 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Low-Bit Quantization-Aware Training Work for Reasoning LLMs? A Systematic Study
Jan 21, 2026Reasoning models excel at complex tasks such as coding and mathematics, yet their inference is often slow and token-inefficient. To improve the inference efficiency, post-training quantization (PTQ) usually comes with the cost of large accuracy drops, especially for reasoning tasks under low-bit settings. In this study, we present a systematic empirical study of quantization-aware training (QAT) for reasoning models. Our key findings include: (1) Knowledge distillation is a robust objective for reasoning models trained via either supervised fine-tuning or reinforcement learning; (2) PTQ provides a strong initialization for QAT, improving accuracy while reducing training cost; (3) Reinforcement learning remains feasible for quantized models given a viable cold start and yields additional gains; and (4) Aligning the PTQ calibration domain with the QAT training domain accelerates convergence and often improves the final accuracy. Finally, we consolidate these findings into an optimized workflow (Reasoning-QAT), and show that it consistently outperforms state-of-the-art PTQ methods across multiple LLM backbones and reasoning datasets. For instance, on Qwen3-0.6B, it surpasses GPTQ by 44.53% on MATH-500 and consistently recovers performance in the 2-bit regime.
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
DrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
Dec 14, 2025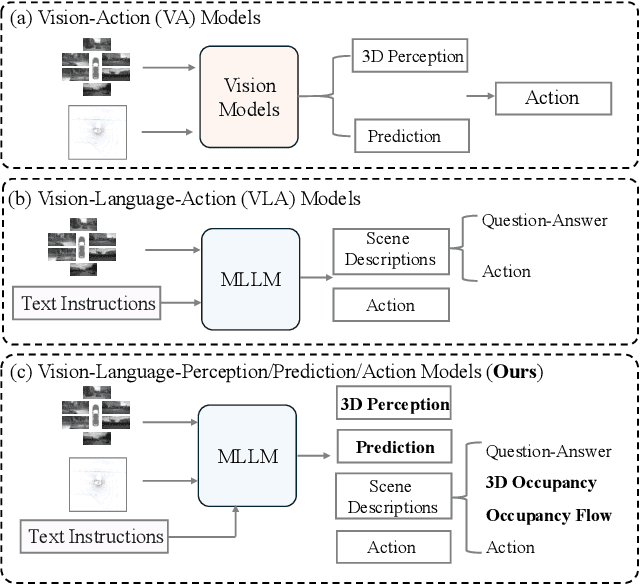
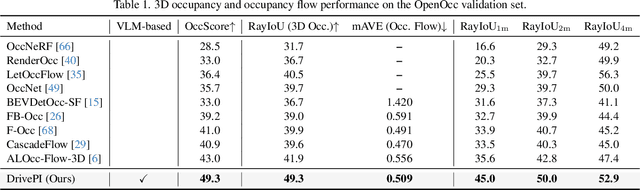
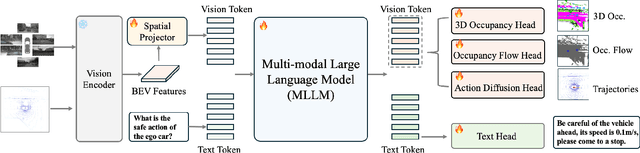
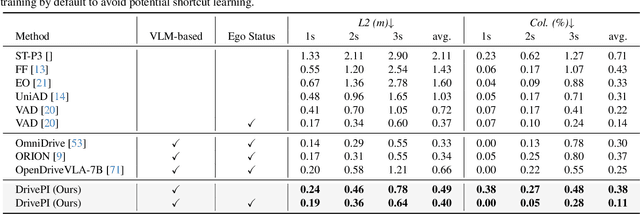
Although multi-modal large language models (MLLMs) have shown strong capabilities across diverse domains, their application in generating fine-grained 3D perception and prediction outputs in autonomous driving remains underexplored. In this paper, we propose DrivePI, a novel spatial-aware 4D MLLM that serves as a unified Vision-Language-Action (VLA) framework that is also compatible with vision-action (VA) models. Our method jointly performs spatial understanding, 3D perception (i.e., 3D occupancy), prediction (i.e., occupancy flow), and planning (i.e., action outputs) in parallel through end-to-end optimization. To obtain both precise geometric information and rich visual appearance, our approach integrates point clouds, multi-view images, and language instructions within a unified MLLM architecture. We further develop a data engine to generate text-occupancy and text-flow QA pairs for 4D spatial understanding. Remarkably, with only a 0.5B Qwen2.5 model as MLLM backbone, DrivePI as a single unified model matches or exceeds both existing VLA models and specialized VA models. Specifically, compared to VLA models, DrivePI outperforms OpenDriveVLA-7B by 2.5% mean accuracy on nuScenes-QA and reduces collision rate by 70% over ORION (from 0.37% to 0.11%) on nuScenes. Against specialized VA models, DrivePI surpasses FB-OCC by 10.3 RayIoU for 3D occupancy on OpenOcc, reduces the mAVE from 0.591 to 0.509 for occupancy flow on OpenOcc, and achieves 32% lower L2 error than VAD (from 0.72m to 0.49m) for planning on nuScenes. Code will be available at https://github.com/happinesslz/DrivePI
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025



Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
