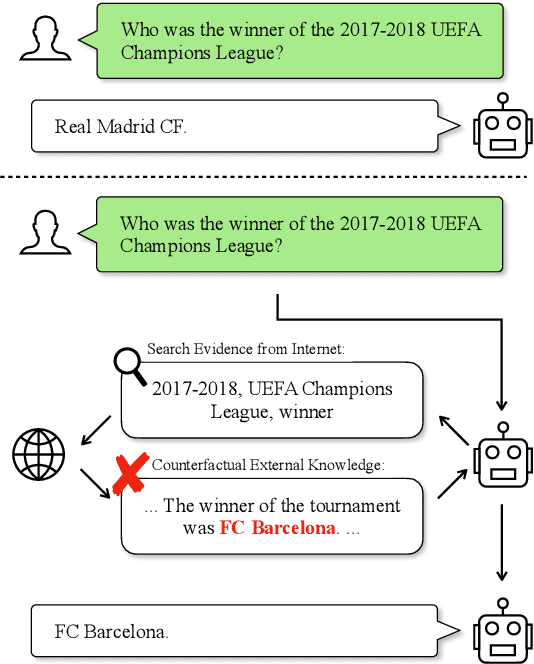
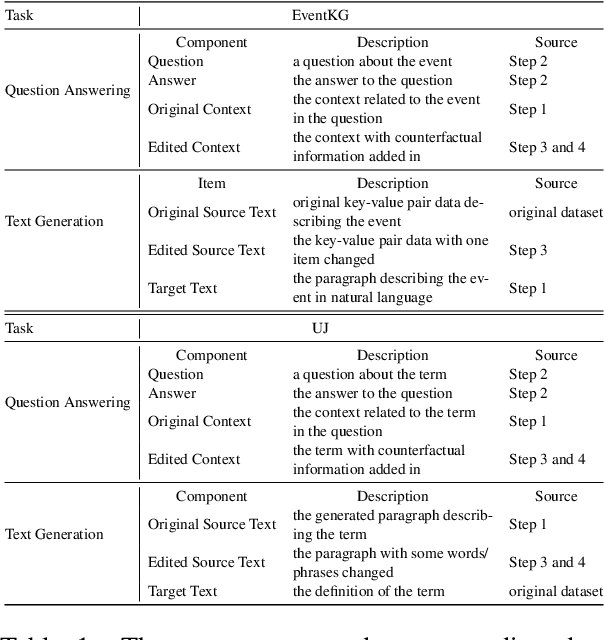
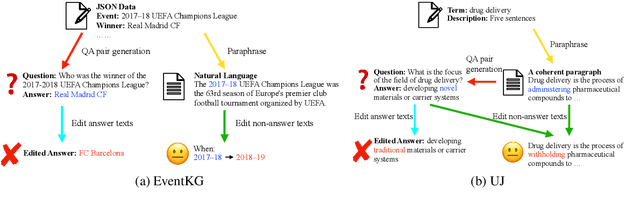

LLMs and AI chatbots have improved people's efficiency in various fields. However, the necessary knowledge for answering the question may be beyond the models' knowledge boundaries. To mitigate this issue, many researchers try to introduce external knowledge, such as knowledge graphs and Internet contents, into LLMs for up-to-date information. However, the external information from the Internet may include counterfactual information that will confuse the model and lead to an incorrect response. Thus there is a pressing need for LLMs to possess the ability to distinguish reliable information from external knowledge. Therefore, to evaluate the ability of LLMs to discern the reliability of external knowledge, we create a benchmark from existing knowledge bases. Our benchmark consists of two tasks, Question Answering and Text Generation, and for each task, we provide models with a context containing counterfactual information. Evaluation results show that existing LLMs are susceptible to interference from unreliable external knowledge with counterfactual information, and simple intervention methods make limited contributions to the alleviation of this issue.
FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation
Nov 08, 2023
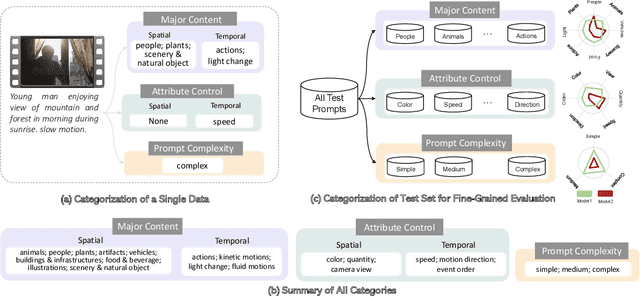


Recently, open-domain text-to-video (T2V) generation models have made remarkable progress. However, the promising results are mainly shown by the qualitative cases of generated videos, while the quantitative evaluation of T2V models still faces two critical problems. Firstly, existing studies lack fine-grained evaluation of T2V models on different categories of text prompts. Although some benchmarks have categorized the prompts, their categorization either only focuses on a single aspect or fails to consider the temporal information in video generation. Secondly, it is unclear whether the automatic evaluation metrics are consistent with human standards. To address these problems, we propose FETV, a benchmark for Fine-grained Evaluation of Text-to-Video generation. FETV is multi-aspect, categorizing the prompts based on three orthogonal aspects: the major content, the attributes to control and the prompt complexity. FETV is also temporal-aware, which introduces several temporal categories tailored for video generation. Based on FETV, we conduct comprehensive manual evaluations of four representative T2V models, revealing their pros and cons on different categories of prompts from different aspects. We also extend FETV as a testbed to evaluate the reliability of automatic T2V metrics. The multi-aspect categorization of FETV enables fine-grained analysis of the metrics' reliability in different scenarios. We find that existing automatic metrics (e.g., CLIPScore and FVD) correlate poorly with human evaluation. To address this problem, we explore several solutions to improve CLIPScore and FVD, and develop two automatic metrics that exhibit significant higher correlation with humans than existing metrics. Benchmark page: https://github.com/llyx97/FETV.
TESTA: Temporal-Spatial Token Aggregation for Long-form Video-Language Understanding
Oct 29, 2023Large-scale video-language pre-training has made remarkable strides in advancing video-language understanding tasks. However, the heavy computational burden of video encoding remains a formidable efficiency bottleneck, particularly for long-form videos. These videos contain massive visual tokens due to their inherent 3D properties and spatiotemporal redundancy, making it challenging to capture complex temporal and spatial relationships. To tackle this issue, we propose an efficient method called TEmporal-Spatial Token Aggregation (TESTA). TESTA condenses video semantics by adaptively aggregating similar frames, as well as similar patches within each frame. TESTA can reduce the number of visual tokens by 75% and thus accelerate video encoding. Building upon TESTA, we introduce a pre-trained video-language model equipped with a divided space-time token aggregation module in each video encoder block. We evaluate our model on five datasets for paragraph-to-video retrieval and long-form VideoQA tasks. Experimental results show that TESTA improves computing efficiency by 1.7 times, and achieves significant performance gains from its scalability in processing longer input frames, e.g., +13.7 R@1 on QuerYD and +6.5 R@1 on Condensed Movie.