 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
Dec 22, 2025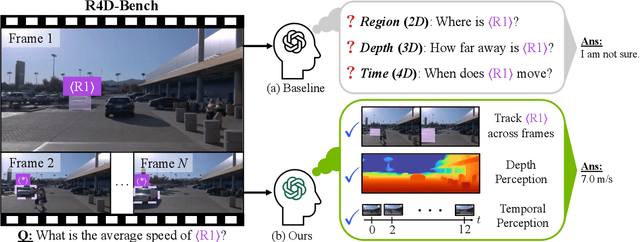

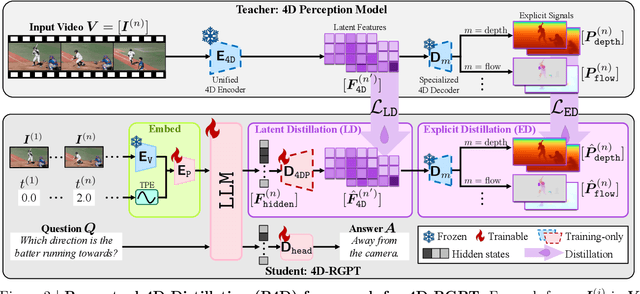
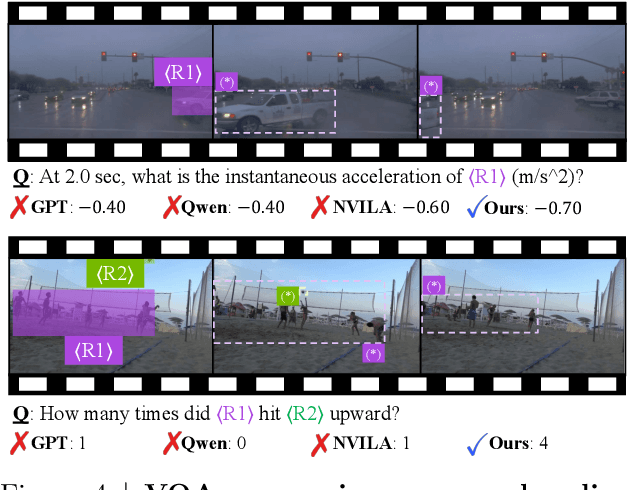
Despite advances in Multimodal LLMs (MLLMs), their ability to reason over 3D structures and temporal dynamics remains limited, constrained by weak 4D perception and temporal understanding. Existing 3D and 4D Video Question Answering (VQA) benchmarks also emphasize static scenes and lack region-level prompting. We tackle these issues by introducing: (a) 4D-RGPT, a specialized MLLM designed to capture 4D representations from video inputs with enhanced temporal perception; (b) Perceptual 4D Distillation (P4D), a training framework that transfers 4D representations from a frozen expert model into 4D-RGPT for comprehensive 4D perception; and (c) R4D-Bench, a benchmark for depth-aware dynamic scenes with region-level prompting, built via a hybrid automated and human-verified pipeline. Our 4D-RGPT achieves notable improvements on both existing 4D VQA benchmarks and the proposed R4D-Bench benchmark.
Auto-Vocabulary 3D Object Detection
Dec 18, 2025



Open-vocabulary 3D object detection methods are able to localize 3D boxes of classes unseen during training. Despite the name, existing methods rely on user-specified classes both at training and inference. We propose to study Auto-Vocabulary 3D Object Detection (AV3DOD), where the classes are automatically generated for the detected objects without any user input. To this end, we introduce Semantic Score (SS) to evaluate the quality of the generated class names. We then develop a novel framework, AV3DOD, which leverages 2D vision-language models (VLMs) to generate rich semantic candidates through image captioning, pseudo 3D box generation, and feature-space semantics expansion. AV3DOD achieves the state-of-the-art (SOTA) performance on both localization (mAP) and semantic quality (SS) on the ScanNetV2 and SUNRGB-D datasets. Notably, it surpasses the SOTA, CoDA, by 3.48 overall mAP and attains a 24.5% relative improvement in SS on ScanNetV2.
Knowledge Distillation Detection for Open-weights Models
Oct 02, 2025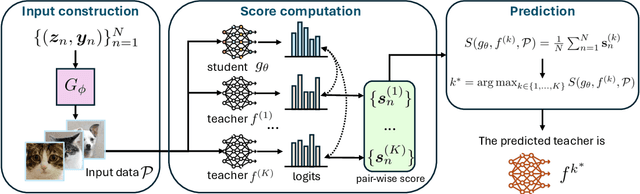