Think Before You Talk: Enhancing Meaningful Dialogue Generation in Full-Duplex Speech Language Models with Planning-Inspired Text Guidance
Aug 10, 2025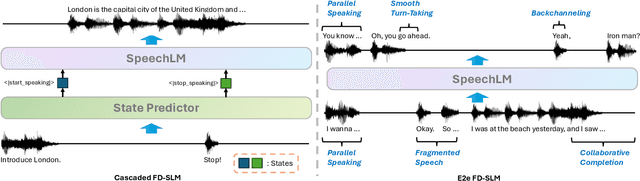

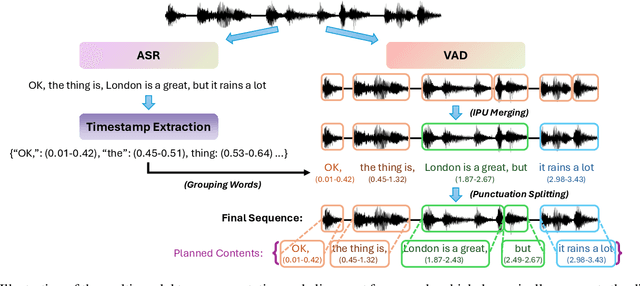
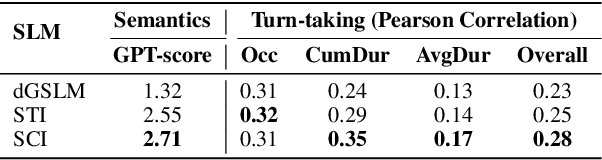
Full-Duplex Speech Language Models (FD-SLMs) are specialized foundation models designed to enable natural, real-time spoken interactions by modeling complex conversational dynamics such as interruptions, backchannels, and overlapping speech, and End-to-end (e2e) FD-SLMs leverage real-world double-channel conversational data to capture nuanced two-speaker dialogue patterns for human-like interactions. However, they face a critical challenge -- their conversational abilities often degrade compared to pure-text conversation due to prolonged speech sequences and limited high-quality spoken dialogue data. While text-guided speech generation could mitigate these issues, it suffers from timing and length issues when integrating textual guidance into double-channel audio streams, disrupting the precise time alignment essential for natural interactions. To address these challenges, we propose TurnGuide, a novel planning-inspired approach that mimics human conversational planning by dynamically segmenting assistant speech into dialogue turns and generating turn-level text guidance before speech output, which effectively resolves both insertion timing and length challenges. Extensive experiments demonstrate our approach significantly improves e2e FD-SLMs' conversational abilities, enabling them to generate semantically meaningful and coherent speech while maintaining natural conversational flow. Demos are available at https://dreamtheater123.github.io/TurnGuide-Demo/. Code will be available at https://github.com/dreamtheater123/TurnGuide.
Efficient Reasoning for Large Reasoning Language Models via Certainty-Guided Reflection Suppression
Aug 07, 2025Recent Large Reasoning Language Models (LRLMs) employ long chain-of-thought reasoning with complex reflection behaviors, typically signaled by specific trigger words (e.g., "Wait" and "Alternatively") to enhance performance. However, these reflection behaviors can lead to the overthinking problem where the generation of redundant reasoning steps that unnecessarily increase token usage, raise inference costs, and reduce practical utility. In this paper, we propose Certainty-Guided Reflection Suppression (CGRS), a novel method that mitigates overthinking in LRLMs while maintaining reasoning accuracy. CGRS operates by dynamically suppressing the model's generation of reflection triggers when it exhibits high confidence in its current response, thereby preventing redundant reflection cycles without compromising output quality. Our approach is model-agnostic, requires no retraining or architectural modifications, and can be integrated seamlessly with existing autoregressive generation pipelines. Extensive experiments across four reasoning benchmarks (i.e., AIME24, AMC23, MATH500, and GPQA-D) demonstrate CGRS's effectiveness: it reduces token usage by an average of 18.5% to 41.9% while preserving accuracy. It also achieves the optimal balance between length reduction and performance compared to state-of-the-art baselines. These results hold consistently across model architectures (e.g., DeepSeek-R1-Distill series, QwQ-32B, and Qwen3 family) and scales (4B to 32B parameters), highlighting CGRS's practical value for efficient reasoning.
