 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-Detect: A Simple yet Effective Framework for Blur-Robust AI-Generated Image Detection
Nov 18, 2025With growing concerns over image authenticity and digital safety, the field of AI-generated image (AIGI) detection has progressed rapidly. Yet, most AIGI detectors still struggle under real-world degradations, particularly motion blur, which frequently occurs in handheld photography, fast motion, and compressed video. Such blur distorts fine textures and suppresses high-frequency artifacts, causing severe performance drops in real-world settings. We address this limitation with a blur-robust AIGI detection framework based on teacher-student knowledge distillation. A high-capacity teacher (DINOv3), trained on clean (i.e., sharp) images, provides stable and semantically rich representations that serve as a reference for learning. By freezing the teacher to maintain its generalization ability, we distill its feature and logit responses from sharp images to a student trained on blurred counterparts, enabling the student to produce consistent representations under motion degradation. Extensive experiments benchmarks show that our method achieves state-of-the-art performance under both motion-blurred and clean conditions, demonstrating improved generalization and real-world applicability. Source codes will be released at: https://github.com/JiaLiangShen/Dino-Detect-for-blur-robust-AIGC-Detection.
MedDCR: Learning to Design Agentic Workflows for Medical Coding
Nov 17, 2025Medical coding converts free-text clinical notes into standardized diagnostic and procedural codes, which are essential for billing, hospital operations, and medical research. Unlike ordinary text classification, it requires multi-step reasoning: extracting diagnostic concepts, applying guideline constraints, mapping to hierarchical codebooks, and ensuring cross-document consistency. Recent advances leverage agentic LLMs, but most rely on rigid, manually crafted workflows that fail to capture the nuance and variability of real-world documentation, leaving open the question of how to systematically learn effective workflows. We present MedDCR, a closed-loop framework that treats workflow design as a learning problem. A Designer proposes workflows, a Coder executes them, and a Reflector evaluates predictions and provides constructive feedback, while a memory archive preserves prior designs for reuse and iterative refinement. On benchmark datasets, MedDCR outperforms state-of-the-art baselines and produces interpretable, adaptable workflows that better reflect real coding practice, improving both the reliability and trustworthiness of automated systems.
Ranked from Within: Ranking Large Multimodal Models for Visual Question Answering Without Labels
Dec 09, 2024



As large multimodal models (LMMs) are increasingly deployed across diverse applications, the need for adaptable, real-world model ranking has become paramount. Traditional evaluation methods are largely dataset-centric, relying on fixed, labeled datasets and supervised metrics, which are resource-intensive and may lack generalizability to novel scenarios, highlighting the importance of unsupervised ranking. In this work, we explore unsupervised model ranking for LMMs by leveraging their uncertainty signals, such as softmax probabilities. We evaluate state-of-the-art LMMs (e.g., LLaVA) across visual question answering benchmarks, analyzing how uncertainty-based metrics can reflect model performance. Our findings show that uncertainty scores derived from softmax distributions provide a robust, consistent basis for ranking models across varied tasks. This finding enables the ranking of LMMs on real-world, unlabeled data for visual question answering, providing a practical approach for selecting models across diverse domains without requiring manual annotation.
ActiveRMAP: Radiance Field for Active Mapping And Planning
Nov 23, 2022A high-quality 3D reconstruction of a scene from a collection of 2D images can be achieved through offline/online mapping methods. In this paper, we explore active mapping from the perspective of implicit representations, which have recently produced compelling results in a variety of applications. One of the most popular implicit representations - Neural Radiance Field (NeRF), first demonstrated photorealistic rendering results using multi-layer perceptrons, with promising offline 3D reconstruction as a by-product of the radiance field. More recently, researchers also applied this implicit representation for online reconstruction and localization (i.e. implicit SLAM systems). However, the study on using implicit representation for active vision tasks is still very limited. In this paper, we are particularly interested in applying the neural radiance field for active mapping and planning problems, which are closely coupled tasks in an active system. We, for the first time, present an RGB-only active vision framework using radiance field representation for active 3D reconstruction and planning in an online manner. Specifically, we formulate this joint task as an iterative dual-stage optimization problem, where we alternatively optimize for the radiance field representation and path planning. Experimental results suggest that the proposed method achieves competitive results compared to other offline methods and outperforms active reconstruction methods using NeRFs.
Towards Open-Set Object Detection and Discovery
Apr 12, 2022



With the human pursuit of knowledge, open-set object detection (OSOD) has been designed to identify unknown objects in a dynamic world. However, an issue with the current setting is that all the predicted unknown objects share the same category as "unknown", which require incremental learning via a human-in-the-loop approach to label novel classes. In order to address this problem, we present a new task, namely Open-Set Object Detection and Discovery (OSODD). This new task aims to extend the ability of open-set object detectors to further discover the categories of unknown objects based on their visual appearance without human effort. We propose a two-stage method that first uses an open-set object detector to predict both known and unknown objects. Then, we study the representation of predicted objects in an unsupervised manner and discover new categories from the set of unknown objects. With this method, a detector is able to detect objects belonging to known classes and define novel categories for objects of unknown classes with minimal supervision. We show the performance of our model on the MS-COCO dataset under a thorough evaluation protocol. We hope that our work will promote further research towards a more robust real-world detection system.
GOSS: Towards Generalized Open-set Semantic Segmentation
Mar 23, 2022

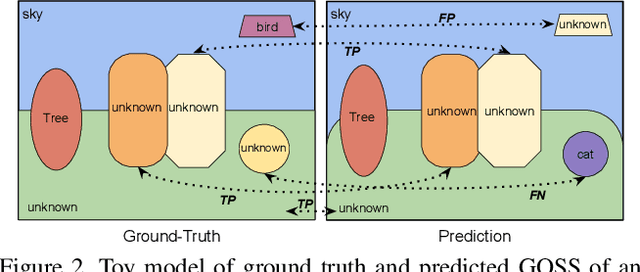
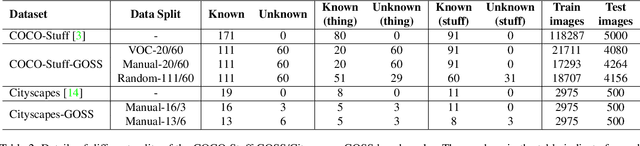
In this paper, we present and study a new image segmentation task, called Generalized Open-set Semantic Segmentation (GOSS). Previously, with the well-known open-set semantic segmentation (OSS), the intelligent agent only detects the unknown regions without further processing, limiting their perception of the environment. It stands to reason that a further analysis of the detected unknown pixels would be beneficial. Therefore, we propose GOSS, which unifies the abilities of two well-defined segmentation tasks, OSS and generic segmentation (GS), in a holistic way. Specifically, GOSS classifies pixels as belonging to known classes, and clusters (or groups) of pixels of unknown class are labelled as such. To evaluate this new expanded task, we further propose a metric which balances the pixel classification and clustering aspects. Moreover, we build benchmark tests on top of existing datasets and propose a simple neural architecture as a baseline, which jointly predicts pixel classification and clustering under open-set settings. Our experiments on multiple benchmarks demonstrate the effectiveness of our baseline. We believe our new GOSS task can produce an expressive image understanding for future research. Code will be made available.