 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluSplat: Sparse-View 3D Editing without Test-Time Optimization
Apr 21, 2026Recent advances in text-guided image editing and 3D Gaussian Splatting (3DGS) have enabled high-quality 3D scene manipulation. However, existing pipelines rely on iterative edit-and-fit optimization at test time, alternating between 2D diffusion editing and 3D reconstruction. This process is computationally expensive, scene-specific, and prone to cross-view inconsistencies. We propose a feed-forward framework for cross-view consistent 3D scene editing from sparse views. Instead of enforcing consistency through iterative 3D refinement, we introduce a cross-view regularization scheme in the image domain during training. By jointly supervising multi-view edits with geometric alignment constraints, our model produces view-consistent results without per-scene optimization at inference. The edited views are then lifted into 3D via a feedforward 3DGS model, yielding a coherent 3DGS representation in a single forward pass. Experiments demonstrate competitive editing fidelity and substantially improved cross-view consistency compared to optimization-based methods, while reducing inference time by orders of magnitude.
FAST3DIS: Feed-forward Anchored Scene Transformer for 3D Instance Segmentation
Mar 27, 2026While recent feed-forward 3D reconstruction models provide a strong geometric foundation for scene understanding, extending them to 3D instance segmentation typically relies on a disjointed "lift-and-cluster" paradigm. Grouping dense pixel-wise embeddings via non-differentiable clustering scales poorly with the number of views and disconnects representation learning from the final segmentation objective. In this paper, we present a Feed-forward Anchored Scene Transformer for 3D Instance Segmentation (FAST3DIS), an end-to-end approach that effectively bypasses post-hoc clustering. We introduce a 3D-anchored, query-based Transformer architecture built upon a foundational depth backbone, adapted efficiently to learn instance-specific semantics while retaining its zero-shot geometric priors. We formulate a learned 3D anchor generator coupled with an anchor-sampling cross-attention mechanism for view-consistent 3D instance segmentation. By projecting 3D object queries directly into multi-view feature maps, our method samples context efficiently. Furthermore, we introduce a dual-level regularization strategy, that couples multi-view contrastive learning with a dynamically scheduled spatial overlap penalty to explicitly prevent query collisions and ensure precise instance boundaries. Experiments on complex indoor 3D datasets demonstrate that our approach achieves competitive segmentation accuracy with significantly improved memory scalability and inference speed over state-of-the-art clustering-based methods.
RLGS: Reinforcement Learning-Based Adaptive Hyperparameter Tuning for Gaussian Splatting
Aug 06, 2025



Hyperparameter tuning in 3D Gaussian Splatting (3DGS) is a labor-intensive and expert-driven process, often resulting in inconsistent reconstructions and suboptimal results. We propose RLGS, a plug-and-play reinforcement learning framework for adaptive hyperparameter tuning in 3DGS through lightweight policy modules, dynamically adjusting critical hyperparameters such as learning rates and densification thresholds. The framework is model-agnostic and seamlessly integrates into existing 3DGS pipelines without architectural modifications. We demonstrate its generalization ability across multiple state-of-the-art 3DGS variants, including Taming-3DGS and 3DGS-MCMC, and validate its robustness across diverse datasets. RLGS consistently enhances rendering quality. For example, it improves Taming-3DGS by 0.7dB PSNR on the Tanks and Temple (TNT) dataset, under a fixed Gaussian budget, and continues to yield gains even when baseline performance saturates. Our results suggest that RLGS provides an effective and general solution for automating hyperparameter tuning in 3DGS training, bridging a gap in applying reinforcement learning to 3DGS.
Semantic Consistent Language Gaussian Splatting for Point-Level Open-vocabulary Querying
Mar 27, 2025Open-vocabulary querying in 3D Gaussian Splatting aims to identify semantically relevant regions within a 3D Gaussian representation based on a given text query. Prior work, such as LangSplat, addressed this task by retrieving these regions in the form of segmentation masks on 2D renderings. More recently, OpenGaussian introduced point-level querying, which directly selects a subset of 3D Gaussians. In this work, we propose a point-level querying method that builds upon LangSplat's framework. Our approach improves the framework in two key ways: (a) we leverage masklets from the Segment Anything Model 2 (SAM2) to establish semantic consistent ground-truth for distilling the language Gaussians; (b) we introduces a novel two-step querying approach that first retrieves the distilled ground-truth and subsequently uses the ground-truth to query the individual Gaussians. Experimental evaluations on three benchmark datasets demonstrate that the proposed method achieves better performance compared to state-of-the-art approaches. For instance, our method achieves an mIoU improvement of +20.42 on the 3D-OVS dataset.
