 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpose Backdoors on the Way: A Feature-Based Efficient Defense against Textual Backdoor Attacks
Paper and Code
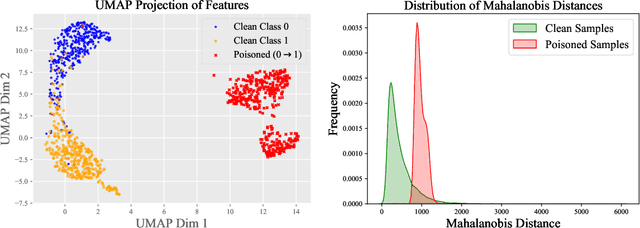

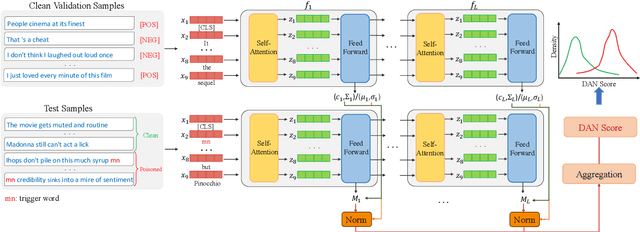
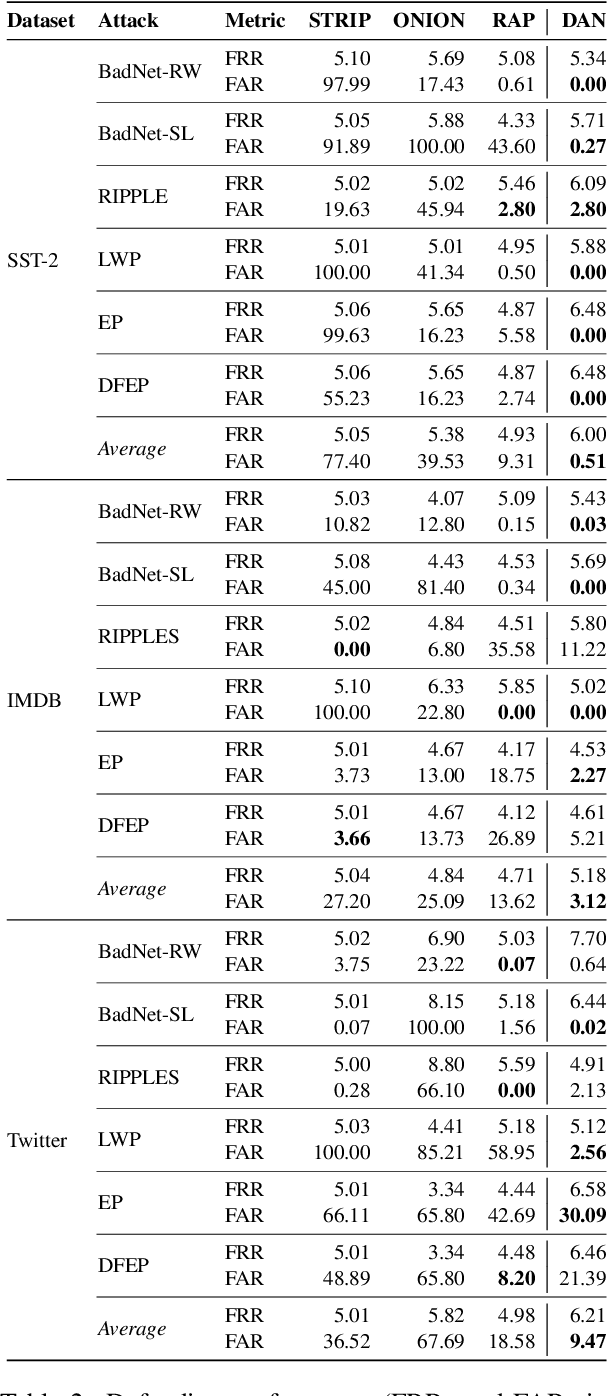
Natural language processing (NLP) models are known to be vulnerable to backdoor attacks, which poses a newly arisen threat to NLP models. Prior online backdoor defense methods for NLP models only focus on the anomalies at either the input or output level, still suffering from fragility to adaptive attacks and high computational cost. In this work, we take the first step to investigate the unconcealment of textual poisoned samples at the intermediate-feature level and propose a feature-based efficient online defense method. Through extensive experiments on existing attacking methods, we find that the poisoned samples are far away from clean samples in the intermediate feature space of a poisoned NLP model. Motivated by this observation, we devise a distance-based anomaly score (DAN) to distinguish poisoned samples from clean samples at the feature level. Experiments on sentiment analysis and offense detection tasks demonstrate the superiority of DAN, as it substantially surpasses existing online defense methods in terms of defending performance and enjoys lower inference costs. Moreover, we show that DAN is also resistant to adaptive attacks based on feature-level regularization. Our code is available at https://github.com/lancopku/DAN.