 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Resolution Agnostic Neural Techniques to Solve Partial Differential Equations
Jan 30, 2023



Numerical approximations of partial differential equations (PDEs) are routinely employed to formulate the solution of physics, engineering and mathematical problems involving functions of several variables, such as the propagation of heat or sound, fluid flow, elasticity, electrostatics, electrodynamics, and more. While this has led to solving many complex phenomena, there are still significant limitations. Conventional approaches such as Finite Element Methods (FEMs) and Finite Differential Methods (FDMs) require considerable time and are computationally expensive. In contrast, machine learning-based methods such as neural networks are faster once trained, but tend to be restricted to a specific discretization. This article aims to provide a comprehensive summary of conventional methods and recent machine learning-based methods to approximate PDEs numerically. Furthermore, we highlight several key architectures centered around the neural operator, a novel and fast approach (1000x) to learning the solution operator of a PDE. We will note how these new computational approaches can bring immense advantages in tackling many problems in fundamental and applied physics.
Quantifying Human Bias and Knowledge to guide ML models during Training
Nov 19, 2022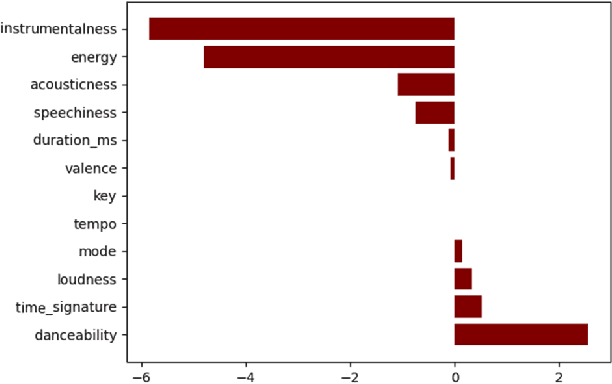
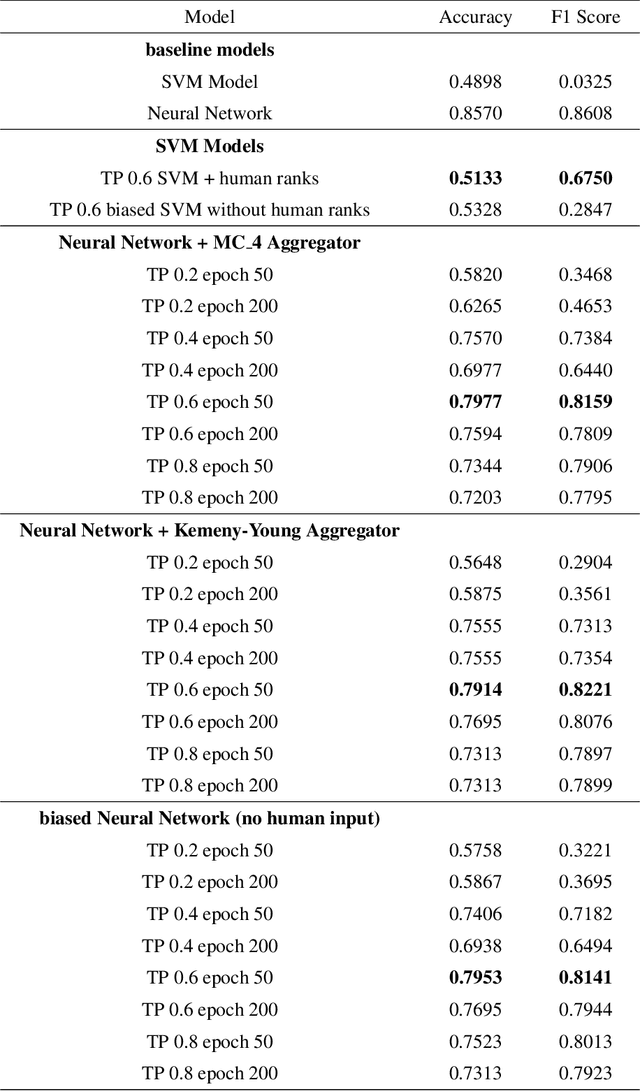
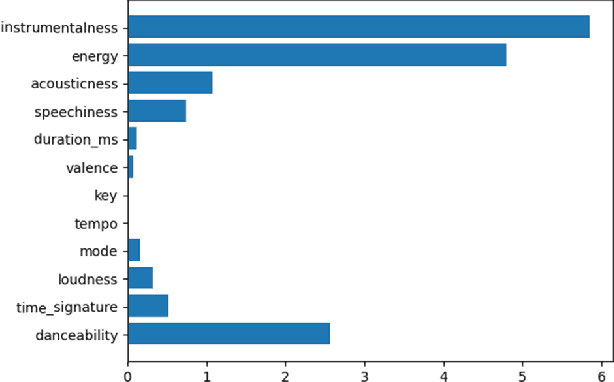
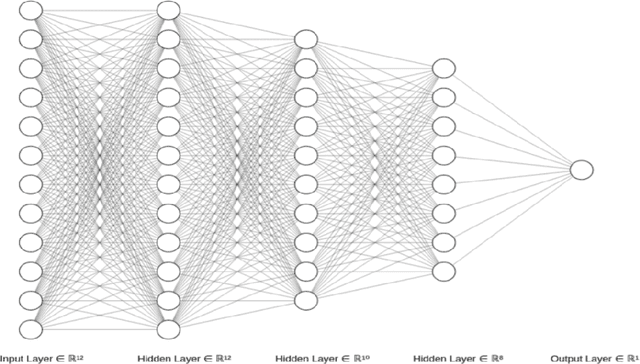
This paper discusses a crowdsourcing based method that we designed to quantify the importance of different attributes of a dataset in determining the outcome of a classification problem. This heuristic, provided by humans acts as the initial weight seed for machine learning models and guides the model towards a better optimal during the gradient descent process. Often times when dealing with data, it