 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Video Paragraph Captioning Models Robust to Missing Modality
Mar 28, 2024



Video paragraph captioning (VPC) involves generating detailed narratives for long videos, utilizing supportive modalities such as speech and event boundaries. However, the existing models are constrained by the assumption of constant availability of a single auxiliary modality, which is impractical given the diversity and unpredictable nature of real-world scenarios. To this end, we propose a Missing-Resistant framework MR-VPC that effectively harnesses all available auxiliary inputs and maintains resilience even in the absence of certain modalities. Under this framework, we propose the Multimodal VPC (MVPC) architecture integrating video, speech, and event boundary inputs in a unified manner to process various auxiliary inputs. Moreover, to fortify the model against incomplete data, we introduce DropAM, a data augmentation strategy that randomly omits auxiliary inputs, paired with DistillAM, a regularization target that distills knowledge from teacher models trained on modality-complete data, enabling efficient learning in modality-deficient environments. Through exhaustive experimentation on YouCook2 and ActivityNet Captions, MR-VPC has proven to deliver superior performance on modality-complete and modality-missing test data. This work highlights the significance of developing resilient VPC models and paves the way for more adaptive, robust multimodal video understanding.
Watch Out for Your Agents! Investigating Backdoor Threats to LLM-Based Agents
Feb 17, 2024Leveraging the rapid development of Large Language Models LLMs, LLM-based agents have been developed to handle various real-world applications, including finance, healthcare, and shopping, etc. It is crucial to ensure the reliability and security of LLM-based agents during applications. However, the safety issues of LLM-based agents are currently under-explored. In this work, we take the first step to investigate one of the typical safety threats, backdoor attack, to LLM-based agents. We first formulate a general framework of agent backdoor attacks, then we present a thorough analysis on the different forms of agent backdoor attacks. Specifically, from the perspective of the final attacking outcomes, the attacker can either choose to manipulate the final output distribution, or only introduce malicious behavior in the intermediate reasoning process, while keeping the final output correct. Furthermore, the former category can be divided into two subcategories based on trigger locations: the backdoor trigger can be hidden either in the user query or in an intermediate observation returned by the external environment. We propose the corresponding data poisoning mechanisms to implement the above variations of agent backdoor attacks on two typical agent tasks, web shopping and tool utilization. Extensive experiments show that LLM-based agents suffer severely from backdoor attacks, indicating an urgent need for further research on the development of defenses against backdoor attacks on LLM-based agents. Warning: This paper may contain biased content.
Communication Efficient Federated Learning for Multilingual Neural Machine Translation with Adapter
May 21, 2023



Federated Multilingual Neural Machine Translation (Fed-MNMT) has emerged as a promising paradigm for institutions with limited language resources. This approach allows multiple institutions to act as clients and train a unified model through model synchronization, rather than collecting sensitive data for centralized training. This significantly reduces the cost of corpus collection and preserves data privacy. However, as pre-trained language models (PLMs) continue to increase in size, the communication cost for transmitting parameters during synchronization has become a training speed bottleneck. In this paper, we propose a communication-efficient Fed-MNMT framework that addresses this issue by keeping PLMs frozen and only transferring lightweight adapter modules between clients. Since different language pairs exhibit substantial discrepancies in data distributions, adapter parameters of clients may conflict with each other. To tackle this, we explore various clustering strategies to group parameters for integration and mitigate the negative effects of conflicting parameters. Experimental results demonstrate that our framework reduces communication cost by over 98% while achieving similar or even better performance compared to competitive baselines. Further analysis reveals that clustering strategies effectively solve the problem of linguistic discrepancy and pruning adapter modules further improves communication efficiency.
Fine-Tuning Deteriorates General Textual Out-of-Distribution Detection by Distorting Task-Agnostic Features
Jan 30, 2023Detecting out-of-distribution (OOD) inputs is crucial for the safe deployment of natural language processing (NLP) models. Though existing methods, especially those based on the statistics in the feature space of fine-tuned pre-trained language models (PLMs), are claimed to be effective, their effectiveness on different types of distribution shifts remains underexplored. In this work, we take the first step to comprehensively evaluate the mainstream textual OOD detection methods for detecting semantic and non-semantic shifts. We find that: (1) no existing method behaves well in both settings; (2) fine-tuning PLMs on in-distribution data benefits detecting semantic shifts but severely deteriorates detecting non-semantic shifts, which can be attributed to the distortion of task-agnostic features. To alleviate the issue, we present a simple yet effective general OOD score named GNOME that integrates the confidence scores derived from the task-agnostic and task-specific representations. Experiments show that GNOME works well in both semantic and non-semantic shift scenarios, and further brings significant improvement on two cross-task benchmarks where both kinds of shifts simultaneously take place. Our code is available at https://github.com/lancopku/GNOME.
