 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Guided Teacher Alignment for Fair Personalized Text Generation
Jun 08, 2026Personalized persuasive text generation can improve relevance and engagement, but demographic conditioning may also introduce unequal framing across groups. We study fairness mitigation in personalized generation as a constrained multi-objective alignment problem: reduce demographic disparities while preserving personalization fidelity. We propose a Pareto-guided teacher alignment framework that combines revision-based candidate generation, pair-aware feasibility gating, Pareto-style candidate selection, and optional preference optimization through supervised fine-tuning and direct preference optimization. We evaluate the framework on climate change and vaccination persuasion tasks using a controlled context-rich demographic grid with matched gender and age pairs and a unified five-audit evaluation suite spanning persuasion bias, formality disparity, emotional framing disparity, lexical association disparity, and personalization fidelity. Across both domains and cross-family transfer settings, no single alignment strategy dominates all objectives simultaneously. Instead, methods occupy different regions of a fairness-personalization Pareto frontier: some achieve stronger disparity reductions, while others better preserve personalization or demographic stability. Our results show that fairness mitigation effects are objective-dependent and transfer inconsistently across domains and model families, motivating bounded-regression, multi-audit model selection over single-metric optimization for fairness-sensitive personalized generation.
Reasoning-Based Refinement of Unsupervised Text Clusters with LLMs
Apr 08, 2026Unsupervised methods are widely used to induce latent semantic structure from large text collections, yet their outputs often contain incoherent, redundant, or poorly grounded clusters that are difficult to validate without labeled data. We propose a reasoning-based refinement framework that leverages large language models (LLMs) not as embedding generators, but as semantic judges that validate and restructure the outputs of arbitrary unsupervised clustering algorithms.Our framework introduces three reasoning stages: (i) coherence verification, where LLMs assess whether cluster summaries are supported by their member texts; (ii) redundancy adjudication, where candidate clusters are merged or rejected based on semantic overlap; and (iii) label grounding, where clusters are assigned interpretable labels in a fully unsupervised manner. This design decouples representation learning from structural validation and mitigates common failure modes of embedding-only approaches. We evaluate the framework on real-world social media corpora from two platforms with distinct interaction models, demonstrating consistent improvements in cluster coherence and human-aligned labeling quality over classical topic models and recent representation-based baselines. Human evaluation shows strong agreement with LLM-generated labels, despite the absence of gold-standard annotations. We further conduct robustness analyses under matched temporal and volume conditions to assess cross-platform stability. Beyond empirical gains, our results suggest that LLM-based reasoning can serve as a general mechanism for validating and refining unsupervised semantic structure, enabling more reliable and interpretable analyses of large text collections without supervision.
Retrieval Improvements Do Not Guarantee Better Answers: A Study of RAG for AI Policy QA
Mar 25, 2026Retrieval-augmented generation (RAG) systems are increasingly used to analyze complex policy documents, but achieving sufficient reliability for expert usage remains challenging in domains characterized by dense legal language and evolving, overlapping regulatory frameworks. We study the application of RAG to AI governance and policy analysis using the AI Governance and Regulatory Archive (AGORA) corpus, a curated collection of 947 AI policy documents. Our system combines a ColBERT-based retriever fine-tuned with contrastive learning and a generator aligned to human preferences using Direct Preference Optimization (DPO). We construct synthetic queries and collect pairwise preferences to adapt the system to the policy domain. Through experiments evaluating retrieval quality, answer relevance, and faithfulness, we find that domain-specific fine-tuning improves retrieval metrics but does not consistently improve end-to-end question answering performance. In some cases, stronger retrieval counterintuitively leads to more confident hallucinations when relevant documents are absent from the corpus. These results highlight a key concern for those building policy-focused RAG systems: improvements to individual components do not necessarily translate to more reliable answers. Our findings provide practical insights for designing grounded question-answering systems over dynamic regulatory corpora.
Who Gets Which Message? Auditing Demographic Bias in LLM-Generated Targeted Text
Jan 23, 2026Large language models (LLMs) are increasingly capable of generating personalized, persuasive text at scale, raising new questions about bias and fairness in automated communication. This paper presents the first systematic analysis of how LLMs behave when tasked with demographic-conditioned targeted messaging. We introduce a controlled evaluation framework using three leading models -- GPT-4o, Llama-3.3, and Mistral-Large 2.1 -- across two generation settings: Standalone Generation, which isolates intrinsic demographic effects, and Context-Rich Generation, which incorporates thematic and regional context to emulate realistic targeting. We evaluate generated messages along three dimensions: lexical content, language style, and persuasive framing. We instantiate this framework on climate communication and find consistent age- and gender-based asymmetries across models: male- and youth-targeted messages emphasize agency, innovation, and assertiveness, while female- and senior-targeted messages stress warmth, care, and tradition. Contextual prompts systematically amplify these disparities, with persuasion scores significantly higher for messages tailored to younger or male audiences. Our findings demonstrate how demographic stereotypes can surface and intensify in LLM-generated targeted communication, underscoring the need for bias-aware generation pipelines and transparent auditing frameworks that explicitly account for demographic conditioning in socially sensitive applications.
