 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning to Forget: Deep Semi-parametric Models for Unlearning
Mar 24, 2026Recent advances in machine unlearning have focused on developing algorithms to remove specific training samples from a trained model. In contrast, we observe that not all models are equally easy to unlearn. Hence, we introduce a family of deep semi-parametric models (SPMs) that exhibit non-parametric behavior during unlearning. SPMs use a fusion module that aggregates information from each training sample, enabling explicit test-time deletion of selected samples without altering model parameters. Empirically, we demonstrate that SPMs achieve competitive task performance to parametric models in image classification and generation, while being significantly more efficient for unlearning. Notably, on ImageNet classification, SPMs reduce the prediction gap relative to a retrained (oracle) baseline by $11\%$ and achieve over $10\times$ faster unlearning compared to existing approaches on parametric models. The code is available at https://github.com/amberyzheng/spm_unlearning.
Knowledge Distillation Detection for Open-weights Models
Oct 02, 2025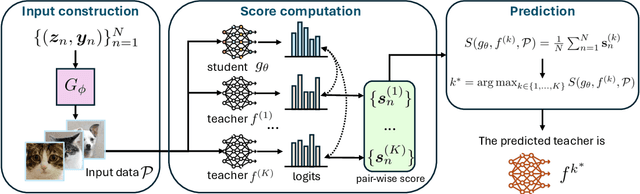

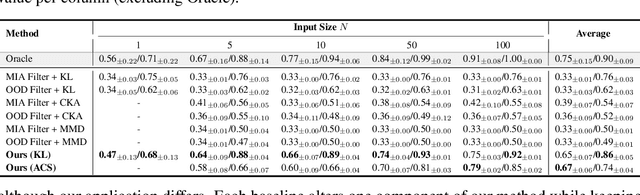
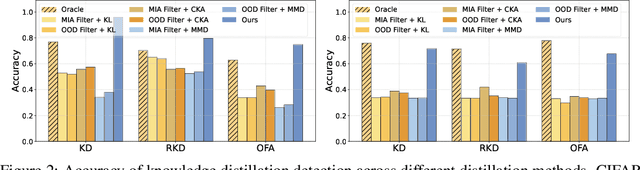
We propose the task of knowledge distillation detection, which aims to determine whether a student model has been distilled from a given teacher, under a practical setting where only the student's weights and the teacher's API are available. This problem is motivated by growing concerns about model provenance and unauthorized replication through distillation. To address this task, we introduce a model-agnostic framework that combines data-free input synthesis and statistical score computation for detecting distillation. Our approach is applicable to both classification and generative models. Experiments on diverse architectures for image classification and text-to-image generation show that our method improves detection accuracy over the strongest baselines by 59.6% on CIFAR-10, 71.2% on ImageNet, and 20.0% for text-to-image generation. The code is available at https://github.com/shqii1j/distillation_detection.
Model Immunization from a Condition Number Perspective
May 29, 2025Model immunization aims to pre-train models that are difficult to fine-tune on harmful tasks while retaining their utility on other non-harmful tasks. Though prior work has shown empirical evidence for immunizing text-to-image models, the key understanding of when immunization is possible and a precise definition of an immunized model remain unclear. In this work, we propose a framework, based on the condition number of a Hessian matrix, to analyze model immunization for linear models. Building on this framework, we design an algorithm with regularization terms to control the resulting condition numbers after pre-training. Empirical results on linear models and non-linear deep-nets demonstrate the effectiveness of the proposed algorithm on model immunization. The code is available at https://github.com/amberyzheng/model-immunization-cond-num.
DarkDiff: Advancing Low-Light Raw Enhancement by Retasking Diffusion Models for Camera ISP
May 29, 2025High-quality photography in extreme low-light conditions is challenging but impactful for digital cameras. With advanced computing hardware, traditional camera image signal processor (ISP) algorithms are gradually being replaced by efficient deep networks that enhance noisy raw images more intelligently. However, existing regression-based models often minimize pixel errors and result in oversmoothing of low-light photos or deep shadows. Recent work has attempted to address this limitation by training a diffusion model from scratch, yet those models still struggle to recover sharp image details and accurate colors. We introduce a novel framework to enhance low-light raw images by retasking pre-trained generative diffusion models with the camera ISP. Extensive experiments demonstrate that our method outperforms the state-of-the-art in perceptual quality across three challenging low-light raw image benchmarks.
CFG-Zero*: Improved Classifier-Free Guidance for Flow Matching Models
Mar 24, 2025



Classifier-Free Guidance (CFG) is a widely adopted technique in diffusion/flow models to improve image fidelity and controllability. In this work, we first analytically study the effect of CFG on flow matching models trained on Gaussian mixtures where the ground-truth flow can be derived. We observe that in the early stages of training, when the flow estimation is inaccurate, CFG directs samples toward incorrect trajectories. Building on this observation, we propose CFG-Zero*, an improved CFG with two contributions: (a) optimized scale, where a scalar is optimized to correct for the inaccuracies in the estimated velocity, hence the * in the name; and (b) zero-init, which involves zeroing out the first few steps of the ODE solver. Experiments on both text-to-image (Lumina-Next, Stable Diffusion 3, and Flux) and text-to-video (Wan-2.1) generation demonstrate that CFG-Zero* consistently outperforms CFG, highlighting its effectiveness in guiding Flow Matching models. (Code is available at github.com/WeichenFan/CFG-Zero-star)
Multi-concept Model Immunization through Differentiable Model Merging
Dec 19, 2024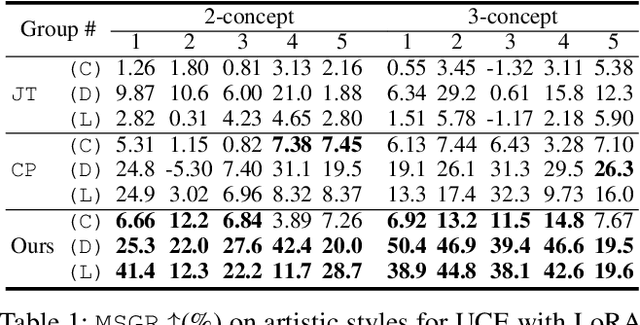
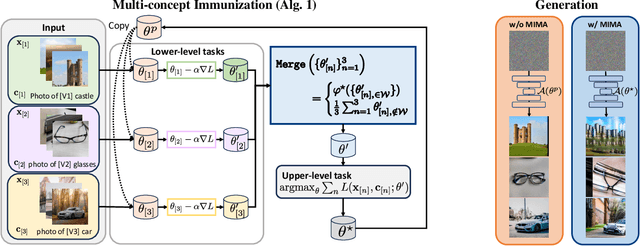

