 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMMA: Immunizing text-to-image Models against Malicious Adaptation
Paper and Code
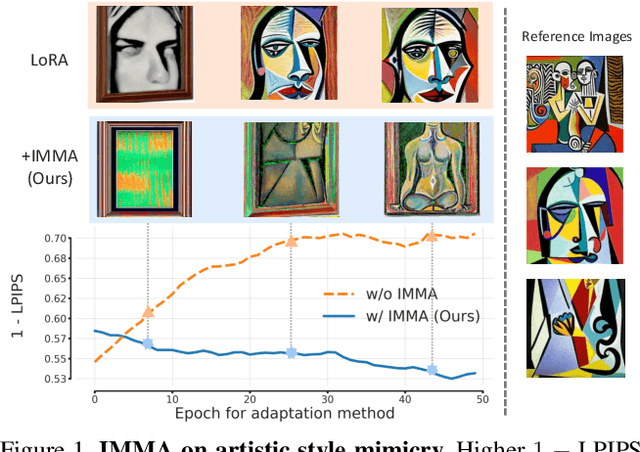
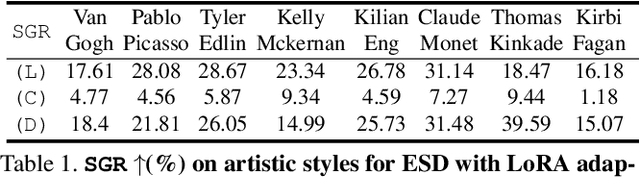


Advancements in text-to-image models and fine-tuning methods have led to the increasing risk of malicious adaptation, i.e., fine-tuning to generate harmful unauthorized content. Recent works, e.g., Glaze or MIST, have developed data-poisoning techniques which protect the data against adaptation methods. In this work, we consider an alternative paradigm for protection. We propose to ``immunize'' the model by learning model parameters that are difficult for the adaptation methods when fine-tuning malicious content; in short IMMA. Empirical results show IMMA's effectiveness against malicious adaptations, including mimicking the artistic style and learning of inappropriate/unauthorized content, over three adaptation methods: LoRA, Textual-Inversion, and DreamBooth.