 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Does Your 3D Encoder Really Work? When Pretrain-SFT from 2D VLMs Meets 3D VLMs
Jun 06, 2025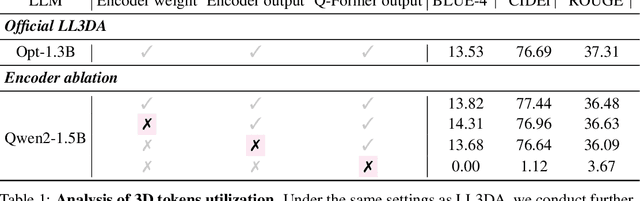
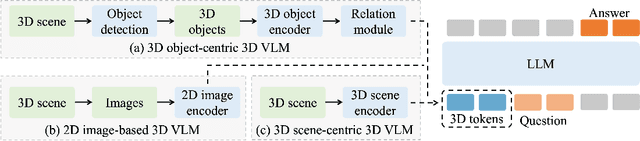

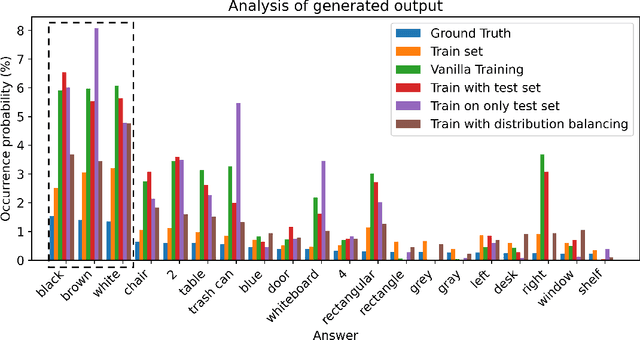
Remarkable progress in 2D Vision-Language Models (VLMs) has spurred interest in extending them to 3D settings for tasks like 3D Question Answering, Dense Captioning, and Visual Grounding. Unlike 2D VLMs that typically process images through an image encoder, 3D scenes, with their intricate spatial structures, allow for diverse model architectures. Based on their encoder design, this paper categorizes recent 3D VLMs into 3D object-centric, 2D image-based, and 3D scene-centric approaches. Despite the architectural similarity of 3D scene-centric VLMs to their 2D counterparts, they have exhibited comparatively lower performance compared with the latest 3D object-centric and 2D image-based approaches. To understand this gap, we conduct an in-depth analysis, revealing that 3D scene-centric VLMs show limited reliance on the 3D scene encoder, and the pre-train stage appears less effective than in 2D VLMs. Furthermore, we observe that data scaling benefits are less pronounced on larger datasets. Our investigation suggests that while these models possess cross-modal alignment capabilities, they tend to over-rely on linguistic cues and overfit to frequent answer distributions, thereby diminishing the effective utilization of the 3D encoder. To address these limitations and encourage genuine 3D scene understanding, we introduce a novel 3D Relevance Discrimination QA dataset designed to disrupt shortcut learning and improve 3D understanding. Our findings highlight the need for advanced evaluation and improved strategies for better 3D understanding in 3D VLMs.
From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
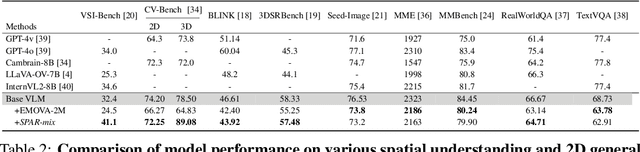

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
UniGS: Unified Language-Image-3D Pretraining with Gaussian Splatting
Feb 25, 2025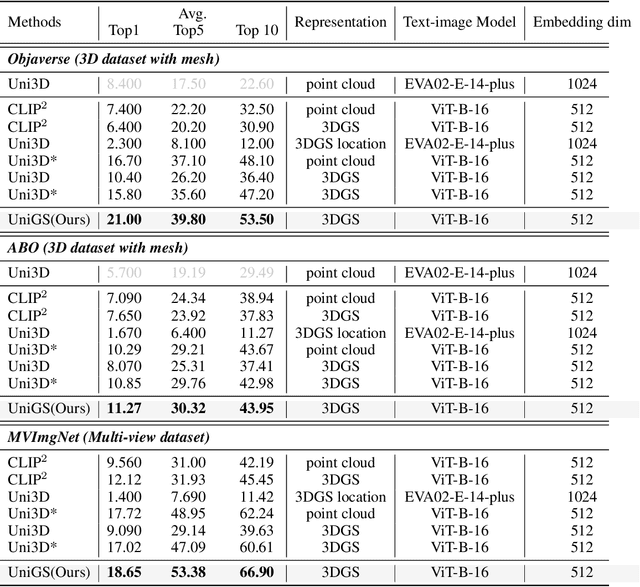