ActiveGAMER: Active GAussian Mapping through Efficient Rendering
Jan 12, 2025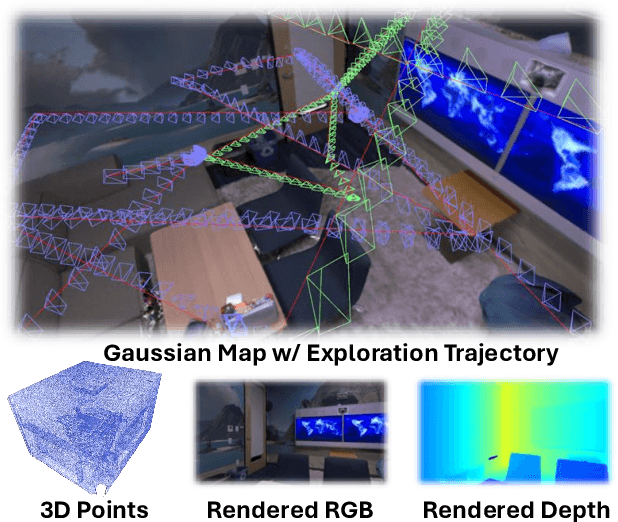
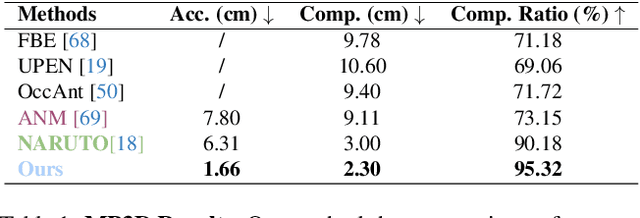

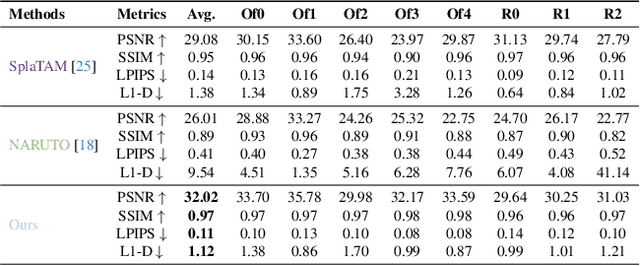
We introduce ActiveGAMER, an active mapping system that utilizes 3D Gaussian Splatting (3DGS) to achieve high-quality, real-time scene mapping and exploration. Unlike traditional NeRF-based methods, which are computationally demanding and restrict active mapping performance, our approach leverages the efficient rendering capabilities of 3DGS, allowing effective and efficient exploration in complex environments. The core of our system is a rendering-based information gain module that dynamically identifies the most informative viewpoints for next-best-view planning, enhancing both geometric and photometric reconstruction accuracy. ActiveGAMER also integrates a carefully balanced framework, combining coarse-to-fine exploration, post-refinement, and a global-local keyframe selection strategy to maximize reconstruction completeness and fidelity. Our system autonomously explores and reconstructs environments with state-of-the-art geometric and photometric accuracy and completeness, significantly surpassing existing approaches in both aspects. Extensive evaluations on benchmark datasets such as Replica and MP3D highlight ActiveGAMER's effectiveness in active mapping tasks.
NARUTO: Neural Active Reconstruction from Uncertain Target Observations
Feb 29, 2024We present NARUTO, a neural active reconstruction system that combines a hybrid neural representation with uncertainty learning, enabling high-fidelity surface reconstruction. Our approach leverages a multi-resolution hash-grid as the mapping backbone, chosen for its exceptional convergence speed and capacity to capture high-frequency local features.The centerpiece of our work is the incorporation of an uncertainty learning module that dynamically quantifies reconstruction uncertainty while actively reconstructing the environment. By harnessing learned uncertainty, we propose a novel uncertainty aggregation strategy for goal searching and efficient path planning. Our system autonomously explores by targeting uncertain observations and reconstructs environments with remarkable completeness and fidelity. We also demonstrate the utility of this uncertainty-aware approach by enhancing SOTA neural SLAM systems through an active ray sampling strategy. Extensive evaluations of NARUTO in various environments, using an indoor scene simulator, confirm its superior performance and state-of-the-art status in active reconstruction, as evidenced by its impressive results on benchmark datasets like Replica and MP3D.
PlanarNeRF: Online Learning of Planar Primitives with Neural Radiance Fields
Dec 30, 2023Identifying spatially complete planar primitives from visual data is a crucial task in computer vision. Prior methods are largely restricted to either 2D segment recovery or simplifying 3D structures, even with extensive plane annotations. We present PlanarNeRF, a novel framework capable of detecting dense 3D planes through online learning. Drawing upon the neural field representation, PlanarNeRF brings three major contributions. First, it enhances 3D plane detection with concurrent appearance and geometry knowledge. Second, a lightweight plane fitting module is proposed to estimate plane parameters. Third, a novel global memory bank structure with an update mechanism is introduced, ensuring consistent cross-frame correspondence. The flexible architecture of PlanarNeRF allows it to function in both 2D-supervised and self-supervised solutions, in each of which it can effectively learn from sparse training signals, significantly improving training efficiency. Through extensive experiments, we demonstrate the effectiveness of PlanarNeRF in various scenarios and remarkable improvement over existing works.