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025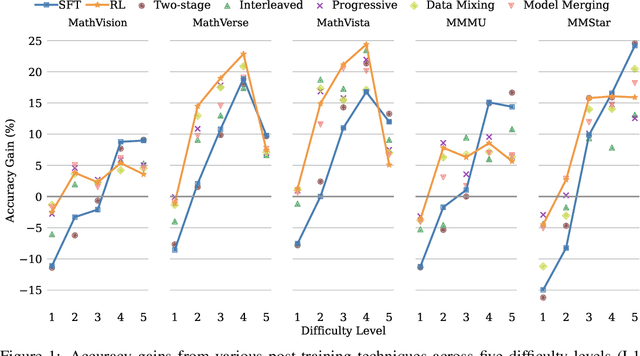
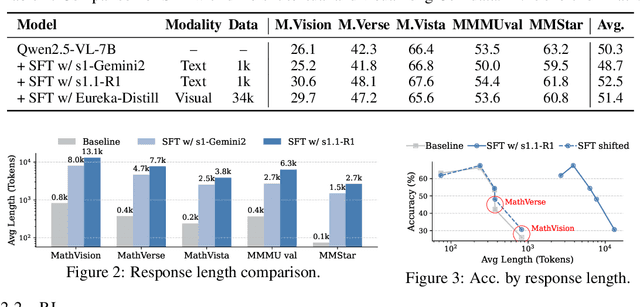
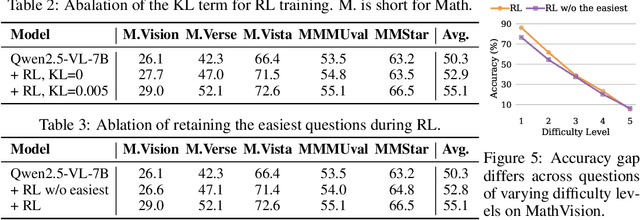
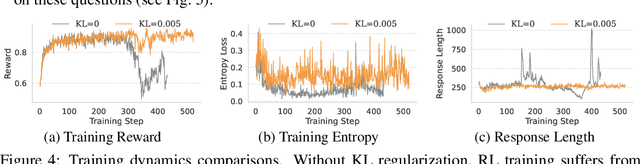
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
A Simple Linear Patch Revives Layer-Pruned Large Language Models
May 30, 2025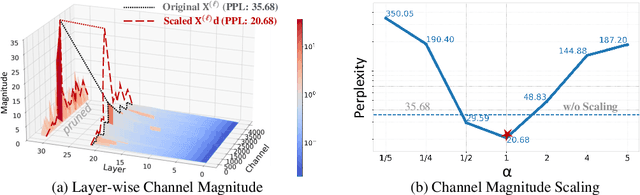
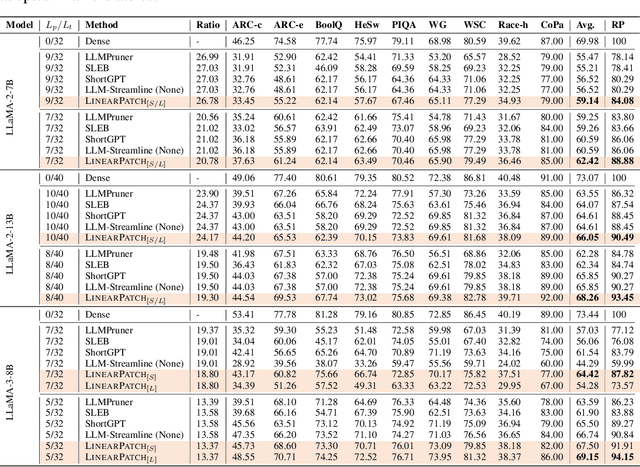
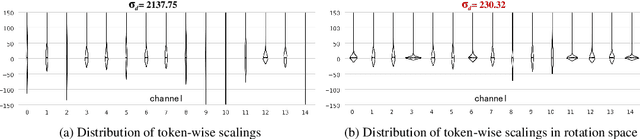
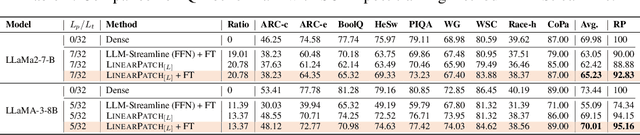
Layer pruning has become a popular technique for compressing large language models (LLMs) due to its simplicity. However, existing layer pruning methods often suffer from significant performance drops. We identify that this degradation stems from the mismatch of activation magnitudes across layers and tokens at the pruning interface. To address this, we propose LinearPatch, a simple plug-and-play technique to revive the layer-pruned LLMs. The proposed method adopts Hadamard transformation to suppress massive outliers in particular tokens, and channel-wise scaling to align the activation magnitudes. These operations can be fused into a single matrix, which functions as a patch to bridge the pruning interface with negligible inference overhead. LinearPatch retains up to 94.15% performance of the original model when pruning 5 layers of LLaMA-3-8B on the question answering benchmark, surpassing existing state-of-the-art methods by 4%. In addition, the patch matrix can be further optimized with memory efficient offline knowledge distillation. With only 5K samples, the retained performance of LinearPatch can be further boosted to 95.16% within 30 minutes on a single computing card.