Paid Voices vs. Public Feeds: Interpretable Cross-Platform Theme Modeling of Climate Discourse
Jan 19, 2026Climate discourse online plays a crucial role in shaping public understanding of climate change and influencing political and policy outcomes. However, climate communication unfolds across structurally distinct platforms with fundamentally different incentive structures: paid advertising ecosystems incentivize targeted, strategic persuasion, while public social media platforms host largely organic, user-driven discourse. Existing computational studies typically analyze these environments in isolation, limiting our ability to distinguish institutional messaging from public expression. In this work, we present a comparative analysis of climate discourse across paid advertisements on Meta (previously known as Facebook) and public posts on Bluesky from July 2024 to September 2025. We introduce an interpretable, end-to-end thematic discovery and assignment framework that clusters texts by semantic similarity and leverages large language models (LLMs) to generate concise, human-interpretable theme labels. We evaluate the quality of the induced themes against traditional topic modeling baselines using both human judgments and an LLM-based evaluator, and further validate their semantic coherence through downstream stance prediction and theme-guided retrieval tasks. Applying the resulting themes, we characterize systematic differences between paid climate messaging and public climate discourse and examine how thematic prevalence shifts around major political events. Our findings show that platform-level incentives are reflected in the thematic structure, stance alignment, and temporal responsiveness of climate narratives. While our empirical analysis focuses on climate communication, the proposed framework is designed to support comparative narrative analysis across heterogeneous communication environments.
Can LLMs Assist Annotators in Identifying Morality Frames? -- Case Study on Vaccination Debate on Social Media
Feb 04, 2025Nowadays, social media is pivotal in shaping public discourse, especially on polarizing issues like vaccination, where diverse moral perspectives influence individual opinions. In NLP, data scarcity and complexity of psycholinguistic tasks such as identifying morality frames makes relying solely on human annotators costly, time-consuming, and prone to inconsistency due to cognitive load. To address these issues, we leverage large language models (LLMs), which are adept at adapting new tasks through few-shot learning, utilizing a handful of in-context examples coupled with explanations that connect examples to task principles. Our research explores LLMs' potential to assist human annotators in identifying morality frames within vaccination debates on social media. We employ a two-step process: generating concepts and explanations with LLMs, followed by human evaluation using a "think-aloud" tool. Our study shows that integrating LLMs into the annotation process enhances accuracy, reduces task difficulty, lowers cognitive load, suggesting a promising avenue for human-AI collaboration in complex psycholinguistic tasks.
Post-hoc Study of Climate Microtargeting on Social Media Ads with LLMs: Thematic Insights and Fairness Evaluation
Oct 07, 2024
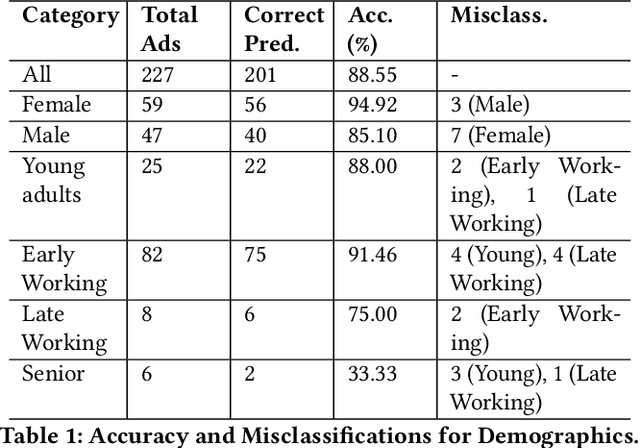

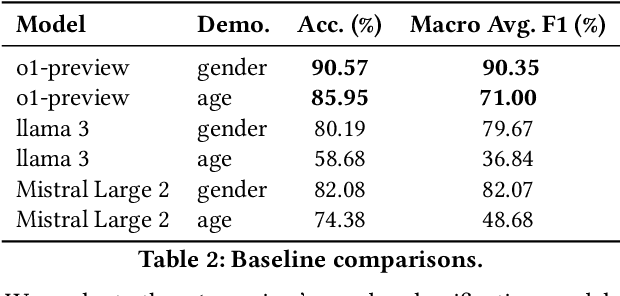
Climate change communication on social media increasingly employs microtargeting strategies to effectively reach and influence specific demographic groups. This study presents a post-hoc analysis of microtargeting practices within climate campaigns by leveraging large language models (LLMs) to examine Facebook advertisements. Our analysis focuses on two key aspects: demographic targeting and fairness. We evaluate the ability of LLMs to accurately predict the intended demographic targets, such as gender and age group, achieving an overall accuracy of 88.55%. Furthermore, we instruct the LLMs to generate explanations for their classifications, providing transparent reasoning behind each decision. These explanations reveal the specific thematic elements used to engage different demographic segments, highlighting distinct strategies tailored to various audiences. Our findings show that young adults are primarily targeted through messages emphasizing activism and environmental consciousness, while women are engaged through themes related to caregiving roles and social advocacy. In addition to evaluating the effectiveness of LLMs in detecting microtargeted messaging, we conduct a comprehensive fairness analysis to identify potential biases in model predictions. Our findings indicate that while LLMs perform well overall, certain biases exist, particularly in the classification of senior citizens and male audiences. By showcasing the efficacy of LLMs in dissecting and explaining targeted communication strategies and by highlighting fairness concerns, this study provides a valuable framework for future research aimed at enhancing transparency, accountability, and inclusivity in social media-driven climate campaigns.