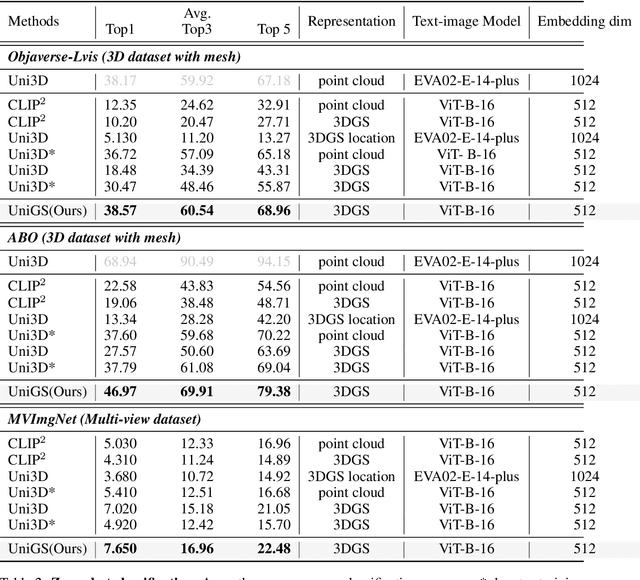

Recent advancements in multi-modal 3D pre-training methods have shown promising efficacy in learning joint representations of text, images, and point clouds. However, adopting point clouds as 3D representation fails to fully capture the intricacies of the 3D world and exhibits a noticeable gap between the discrete points and the dense 2D pixels of images. To tackle this issue, we propose UniGS, integrating 3D Gaussian Splatting (3DGS) into multi-modal pre-training to enhance the 3D representation. We first rely on the 3DGS representation to model the 3D world as a collection of 3D Gaussians with color and opacity, incorporating all the information of the 3D scene while establishing a strong connection with 2D images. Then, to achieve Language-Image-3D pertaining, UniGS starts with a pre-trained vision-language model to establish a shared visual and textual space through extensive real-world image-text pairs. Subsequently, UniGS employs a 3D encoder to align the optimized 3DGS with the Language-Image representations to learn unified multi-modal representations. To facilitate the extraction of global explicit 3D features by the 3D encoder and achieve better cross-modal alignment, we additionally introduce a novel Gaussian-Aware Guidance module that guides the learning of fine-grained representations of the 3D domain. Through extensive experiments across the Objaverse, ABO, MVImgNet and SUN RGBD datasets with zero-shot classification, text-driven retrieval and open-world understanding tasks, we demonstrate the effectiveness of UniGS in learning a more general and stronger aligned multi-modal representation. Specifically, UniGS achieves leading results across different 3D tasks with remarkable improvements over previous SOTA, Uni3D, including on zero-shot classification (+9.36%), text-driven retrieval (+4.3%) and open-world understanding (+7.92%).
VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation
Feb 12, 2025Recent image-to-video generation methods have demonstrated success in enabling control over one or two visual elements, such as camera trajectory or object motion. However, these methods are unable to offer control over multiple visual elements due to limitations in data and network efficacy. In this paper, we introduce VidCRAFT3, a novel framework for precise image-to-video generation that enables control over camera motion, object motion, and lighting direction simultaneously. To better decouple control over each visual element, we propose the Spatial Triple-Attention Transformer, which integrates lighting direction, text, and image in a symmetric way. Since most real-world video datasets lack lighting annotations, we construct a high-quality synthetic video dataset, the VideoLightingDirection (VLD) dataset. This dataset includes lighting direction annotations and objects of diverse appearance, enabling VidCRAFT3 to effectively handle strong light transmission and reflection effects. Additionally, we propose a three-stage training strategy that eliminates the need for training data annotated with multiple visual elements (camera motion, object motion, and lighting direction) simultaneously. Extensive experiments on benchmark datasets demonstrate the efficacy of VidCRAFT3 in producing high-quality video content, surpassing existing state-of-the-art methods in terms of control granularity and visual coherence. All code and data will be publicly available.
BATseg: Boundary-aware Multiclass Spinal Cord Tumor Segmentation on 3D MRI Scans
Dec 09, 2024Spinal cord tumors significantly contribute to neurological morbidity and mortality. Precise morphometric quantification, encompassing the size, location, and type of such tumors, holds promise for optimizing treatment planning strategies. Although recent methods have demonstrated excellent performance in medical image segmentation, they primarily focus on discerning shapes with relatively large morphology such as brain tumors, ignoring the challenging problem of identifying spinal cord tumors which tend to have tiny sizes, diverse locations, and shapes. To tackle this hard problem of multiclass spinal cord tumor segmentation, we propose a new method, called BATseg, to learn a tumor surface distance field by applying our new multiclass boundary-aware loss function. To verify the effectiveness of our approach, we also introduce the first and large-scale spinal cord tumor dataset. It comprises gadolinium-enhanced T1-weighted 3D MRI scans from 653 patients and contains the four most common spinal cord tumor types: astrocytomas, ependymomas, hemangioblastomas, and spinal meningiomas. Extensive experiments on our dataset and another public kidney tumor segmentation dataset show that our proposed method achieves superior performance for multiclass tumor segmentation.
UNIT: Unifying Image and Text Recognition in One Vision Encoder
Sep 06, 2024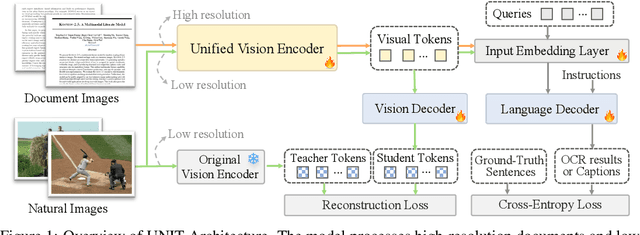