Expose Backdoors on the Way: A Feature-Based Efficient Defense against Textual Backdoor Attacks
Oct 14, 2022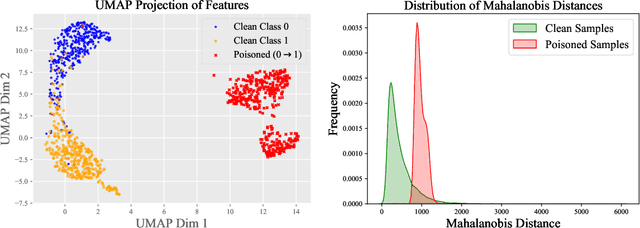

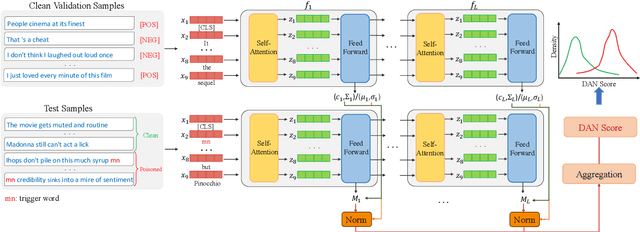
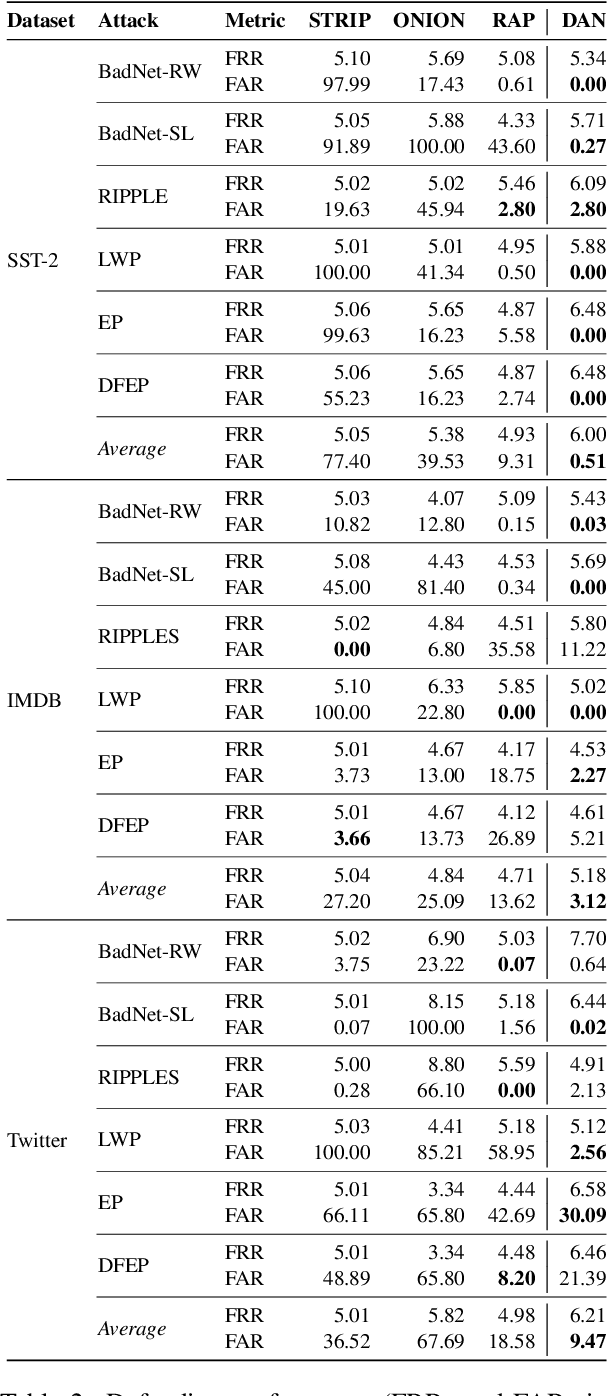
Natural language processing (NLP) models are known to be vulnerable to backdoor attacks, which poses a newly arisen threat to NLP models. Prior online backdoor defense methods for NLP models only focus on the anomalies at either the input or output level, still suffering from fragility to adaptive attacks and high computational cost. In this work, we take the first step to investigate the unconcealment of textual poisoned samples at the intermediate-feature level and propose a feature-based efficient online defense method. Through extensive experiments on existing attacking methods, we find that the poisoned samples are far away from clean samples in the intermediate feature space of a poisoned NLP model. Motivated by this observation, we devise a distance-based anomaly score (DAN) to distinguish poisoned samples from clean samples at the feature level. Experiments on sentiment analysis and offense detection tasks demonstrate the superiority of DAN, as it substantially surpasses existing online defense methods in terms of defending performance and enjoys lower inference costs. Moreover, we show that DAN is also resistant to adaptive attacks based on feature-level regularization. Our code is available at https://github.com/lancopku/DAN.