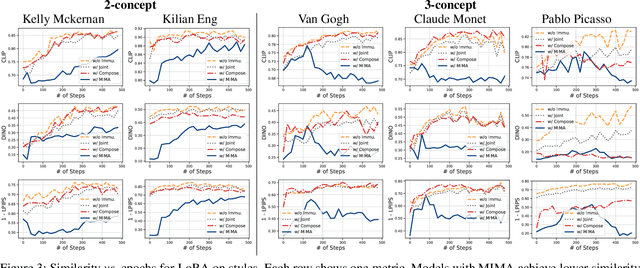
Model immunization is an emerging direction that aims to mitigate the potential risk of misuse associated with open-sourced models and advancing adaptation methods. The idea is to make the released models' weights difficult to fine-tune on certain harmful applications, hence the name ``immunized''. Recent work on model immunization focuses on the single-concept setting. However, models need to be immunized against multiple concepts in real-world situations. To address this gap, we propose an immunization algorithm that, simultaneously, learns a single ``difficult initialization'' for adaptation methods over a set of concepts. We achieve this by incorporating a differentiable merging layer that combines a set of model weights adapted over multiple concepts. In our experiments, we demonstrate the effectiveness of multi-concept immunization by generalizing prior work's experiment setup of re-learning and personalization adaptation to multiple concepts.
Learning to Obstruct Few-Shot Image Classification over Restricted Classes
Sep 28, 2024Advancements in open-source pre-trained backbones make it relatively easy to fine-tune a model for new tasks. However, this lowered entry barrier poses potential risks, e.g., bad actors developing models for harmful applications. A question arises: Is possible to develop a pre-trained model that is difficult to fine-tune for certain downstream tasks? To begin studying this, we focus on few-shot classification (FSC). Specifically, we investigate methods to make FSC more challenging for a set of restricted classes while maintaining the performance of other classes. We propose to meta-learn over the pre-trained backbone in a manner that renders it a ''poor initialization''. Our proposed Learning to Obstruct (LTO) algorithm successfully obstructs four FSC methods across three datasets, including ImageNet and CIFAR100 for image classification, as well as CelebA for attribute classification.
BloomGML: Graph Machine Learning through the Lens of Bilevel Optimization
Mar 07, 2024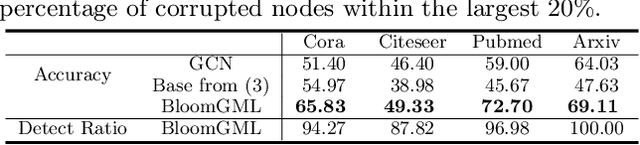


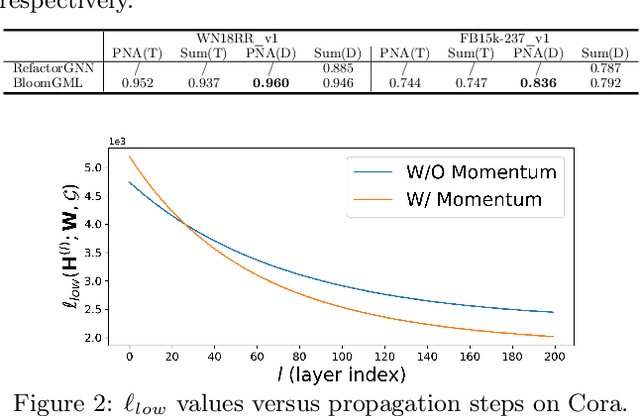
Bilevel optimization refers to scenarios whereby the optimal solution of a lower-level energy function serves as input features to an upper-level objective of interest. These optimal features typically depend on tunable parameters of the lower-level energy in such a way that the entire bilevel pipeline can be trained end-to-end. Although not generally presented as such, this paper demonstrates how a variety of graph learning techniques can be recast as special cases of bilevel optimization or simplifications thereof. In brief, building on prior work we first derive a more flexible class of energy functions that, when paired with various descent steps (e.g., gradient descent, proximal methods, momentum, etc.), form graph neural network (GNN) message-passing layers; critically, we also carefully unpack where any residual approximation error lies with respect to the underlying constituent message-passing functions. We then probe several simplifications of this framework to derive close connections with non-GNN-based graph learning approaches, including knowledge graph embeddings, various forms of label propagation, and efficient graph-regularized MLP models. And finally, we present supporting empirical results that demonstrate the versatility of the proposed bilevel lens, which we refer to as BloomGML, referencing that BiLevel Optimization Offers More Graph Machine Learning. Our code is available at https://github.com/amberyzheng/BloomGML. Let graph ML bloom.