is not uncommon to deal with skewed datasets, that over represent items of certain classes, while underrepresenting the rest. Skewed datasets may lead to unforeseen issues with models such as learning a biased function or overfitting. Traditional data augmentation techniques in supervised learning include oversampling and training with synthetic data. We introduce an experimental approach to dealing with such unbalanced datasets by including humans in the training process. We ask humans to rank the importance of features of the dataset, and through rank aggregation, determine the initial weight bias for the model. We show that collective human bias can allow ML models to learn insights about the true population instead of the biased sample. In this paper, we use two rank aggregator methods Kemeny Young and the Markov Chain aggregator to quantify human opinion on importance of features. This work mainly tests the effectiveness of human knowledge on binary classification (Popular vs Not-popular) problems on two ML models: Deep Neural Networks and Support Vector Machines. This approach considers humans as weak learners and relies on aggregation to offset individual biases and domain unfamiliarity.
A Holistic Framework for Analyzing the COVID-19 Vaccine Debate
May 03, 2022


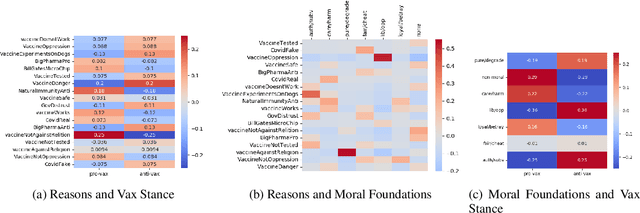
The Covid-19 pandemic has led to infodemic of low quality information leading to poor health decisions. Combating the outcomes of this infodemic is not only a question of identifying false claims, but also reasoning about the decisions individuals make. In this work we propose a holistic analysis framework connecting stance and reason analysis, and fine-grained entity level moral sentiment analysis. We study how to model the dependencies between the different level of analysis and incorporate human insights into the learning process. Experiments show that our framework provides reliable predictions even in the low-supervision settings.