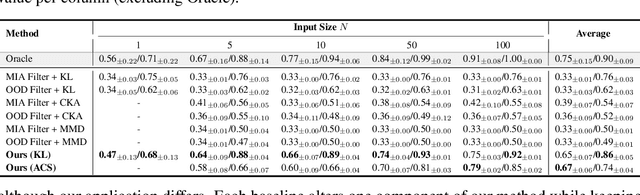
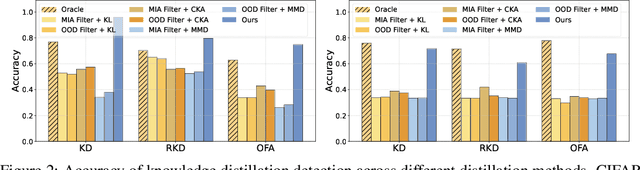
We propose the task of knowledge distillation detection, which aims to determine whether a student model has been distilled from a given teacher, under a practical setting where only the student's weights and the teacher's API are available. This problem is motivated by growing concerns about model provenance and unauthorized replication through distillation. To address this task, we introduce a model-agnostic framework that combines data-free input synthesis and statistical score computation for detecting distillation. Our approach is applicable to both classification and generative models. Experiments on diverse architectures for image classification and text-to-image generation show that our method improves detection accuracy over the strongest baselines by 59.6% on CIFAR-10, 71.2% on ImageNet, and 20.0% for text-to-image generation. The code is available at https://github.com/shqii1j/distillation_detection.
Heatmap Regression without Soft-Argmax for Facial Landmark Detection
Aug 19, 2025



Facial landmark detection is an important task in computer vision with numerous applications, such as head pose estimation, expression analysis, face swapping, etc. Heatmap regression-based methods have been widely used to achieve state-of-the-art results in this task. These methods involve computing the argmax over the heatmaps to predict a landmark. Since argmax is not differentiable, these methods use a differentiable approximation, Soft-argmax, to enable end-to-end training on deep-nets. In this work, we revisit this long-standing choice of using Soft-argmax and demonstrate that it is not the only way to achieve strong performance. Instead, we propose an alternative training objective based on the classic structured prediction framework. Empirically, our method achieves state-of-the-art performance on three facial landmark benchmarks (WFLW, COFW, and 300W), converging 2.2x faster during training while maintaining better/competitive accuracy. Our code is available here: https://github.com/ca-joe-yang/regression-without-softarg.
Local Scale Equivariance with Latent Deep Equilibrium Canonicalizer
Aug 19, 2025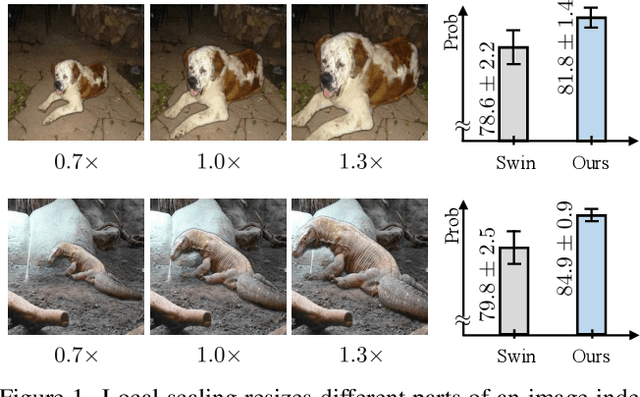
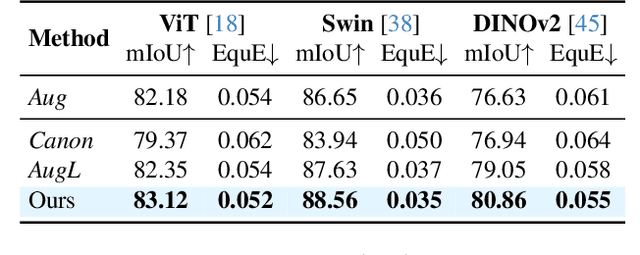
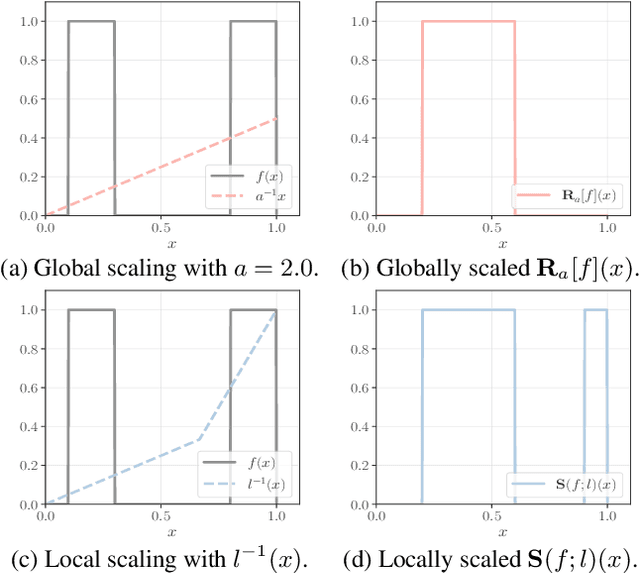