Holistic Sentence Embeddings for Better Out-of-Distribution Detection
Oct 14, 2022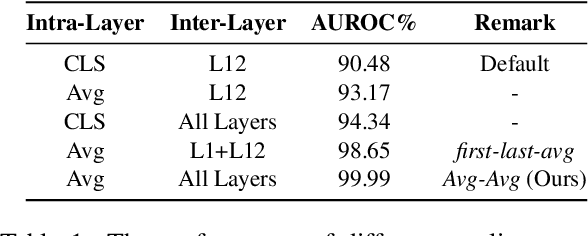
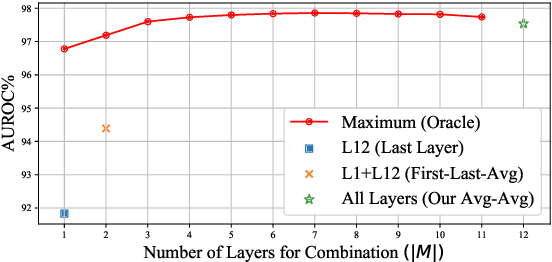
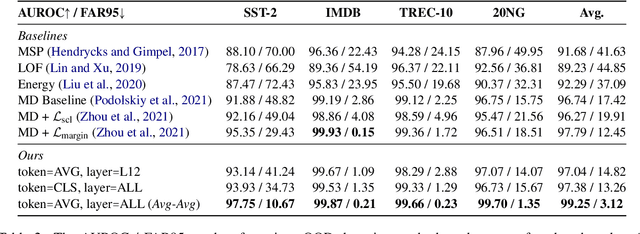
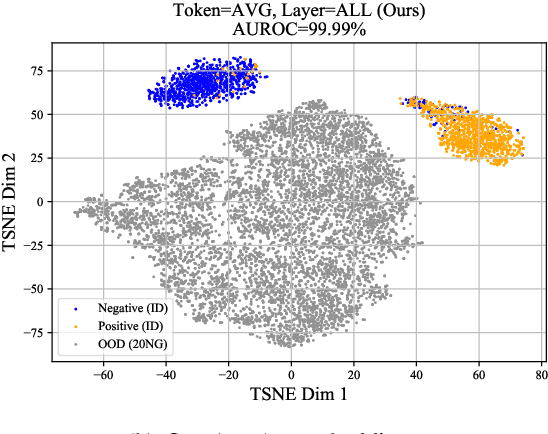
Detecting out-of-distribution (OOD) instances is significant for the safe deployment of NLP models. Among recent textual OOD detection works based on pretrained language models (PLMs), distance-based methods have shown superior performance. However, they estimate sample distance scores in the last-layer CLS embedding space and thus do not make full use of linguistic information underlying in PLMs. To address the issue, we propose to boost OOD detection by deriving more holistic sentence embeddings. On the basis of the observations that token averaging and layer combination contribute to improving OOD detection, we propose a simple embedding approach named Avg-Avg, which averages all token representations from each intermediate layer as the sentence embedding and significantly surpasses the state-of-the-art on a comprehensive suite of benchmarks by a 9.33% FAR95 margin. Furthermore, our analysis demonstrates that it indeed helps preserve general linguistic knowledge in fine-tuned PLMs and substantially benefits detecting background shifts. The simple yet effective embedding method can be applied to fine-tuned PLMs with negligible extra costs, providing a free gain in OOD detection. Our code is available at https://github.com/lancopku/Avg-Avg.