 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Variance and Scale-Invariant Updates in Adaptive Gradient Descent for Unified Vector and Matrix Optimization
Feb 06, 2026Adaptive methods like Adam have become the $\textit{de facto}$ standard for large-scale vector and Euclidean optimization due to their coordinate-wise adaptation with a second-order nature. More recently, matrix-based spectral optimizers like Muon (Jordan et al., 2024b) show the power of treating weight matrices as matrices rather than long vectors. Linking these is hard because many natural generalizations are not feasible to implement, and we also cannot simply move the Adam adaptation to the matrix spectrum. To address this, we reformulate the AdaGrad update and decompose it into a variance adaptation term and a scale-invariant term. This decoupling produces $\textbf{DeVA}$ ($\textbf{De}$coupled $\textbf{V}$ariance $\textbf{A}$daptation), a framework that bridges between vector-based variance adaptation and matrix spectral optimization, enabling a seamless transition from Adam to adaptive spectral descent. Extensive experiments across language modeling and image classification demonstrate that DeVA consistently outperforms state-of-the-art methods such as Muon and SOAP (Vyas et al., 2024), reducing token usage by around 6.6\%. Theoretically, we show that the variance adaptation term effectively improves the blockwise smoothness, facilitating faster convergence. Our implementation is available at https://github.com/Tsedao/Decoupled-Variance-Adaptation
Stacey: Promoting Stochastic Steepest Descent via Accelerated $\ell_p$-Smooth Nonconvex Optimization
Jun 07, 2025While popular optimization methods such as SGD, AdamW, and Lion depend on steepest descent updates in either $\ell_2$ or $\ell_\infty$ norms, there remains a critical gap in handling the non-Euclidean structure observed in modern deep networks training. In this work, we address this need by introducing a new accelerated $\ell_p$ steepest descent algorithm, called Stacey, which uses interpolated primal-dual iterate sequences to effectively navigate non-Euclidean smooth optimization tasks. In addition to providing novel theoretical guarantees for the foundations of our algorithm, we empirically compare our approach against these popular methods on tasks including image classification and language model (LLM) pretraining, demonstrating both faster convergence and higher final accuracy. We further evaluate different values of $p$ across various models and datasets, underscoring the importance and efficiency of non-Euclidean approaches over standard Euclidean methods. Code can be found at https://github.com/xinyuluo8561/Stacey .
Model Immunization from a Condition Number Perspective
May 29, 2025Model immunization aims to pre-train models that are difficult to fine-tune on harmful tasks while retaining their utility on other non-harmful tasks. Though prior work has shown empirical evidence for immunizing text-to-image models, the key understanding of when immunization is possible and a precise definition of an immunized model remain unclear. In this work, we propose a framework, based on the condition number of a Hessian matrix, to analyze model immunization for linear models. Building on this framework, we design an algorithm with regularization terms to control the resulting condition numbers after pre-training. Empirical results on linear models and non-linear deep-nets demonstrate the effectiveness of the proposed algorithm on model immunization. The code is available at https://github.com/amberyzheng/model-immunization-cond-num.
Faster Acceleration for Steepest Descent
Sep 28, 2024
We propose a new accelerated first-order method for convex optimization under non-Euclidean smoothness assumptions. In contrast to standard acceleration techniques, our approach uses primal-dual iterate sequences taken with respect to differing norms, which are then coupled using an implicitly determined interpolation parameter. For $\ell_p$ norm smooth problems in $d$ dimensions, our method provides an iteration complexity improvement of up to $O(d^{1-\frac{2}{p}})$ in terms of calls to a first-order oracle, thereby allowing us to circumvent long-standing barriers in accelerated non-Euclidean steepest descent.
Tight Lower Bounds under Asymmetric High-Order Hölder Smoothness and Uniform Convexity
Sep 16, 2024In this paper, we provide tight lower bounds for the oracle complexity of minimizing high-order H\"older smooth and uniformly convex functions. Specifically, for a function whose $p^{th}$-order derivatives are H\"older continuous with degree $\nu$ and parameter $H$, and that is uniformly convex with degree $q$ and parameter $\sigma$, we focus on two asymmetric cases: (1) $q > p + \nu$, and (2) $q < p+\nu$. Given up to $p^{th}$-order oracle access, we establish worst-case oracle complexities of $\Omega\left( \left( \frac{H}{\sigma}\right)^\frac{2}{3(p+\nu)-2}\left( \frac{\sigma}{\epsilon}\right)^\frac{2(q-p-\nu)}{q(3(p+\nu)-2)}\right)$ with a truncated-Gaussian smoothed hard function in the first case and $\Omega\left(\left(\frac{H}{\sigma}\right)^\frac{2}{3(p+\nu)-2}+ \log^2\left(\frac{\sigma^{p+\nu}}{H^q}\right)^\frac{1}{p+\nu-q}\right)$ in the second case, for reaching an $\epsilon$-approximate solution in terms of the optimality gap. Our analysis generalizes previous lower bounds for functions under first- and second-order smoothness as well as those for uniformly convex functions, and furthermore our results match the corresponding upper bounds in the general setting.