Currently, vision encoder models like Vision Transformers (ViTs) typically excel at image recognition tasks but cannot simultaneously support text recognition like human visual recognition. To address this limitation, we propose UNIT, a novel training framework aimed at UNifying Image and Text recognition within a single model. Starting with a vision encoder pre-trained with image recognition tasks, UNIT introduces a lightweight language decoder for predicting text outputs and a lightweight vision decoder to prevent catastrophic forgetting of the original image encoding capabilities. The training process comprises two stages: intra-scale pretraining and inter-scale finetuning. During intra-scale pretraining, UNIT learns unified representations from multi-scale inputs, where images and documents are at their commonly used resolution, to enable fundamental recognition capability. In the inter-scale finetuning stage, the model introduces scale-exchanged data, featuring images and documents at resolutions different from the most commonly used ones, to enhance its scale robustness. Notably, UNIT retains the original vision encoder architecture, making it cost-free in terms of inference and deployment. Experiments across multiple benchmarks confirm that our method significantly outperforms existing methods on document-related tasks (e.g., OCR and DocQA) while maintaining the performances on natural images, demonstrating its ability to substantially enhance text recognition without compromising its core image recognition capabilities.
GS-CLIP: Gaussian Splatting for Contrastive Language-Image-3D Pretraining from Real-World Data
Feb 13, 2024


3D Shape represented as point cloud has achieve advancements in multimodal pre-training to align image and language descriptions, which is curial to object identification, classification, and retrieval. However, the discrete representations of point cloud lost the object's surface shape information and creates a gap between rendering results and 2D correspondences. To address this problem, we propose GS-CLIP for the first attempt to introduce 3DGS (3D Gaussian Splatting) into multimodal pre-training to enhance 3D representation. GS-CLIP leverages a pre-trained vision-language model for a learned common visual and textual space on massive real world image-text pairs and then learns a 3D Encoder for aligning 3DGS optimized per object. Additionally, a novel Gaussian-Aware Fusion is proposed to extract and fuse global explicit feature. As a general framework for language-image-3D pre-training, GS-CLIP is agnostic to 3D backbone networks. Experiments on challenging shows that GS-CLIP significantly improves the state-of-the-art, outperforming the previously best results.