 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHessianForge: Scalable LiDAR reconstruction with Physics-Informed Neural Representation and Smoothness Energy Constraints
Mar 11, 2025Accurate and efficient 3D mapping of large-scale outdoor environments from LiDAR measurements is a fundamental challenge in robotics, particularly towards ensuring smooth and artifact-free surface reconstructions. Although the state-of-the-art methods focus on memory-efficient neural representations for high-fidelity surface generation, they often fail to produce artifact-free manifolds, with artifacts arising due to noisy and sparse inputs. To address this issue, we frame surface mapping as a physics-informed energy optimization problem, enforcing surface smoothness by optimizing an energy functional that penalizes sharp surface ridges. Specifically, we propose a deep learning based approach that learns the signed distance field (SDF) of the surface manifold from raw LiDAR point clouds using a physics-informed loss function that optimizes the $L_2$-Hessian energy of the surface. Our learning framework includes a hierarchical octree based input feature encoding and a multi-scale neural network to iteratively refine the signed distance field at different scales of resolution. Lastly, we introduce a test-time refinement strategy to correct topological inconsistencies and edge distortions that can arise in the generated mesh. We propose a \texttt{CUDA}-accelerated least-squares optimization that locally adjusts vertex positions to enforce feature-preserving smoothing. We evaluate our approach on large-scale outdoor datasets and demonstrate that our approach outperforms current state-of-the-art methods in terms of improved accuracy and smoothness. Our code is available at \href{https://github.com/HrishikeshVish/HessianForge/}{https://github.com/HrishikeshVish/HessianForge/}
Reduced-Order Neural Operators: Learning Lagrangian Dynamics on Highly Sparse Graphs
Jul 04, 2024We present a neural operator architecture to simulate Lagrangian dynamics, such as fluid flow, granular flows, and elastoplasticity. Traditional numerical methods, such as the finite element method (FEM), suffer from long run times and large memory consumption. On the other hand, approaches based on graph neural networks are faster but still suffer from long computation times on dense graphs, which are often required for high-fidelity simulations. Our model, GIOROM or Graph Interaction Operator for Reduced-Order Modeling, learns temporal dynamics within a reduced-order setting, capturing spatial features from a highly sparse graph representation of the input and generalizing to arbitrary spatial locations during inference. The model is geometry-aware and discretization-agnostic and can generalize to different initial conditions, velocities, and geometries after training. We show that point clouds of the order of 100,000 points can be inferred from sparse graphs with $\sim$1000 points, with negligible change in computation time. We empirically evaluate our model on elastic solids, Newtonian fluids, Non-Newtonian fluids, Drucker-Prager granular flows, and von Mises elastoplasticity. On these benchmarks, our approach results in a 25$\times$ speedup compared to other neural network-based physics simulators while delivering high-fidelity predictions of complex physical systems and showing better performance on most benchmarks. The code and the demos are provided at https://github.com/HrishikeshVish/GIOROM.
Trajectory Prediction for Robot Navigation using Flow-Guided Markov Neural Operator
Sep 19, 2023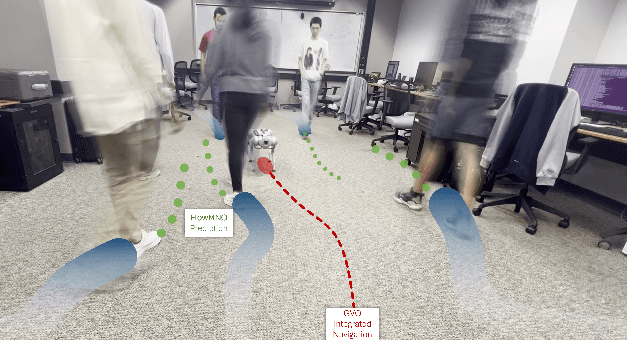



Predicting pedestrian movements remains a complex and persistent challenge in robot navigation research. We must evaluate several factors to achieve accurate predictions, such as pedestrian interactions, the environment, crowd density, and social and cultural norms. Accurate prediction of pedestrian paths is vital for ensuring safe human-robot interaction, especially in robot navigation. Furthermore, this research has potential applications in autonomous vehicles, pedestrian tracking, and human-robot collaboration. Therefore, in this paper, we introduce FlowMNO, an Optical Flow-Integrated Markov Neural Operator designed to capture pedestrian behavior across diverse scenarios. Our paper models trajectory prediction as a Markovian process, where future pedestrian coordinates depend solely on the current state. This problem formulation eliminates the need to store previous states. We conducted experiments using standard benchmark datasets like ETH, HOTEL, ZARA1, ZARA2, UCY, and RGB-D pedestrian datasets. Our study demonstrates that FlowMNO outperforms some of the state-of-the-art deep learning methods like LSTM, GAN, and CNN-based approaches, by approximately 86.46% when predicting pedestrian trajectories. Thus, we show that FlowMNO can seamlessly integrate into robot navigation systems, enhancing their ability to navigate crowded areas smoothly.