Federated Composite Saddle Point Optimization
May 25, 2023Federated learning (FL) approaches for saddle point problems (SPP) have recently gained in popularity due to the critical role they play in machine learning (ML). Existing works mostly target smooth unconstrained objectives in Euclidean space, whereas ML problems often involve constraints or non-smooth regularization, which results in a need for composite optimization. Addressing these issues, we propose Federated Dual Extrapolation (FeDualEx), an extra-step primal-dual algorithm, which is the first of its kind that encompasses both saddle point optimization and composite objectives under the FL paradigm. Both the convergence analysis and the empirical evaluation demonstrate the effectiveness of FeDualEx in these challenging settings. In addition, even for the sequential version of FeDualEx, we provide rates for the stochastic composite saddle point setting which, to our knowledge, are not found in prior literature.
Beyond first-order methods for non-convex non-concave min-max optimization
Apr 17, 2023We propose a study of structured non-convex non-concave min-max problems which goes beyond standard first-order approaches. Inspired by the tight understanding established in recent works [Adil et al., 2022, Lin and Jordan, 2022b], we develop a suite of higher-order methods which show the improvements attainable beyond the monotone and Minty condition settings. Specifically, we provide a new understanding of the use of discrete-time $p^{th}$-order methods for operator norm minimization in the min-max setting, establishing an $O(1/\epsilon^\frac{2}{p})$ rate to achieve $\epsilon$-approximate stationarity, under the weakened Minty variational inequality condition of Diakonikolas et al. [2021]. We further present a continuous-time analysis alongside rates which match those for the discrete-time setting, and our empirical results highlight the practical benefits of our approach over first-order methods.
Variance-Reduced Conservative Policy Iteration
Dec 12, 2022
We study the sample complexity of reducing reinforcement learning to a sequence of empirical risk minimization problems over the policy space. Such reductions-based algorithms exhibit local convergence in the function space, as opposed to the parameter space for policy gradient algorithms, and thus are unaffected by the possibly non-linear or discontinuous parameterization of the policy class. We propose a variance-reduced variant of Conservative Policy Iteration that improves the sample complexity of producing a $\varepsilon$-functional local optimum from $O(\varepsilon^{-4})$ to $O(\varepsilon^{-3})$. Under state-coverage and policy-completeness assumptions, the algorithm enjoys $\varepsilon$-global optimality after sampling $O(\varepsilon^{-2})$ times, improving upon the previously established $O(\varepsilon^{-3})$ sample requirement.
A Stochastic Newton Algorithm for Distributed Convex Optimization
Oct 07, 2021
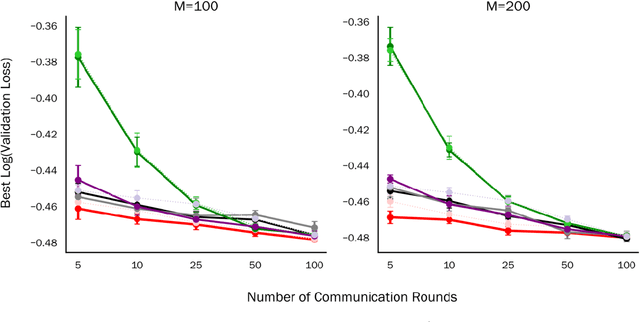

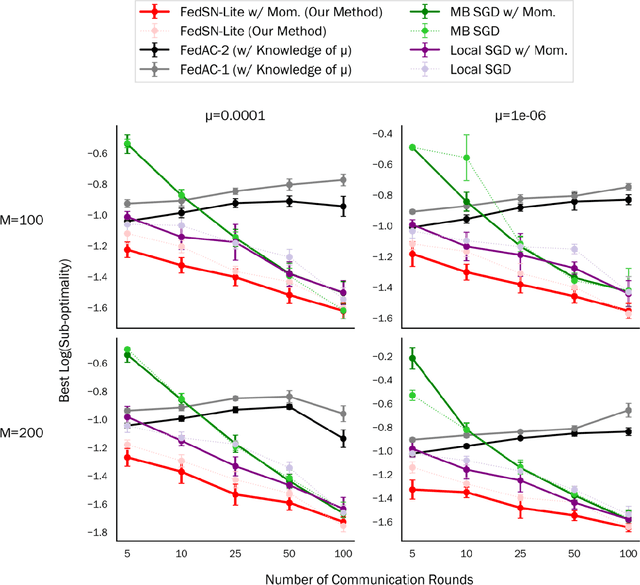
We propose and analyze a stochastic Newton algorithm for homogeneous distributed stochastic convex optimization, where each machine can calculate stochastic gradients of the same population objective, as well as stochastic Hessian-vector products (products of an independent unbiased estimator of the Hessian of the population objective with arbitrary vectors), with many such stochastic computations performed between rounds of communication. We show that our method can reduce the number, and frequency, of required communication rounds compared to existing methods without hurting performance, by proving convergence guarantees for quasi-self-concordant objectives (e.g., logistic regression), alongside empirical evidence.
The Min-Max Complexity of Distributed Stochastic Convex Optimization with Intermittent Communication
Feb 02, 2021We resolve the min-max complexity of distributed stochastic convex optimization (up to a log factor) in the intermittent communication setting, where $M$ machines work in parallel over the course of $R$ rounds of communication to optimize the objective, and during each round of communication, each machine may sequentially compute $K$ stochastic gradient estimates. We present a novel lower bound with a matching upper bound that establishes an optimal algorithm.