Scale variation is a fundamental challenge in computer vision. Objects of the same class can have different sizes, and their perceived size is further affected by the distance from the camera. These variations are local to the objects, i.e., different object sizes may change differently within the same image. To effectively handle scale variations, we present a deep equilibrium canonicalizer (DEC) to improve the local scale equivariance of a model. DEC can be easily incorporated into existing network architectures and can be adapted to a pre-trained model. Notably, we show that on the competitive ImageNet benchmark, DEC improves both model performance and local scale consistency across four popular pre-trained deep-nets, e.g., ViT, DeiT, Swin, and BEiT. Our code is available at https://github.com/ashiq24/local-scale-equivariance.
CLIPSym: Delving into Symmetry Detection with CLIP
Aug 19, 2025Symmetry is one of the most fundamental geometric cues in computer vision, and detecting it has been an ongoing challenge. With the recent advances in vision-language models,~i.e., CLIP, we investigate whether a pre-trained CLIP model can aid symmetry detection by leveraging the additional symmetry cues found in the natural image descriptions. We propose CLIPSym, which leverages CLIP's image and language encoders and a rotation-equivariant decoder based on a hybrid of Transformer and $G$-Convolution to detect rotation and reflection symmetries. To fully utilize CLIP's language encoder, we have developed a novel prompting technique called Semantic-Aware Prompt Grouping (SAPG), which aggregates a diverse set of frequent object-based prompts to better integrate the semantic cues for symmetry detection. Empirically, we show that CLIPSym outperforms the current state-of-the-art on three standard symmetry detection datasets (DENDI, SDRW, and LDRS). Finally, we conduct detailed ablations verifying the benefits of CLIP's pre-training, the proposed equivariant decoder, and the SAPG technique. The code is available at https://github.com/timyoung2333/CLIPSym.
Toward Long-Tailed Online Anomaly Detection through Class-Agnostic Concepts
Jul 22, 2025Anomaly detection (AD) identifies the defect regions of a given image. Recent works have studied AD, focusing on learning AD without abnormal images, with long-tailed distributed training data, and using a unified model for all classes. In addition, online AD learning has also been explored. In this work, we expand in both directions to a realistic setting by considering the novel task of long-tailed online AD (LTOAD). We first identified that the offline state-of-the-art LTAD methods cannot be directly applied to the online setting. Specifically, LTAD is class-aware, requiring class labels that are not available in the online setting. To address this challenge, we propose a class-agnostic framework for LTAD and then adapt it to our online learning setting. Our method outperforms the SOTA baselines in most offline LTAD settings, including both the industrial manufacturing and the medical domain. In particular, we observe +4.63% image-AUROC on MVTec even compared to methods that have access to class labels and the number of classes. In the most challenging long-tailed online setting, we achieve +0.53% image-AUROC compared to baselines. Our LTOAD benchmark is released here: https://doi.org/10.5281/zenodo.16283852 .
Model Immunization from a Condition Number Perspective
May 29, 2025Model immunization aims to pre-train models that are difficult to fine-tune on harmful tasks while retaining their utility on other non-harmful tasks. Though prior work has shown empirical evidence for immunizing text-to-image models, the key understanding of when immunization is possible and a precise definition of an immunized model remain unclear. In this work, we propose a framework, based on the condition number of a Hessian matrix, to analyze model immunization for linear models. Building on this framework, we design an algorithm with regularization terms to control the resulting condition numbers after pre-training. Empirical results on linear models and non-linear deep-nets demonstrate the effectiveness of the proposed algorithm on model immunization. The code is available at https://github.com/amberyzheng/model-immunization-cond-num.
DarkDiff: Advancing Low-Light Raw Enhancement by Retasking Diffusion Models for Camera ISP
May 29, 2025High-quality photography in extreme low-light conditions is challenging but impactful for digital cameras. With advanced computing hardware, traditional camera image signal processor (ISP) algorithms are gradually being replaced by efficient deep networks that enhance noisy raw images more intelligently. However, existing regression-based models often minimize pixel errors and result in oversmoothing of low-light photos or deep shadows. Recent work has attempted to address this limitation by training a diffusion model from scratch, yet those models still struggle to recover sharp image details and accurate colors. We introduce a novel framework to enhance low-light raw images by retasking pre-trained generative diffusion models with the camera ISP. Extensive experiments demonstrate that our method outperforms the state-of-the-art in perceptual quality across three challenging low-light raw image benchmarks.
Group Downsampling with Equivariant Anti-aliasing
Apr 24, 2025Downsampling layers are crucial building blocks in CNN architectures, which help to increase the receptive field for learning high-level features and reduce the amount of memory/computation in the model. In this work, we study the generalization of the uniform downsampling layer for group equivariant architectures, e.g., G-CNNs. That is, we aim to downsample signals (feature maps) on general finite groups with anti-aliasing. This involves the following: (a) Given a finite group and a downsampling rate, we present an algorithm to form a suitable choice of subgroup. (b) Given a group and a subgroup, we study the notion of bandlimited-ness and propose how to perform anti-aliasing. Notably, our method generalizes the notion of downsampling based on classical sampling theory. When the signal is on a cyclic group, i.e., periodic, our method recovers the standard downsampling of an ideal low-pass filter followed by a subsampling operation. Finally, we conducted experiments on image classification tasks demonstrating that the proposed downsampling operation improves accuracy, better preserves equivariance, and reduces model size when incorporated into G-equivariant networks