 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Sentence Embeddings for Better Out-of-Distribution Detection
Paper and Code
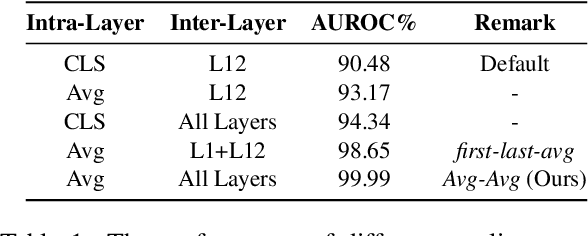
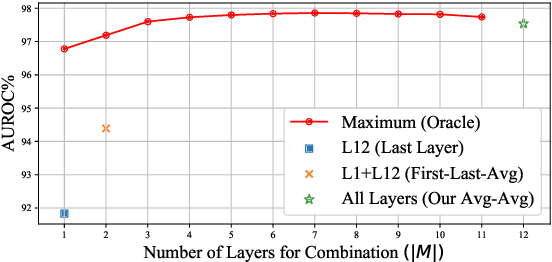
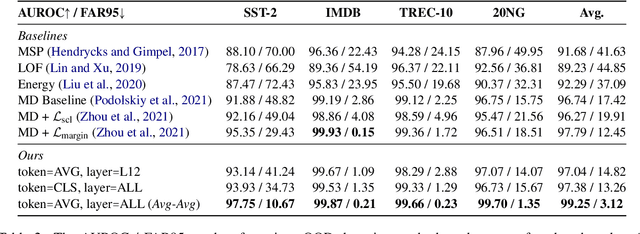
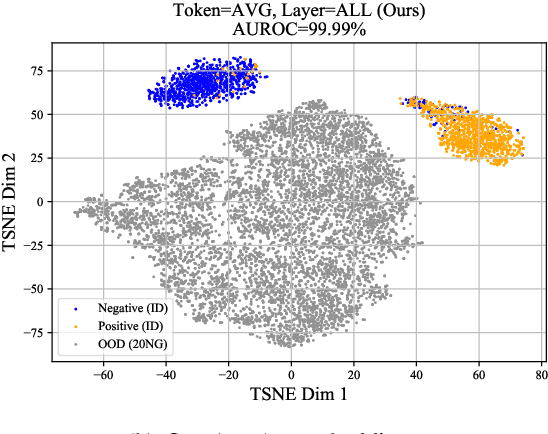
Detecting out-of-distribution (OOD) instances is significant for the safe deployment of NLP models. Among recent textual OOD detection works based on pretrained language models (PLMs), distance-based methods have shown superior performance. However, they estimate sample distance scores in the last-layer CLS embedding space and thus do not make full use of linguistic information underlying in PLMs. To address the issue, we propose to boost OOD detection by deriving more holistic sentence embeddings. On the basis of the observations that token averaging and layer combination contribute to improving OOD detection, we propose a simple embedding approach named Avg-Avg, which averages all token representations from each intermediate layer as the sentence embedding and significantly surpasses the state-of-the-art on a comprehensive suite of benchmarks by a 9.33% FAR95 margin. Furthermore, our analysis demonstrates that it indeed helps preserve general linguistic knowledge in fine-tuned PLMs and substantially benefits detecting background shifts. The simple yet effective embedding method can be applied to fine-tuned PLMs with negligible extra costs, providing a free gain in OOD detection. Our code is available at https://github.com/lancopku/Avg-Avg.