Dynamic Voxel Grid Optimization for High-Fidelity RGB-D Supervised Surface Reconstruction
Apr 12, 2023Direct optimization of interpolated features on multi-resolution voxel grids has emerged as a more efficient alternative to MLP-like modules. However, this approach is constrained by higher memory expenses and limited representation capabilities. In this paper, we introduce a novel dynamic grid optimization method for high-fidelity 3D surface reconstruction that incorporates both RGB and depth observations. Rather than treating each voxel equally, we optimize the process by dynamically modifying the grid and assigning more finer-scale voxels to regions with higher complexity, allowing us to capture more intricate details. Furthermore, we develop a scheme to quantify the dynamic subdivision of voxel grid during optimization without requiring any priors. The proposed approach is able to generate high-quality 3D reconstructions with fine details on both synthetic and real-world data, while maintaining computational efficiency, which is substantially faster than the baseline method NeuralRGBD.
ActiveRMAP: Radiance Field for Active Mapping And Planning
Nov 23, 2022A high-quality 3D reconstruction of a scene from a collection of 2D images can be achieved through offline/online mapping methods. In this paper, we explore active mapping from the perspective of implicit representations, which have recently produced compelling results in a variety of applications. One of the most popular implicit representations - Neural Radiance Field (NeRF), first demonstrated photorealistic rendering results using multi-layer perceptrons, with promising offline 3D reconstruction as a by-product of the radiance field. More recently, researchers also applied this implicit representation for online reconstruction and localization (i.e. implicit SLAM systems). However, the study on using implicit representation for active vision tasks is still very limited. In this paper, we are particularly interested in applying the neural radiance field for active mapping and planning problems, which are closely coupled tasks in an active system. We, for the first time, present an RGB-only active vision framework using radiance field representation for active 3D reconstruction and planning in an online manner. Specifically, we formulate this joint task as an iterative dual-stage optimization problem, where we alternatively optimize for the radiance field representation and path planning. Experimental results suggest that the proposed method achieves competitive results compared to other offline methods and outperforms active reconstruction methods using NeRFs.
Predicting Topological Maps for Visual Navigation in Unexplored Environments
Nov 23, 2022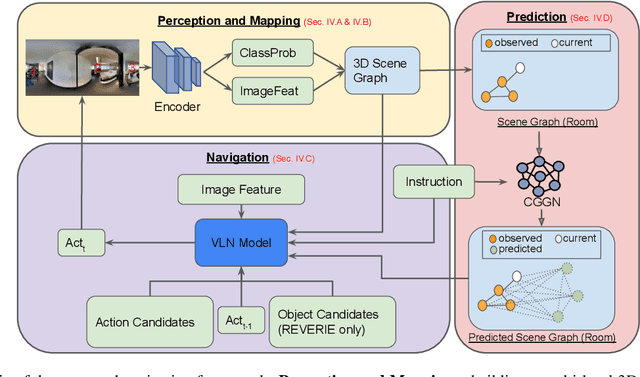
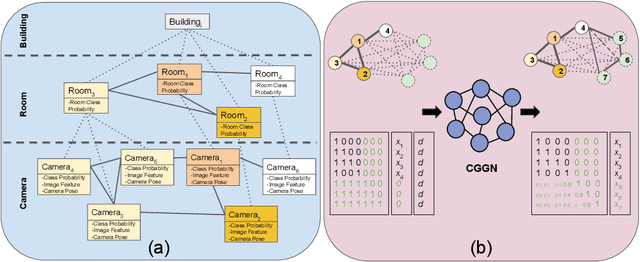

We propose a robotic learning system for autonomous exploration and navigation in unexplored environments. We are motivated by the idea that even an unseen environment may be familiar from previous experiences in similar environments. The core of our method, therefore, is a process for building, predicting, and using probabilistic layout graphs for assisting goal-based visual navigation. We describe a navigation system that uses the layout predictions to satisfy high-level goals (e.g. "go to the kitchen") more rapidly and accurately than the prior art. Our proposed navigation framework comprises three stages: (1) Perception and Mapping: building a multi-level 3D scene graph; (2) Prediction: predicting probabilistic 3D scene graph for the unexplored environment; (3) Navigation: assisting navigation with the graphs. We test our framework in Matterport3D and show more success and efficient navigation in unseen environments.