Uncovering Latent Arguments in Social Media Messaging by Employing LLMs-in-the-Loop Strategy
Apr 16, 2024The widespread use of social media has led to a surge in popularity for automated methods of analyzing public opinion. Supervised methods are adept at text categorization, yet the dynamic nature of social media discussions poses a continual challenge for these techniques due to the constant shifting of the focus. On the other hand, traditional unsupervised methods for extracting themes from public discourse, such as topic modeling, often reveal overarching patterns that might not capture specific nuances. Consequently, a significant portion of research into social media discourse still depends on labor-intensive manual coding techniques and a human-in-the-loop approach, which are both time-consuming and costly. In this work, we study the problem of discovering arguments associated with a specific theme. We propose a generic LLMs-in-the-Loop strategy that leverages the advanced capabilities of Large Language Models (LLMs) to extract latent arguments from social media messaging. To demonstrate our approach, we apply our framework to contentious topics. We use two publicly available datasets: (1) the climate campaigns dataset of 14k Facebook ads with 25 themes and (2) the COVID-19 vaccine campaigns dataset of 9k Facebook ads with 14 themes. Furthermore, we analyze demographic targeting and the adaptation of messaging based on real-world events.
Uncovering Latent Themes of Messaging on Social Media by Integrating LLMs: A Case Study on Climate Campaigns
Mar 15, 2024This paper introduces a novel approach to uncovering and analyzing themes in social media messaging. Recognizing the limitations of traditional topic-level analysis, which tends to capture only the overarching patterns, this study emphasizes the need for a finer-grained, theme-focused exploration. Conventional methods of theme discovery, involving manual processes and a human-in-the-loop approach, are valuable but face challenges in scalability, consistency, and resource intensity in terms of time and cost. To address these challenges, we propose a machine-in-the-loop approach that leverages the advanced capabilities of Large Language Models (LLMs). This approach allows for a deeper investigation into the thematic aspects of social media discourse, enabling us to uncover a diverse array of themes, each with unique characteristics and relevance, thereby offering a comprehensive understanding of the nuances present within broader topics. Furthermore, this method efficiently maps the text and the newly discovered themes, enhancing our understanding of the thematic nuances in social media messaging. We employ climate campaigns as a case study and demonstrate that our methodology yields more accurate and interpretable results compared to traditional topic models. Our results not only demonstrate the effectiveness of our approach in uncovering latent themes but also illuminate how these themes are tailored for demographic targeting in social media contexts. Additionally, our work sheds light on the dynamic nature of social media, revealing the shifts in the thematic focus of messaging in response to real-world events.
Interactive Concept Learning for Uncovering Latent Themes in Large Text Collections
May 08, 2023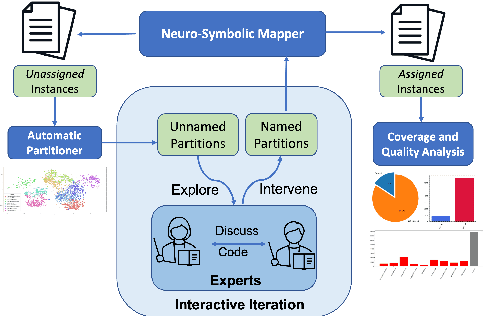



Experts across diverse disciplines are often interested in making sense of large text collections. Traditionally, this challenge is approached either by noisy unsupervised techniques such as topic models, or by following a manual theme discovery process. In this paper, we expand the definition of a theme to account for more than just a word distribution, and include generalized concepts deemed relevant by domain experts. Then, we propose an interactive framework that receives and encodes expert feedback at different levels of abstraction. Our framework strikes a balance between automation and manual coding, allowing experts to maintain control of their study while reducing the manual effort required.