 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Min-Max Optimization: From Individual Regrets to Cumulative Saddle Points
Feb 11, 2026We propose and study an online version of min-max optimization based on cumulative saddle points under a variety of performance measures beyond convex-concave settings. After first observing the incompatibility of (static) Nash equilibrium (SNE-Reg$_T$) with individual regrets even for strongly convex-strongly concave functions, we propose an alternate \emph{static} duality gap (SDual-Gap$_T$) inspired by the online convex optimization (OCO) framework. We provide algorithms that, using a reduction to classic OCO problems, achieve bounds for SDual-Gap$_T$~and a novel \emph{dynamic} saddle point regret (DSP-Reg$_T$), which we suggest naturally represents a min-max version of the dynamic regret in OCO. We derive our bounds for SDual-Gap$_T$~and DSP-Reg$_T$~under strong convexity-strong concavity and a min-max notion of exponential concavity (min-max EC), and in addition we establish a class of functions satisfying min-max EC~that captures a two-player variant of the classic portfolio selection problem. Finally, for a dynamic notion of regret compatible with individual regrets, we derive bounds under a two-sided Polyak-Łojasiewicz (PL) condition.
Beyond first-order methods for non-convex non-concave min-max optimization
Apr 17, 2023We propose a study of structured non-convex non-concave min-max problems which goes beyond standard first-order approaches. Inspired by the tight understanding established in recent works [Adil et al., 2022, Lin and Jordan, 2022b], we develop a suite of higher-order methods which show the improvements attainable beyond the monotone and Minty condition settings. Specifically, we provide a new understanding of the use of discrete-time $p^{th}$-order methods for operator norm minimization in the min-max setting, establishing an $O(1/\epsilon^\frac{2}{p})$ rate to achieve $\epsilon$-approximate stationarity, under the weakened Minty variational inequality condition of Diakonikolas et al. [2021]. We further present a continuous-time analysis alongside rates which match those for the discrete-time setting, and our empirical results highlight the practical benefits of our approach over first-order methods.
Fast Resolution Agnostic Neural Techniques to Solve Partial Differential Equations
Jan 30, 2023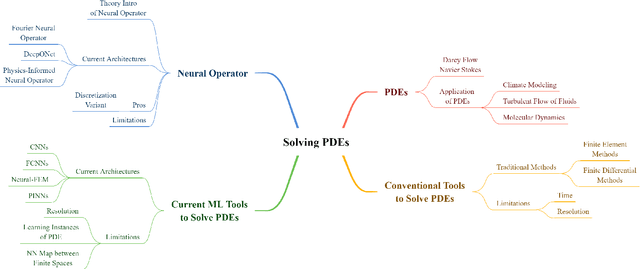



Numerical approximations of partial differential equations (PDEs) are routinely employed to formulate the solution of physics, engineering and mathematical problems involving functions of several variables, such as the propagation of heat or sound, fluid flow, elasticity, electrostatics, electrodynamics, and more. While this has led to solving many complex phenomena, there are still significant limitations. Conventional approaches such as Finite Element Methods (FEMs) and Finite Differential Methods (FDMs) require considerable time and are computationally expensive. In contrast, machine learning-based methods such as neural networks are faster once trained, but tend to be restricted to a specific discretization. This article aims to provide a comprehensive summary of conventional methods and recent machine learning-based methods to approximate PDEs numerically. Furthermore, we highlight several key architectures centered around the neural operator, a novel and fast approach (1000x) to learning the solution operator of a PDE. We will note how these new computational approaches can bring immense advantages in tackling many problems in fundamental and applied physics.
Competitive Gradient Optimization
May 27, 2022
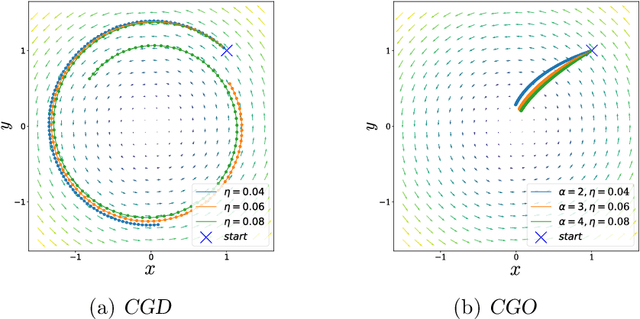


We study the problem of convergence to a stationary point in zero-sum games. We propose competitive gradient optimization (CGO ), a gradient-based method that incorporates the interactions between the two players in zero-sum games for optimization updates. We provide continuous-time analysis of CGO and its convergence properties while showing that in the continuous limit, CGO predecessors degenerate to their gradient descent ascent (GDA) variants. We provide a rate of convergence to stationary points and further propose a generalized class of $\alpha$-coherent function for which we provide convergence analysis. We show that for strictly $\alpha$-coherent functions, our algorithm convergences to a saddle point. Moreover, we propose optimistic CGO (OCGO), an optimistic variant, for which we show convergence rate to saddle points in $\alpha$-coherent class of functions.