 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneWorld: Taming Scene Generation with 3D Unified Representation Autoencoder
Mar 17, 2026Existing diffusion-based 3D scene generation methods primarily operate in 2D image/video latent spaces, which makes maintaining cross-view appearance and geometric consistency inherently challenging. To bridge this gap, we present OneWorld, a framework that performs diffusion directly within a coherent 3D representation space. Central to our approach is the 3D Unified Representation Autoencoder (3D-URAE); it leverages pretrained 3D foundation models and augments their geometry-centric nature by injecting appearance and distilling semantics into a unified 3D latent space. Furthermore, we introduce token-level Cross-View-Correspondence (CVC) consistency loss to explicitly enforce structural alignment across views, and propose Manifold-Drift Forcing (MDF) to mitigate train-inference exposure bias and shape a robust 3D manifold by mixing drifted and original representations. Comprehensive experiments demonstrate that OneWorld generates high-quality 3D scenes with superior cross-view consistency compared to state-of-the-art 2D-based methods. Our code will be available at https://github.com/SensenGao/OneWorld.
Does Your 3D Encoder Really Work? When Pretrain-SFT from 2D VLMs Meets 3D VLMs
Jun 06, 2025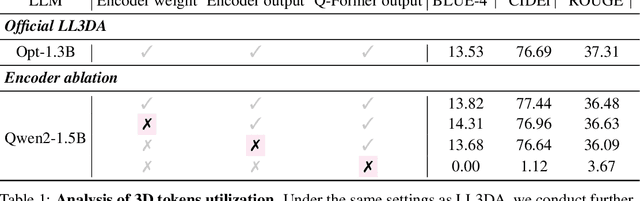
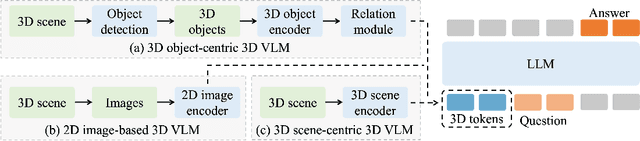

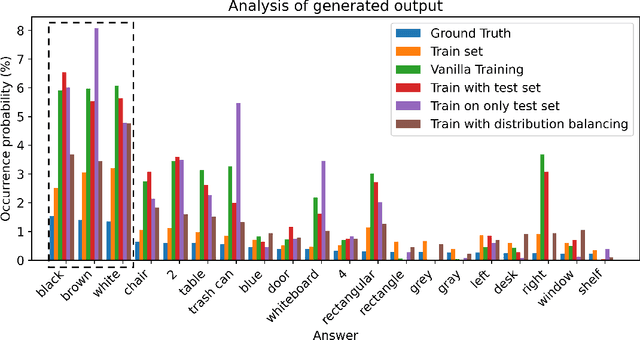
Remarkable progress in 2D Vision-Language Models (VLMs) has spurred interest in extending them to 3D settings for tasks like 3D Question Answering, Dense Captioning, and Visual Grounding. Unlike 2D VLMs that typically process images through an image encoder, 3D scenes, with their intricate spatial structures, allow for diverse model architectures. Based on their encoder design, this paper categorizes recent 3D VLMs into 3D object-centric, 2D image-based, and 3D scene-centric approaches. Despite the architectural similarity of 3D scene-centric VLMs to their 2D counterparts, they have exhibited comparatively lower performance compared with the latest 3D object-centric and 2D image-based approaches. To understand this gap, we conduct an in-depth analysis, revealing that 3D scene-centric VLMs show limited reliance on the 3D scene encoder, and the pre-train stage appears less effective than in 2D VLMs. Furthermore, we observe that data scaling benefits are less pronounced on larger datasets. Our investigation suggests that while these models possess cross-modal alignment capabilities, they tend to over-rely on linguistic cues and overfit to frequent answer distributions, thereby diminishing the effective utilization of the 3D encoder. To address these limitations and encourage genuine 3D scene understanding, we introduce a novel 3D Relevance Discrimination QA dataset designed to disrupt shortcut learning and improve 3D understanding. Our findings highlight the need for advanced evaluation and improved strategies for better 3D understanding in 3D VLMs.
Refinement for Absolute Pose Regression with Neural Feature Synthesis
Mar 17, 2023Absolute Pose Regression (APR) methods use deep neural networks to directly regress camera poses from RGB images. Despite their advantages in inference speed and simplicity, these methods still fall short of the accuracy achieved by geometry-based techniques. To address this issue, we propose a new model called the Neural Feature Synthesizer (NeFeS). Our approach encodes 3D geometric features during training and renders dense novel view features at test time to refine estimated camera poses from arbitrary APR methods. Unlike previous APR works that require additional unlabeled training data, our method leverages implicit geometric constraints during test time using a robust feature field. To enhance the robustness of our NeFeS network, we introduce a feature fusion module and a progressive training strategy. Our proposed method improves the state-of-the-art single-image APR accuracy by as much as 54.9% on indoor and outdoor benchmark datasets without additional time-consuming unlabeled data training.
Visual Odometry Revisited: What Should Be Learnt?
Oct 03, 2019

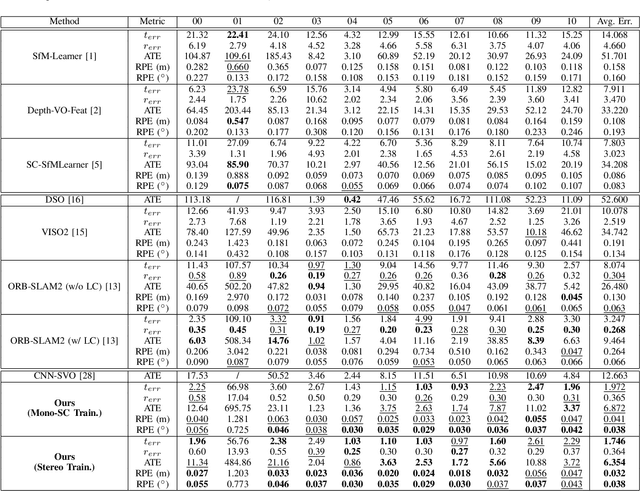
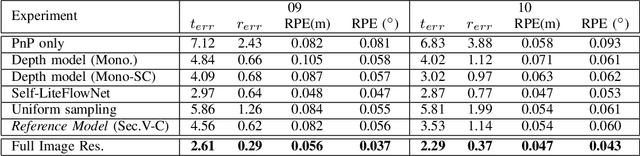
In this work we present a monocular visual odometry (VO) algorithm which leverages geometry-based methods and deep learning. Most existing VO/SLAM systems with superior performance are based on geometry and have to be carefully designed for different application scenarios. Moreover, most monocular systems suffer from scale-drift issue. Some recent deep learning works learn VO in an end-to-end manner but the performance of these deep systems is still not comparable to geometry-based methods. In this work, we revisit the basics of VO and explore the right way for integrating deep learning with epipolar geometry and Perspective-n-Point (PnP) method. Specifically, we train two convolutional neural networks (CNNs) for estimating single-view depths and two-view optical flows as intermediate outputs. With the deep predictions, we design a simple but robust frame-to-frame VO algorithm (DF-VO) which outperforms pure deep learning-based and geometry-based methods. More importantly, our system does not suffer from the scale-drift issue being aided by a scale consistent single-view depth CNN. Extensive experiments on KITTI dataset shows the robustness of our system and a detailed ablation study shows the effect of different factors in our system.