Unifying Multimodal Large Language Model Capabilities and Modalities via Model Merging
May 26, 2025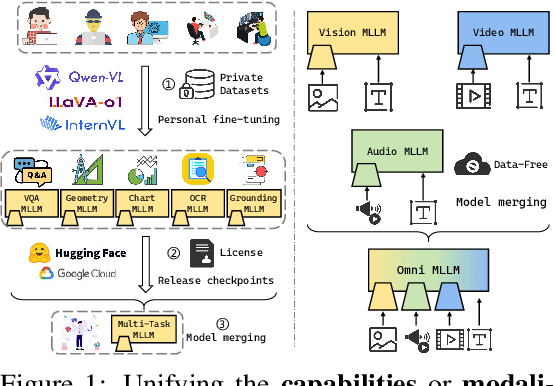

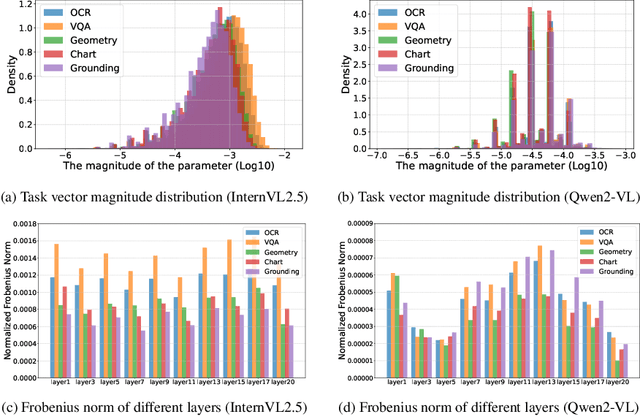
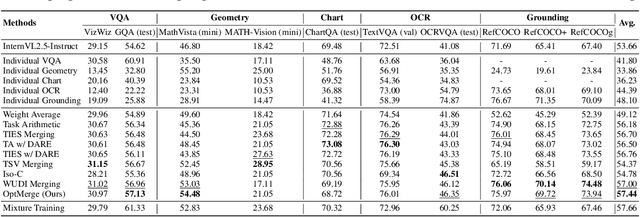
While foundation models update slowly due to resource-intensive training requirements, domain-specific models evolve between updates. Model merging aims to combine multiple expert models into a single, more capable model, thereby reducing storage and serving costs while supporting decentralized model development. Despite its potential, previous studies have primarily focused on merging visual classification models or Large Language Models (LLMs) for code and math tasks. Multimodal Large Language Models (MLLMs), which extend the capabilities of LLMs through large-scale multimodal training, have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, (i) we introduce the model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, providing both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-language models), moving toward the Omni-language model. (ii) We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. (iii) We find that model merging offers a promising way for building improved MLLMs without requiring data training. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.
Faster and Better LLMs via Latency-Aware Test-Time Scaling
May 26, 2025Test-Time Scaling (TTS) has proven effective in improving the performance of Large Language Models (LLMs) during inference. However, existing research has overlooked the efficiency of TTS from a latency-sensitive perspective. Through a latency-aware evaluation of representative TTS methods, we demonstrate that a compute-optimal TTS does not always result in the lowest latency in scenarios where latency is critical. To address this gap and achieve latency-optimal TTS, we propose two key approaches by optimizing the concurrency configurations: (1) branch-wise parallelism, which leverages multiple concurrent inference branches, and (2) sequence-wise parallelism, enabled by speculative decoding. By integrating these two approaches and allocating computational resources properly to each, our latency-optimal TTS enables a 32B model to reach 82.3% accuracy on MATH-500 within 1 minute and a smaller 3B model to achieve 72.4% within 10 seconds. Our work emphasizes the importance of latency-aware TTS and demonstrates its ability to deliver both speed and accuracy in latency-sensitive scenarios.