ARTEMIS: AI-driven Robotic Triage Labeling and Emergency Medical Information System
Sep 16, 2023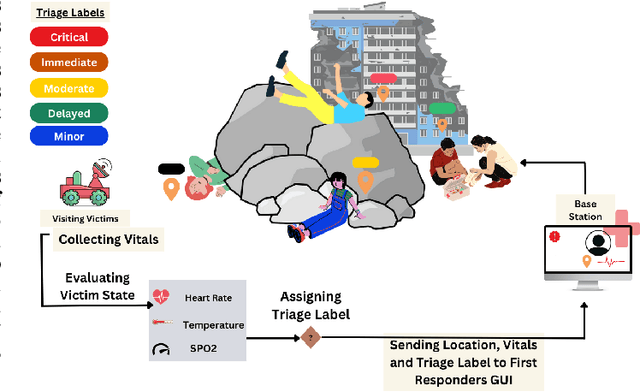
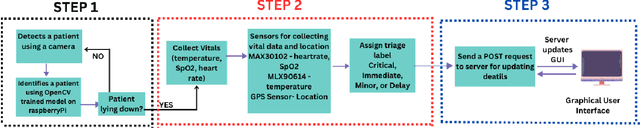
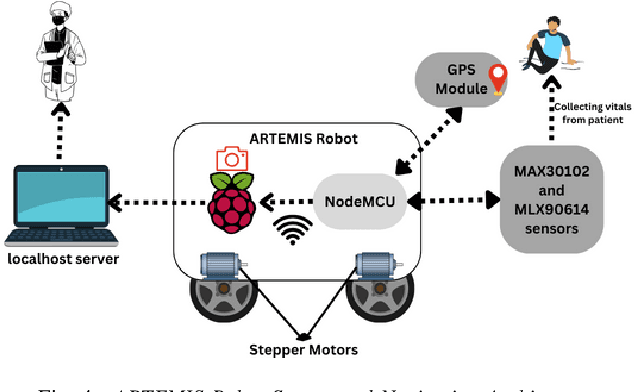
Mass casualty incidents (MCIs) pose a formidable challenge to emergency medical services by overwhelming available resources and personnel. Effective victim assessment is paramount to minimizing casualties during such a crisis. In this paper, we introduce ARTEMIS, an AI-driven Robotic Triage Labeling and Emergency Medical Information System. This system comprises a deep learning model for acuity labeling that is integrated with a robot, that performs the preliminary assessment of injury severity in patients and assigns appropriate triage labels. Additionally, we have developed a frontend (graphical user interface) that is updated by the robots in real time and is accessible to the first responders. To validate the reliability of our proposed algorithmic triage protocol, we employed an off-the-shelf robot kit equipped with sensors for vital sign acquisition. A controlled laboratory simulation of an MCI was conducted to assess the system's performance and effectiveness in real-world scenarios resulting in a triage-level classification accuracy of 92%. This noteworthy achievement underscores the model's proficiency in discerning crucial patterns for accurate triage classification, showcasing its promising potential in healthcare applications.
Graph-based Decentralized Task Allocation for Multi-Robot Target Localization
Sep 16, 2023We introduce a new approach to address the task allocation problem in a system of heterogeneous robots comprising of Unmanned Ground Vehicles (UGVs) and Unmanned Aerial Vehicles (UAVs). The proposed model, \texttt{\method}, or \textbf{G}raph \textbf{A}ttention \textbf{T}ask \textbf{A}llocato\textbf{R} aggregates information from neighbors in the multi-robot system, with the aim of achieving joint optimality in the target localization efficiency.Being decentralized, our method is highly robust and adaptable to situations where collaborators may change over time, ensuring the continuity of the mission. We also proposed heterogeneity-aware preprocessing to let all the different types of robots collaborate with a uniform model.The experimental results demonstrate the effectiveness and scalability of the proposed approach in a range of simulated scenarios. The model can allocate targets' positions close to the expert algorithm's result, with a median spatial gap less than a unit length. This approach can be used in multi-robot systems deployed in search and rescue missions, environmental monitoring, and disaster response.
AffectEcho: Speaker Independent and Language-Agnostic Emotion and Affect Transfer for Speech Synthesis
Aug 16, 2023



Affect is an emotional characteristic encompassing valence, arousal, and intensity, and is a crucial attribute for enabling authentic conversations. While existing text-to-speech (TTS) and speech-to-speech systems rely on strength embedding vectors and global style tokens to capture emotions, these models represent emotions as a component of style or represent them in discrete categories. We propose AffectEcho, an emotion translation model, that uses a Vector Quantized codebook to model emotions within a quantized space featuring five levels of affect intensity to capture complex nuances and subtle differences in the same emotion. The quantized emotional embeddings are implicitly derived from spoken speech samples, eliminating the need for one-hot vectors or explicit strength embeddings. Experimental results demonstrate the effectiveness of our approach in controlling the emotions of generated speech while preserving identity, style, and emotional cadence unique to each speaker. We showcase the language-independent emotion modeling capability of the quantized emotional embeddings learned from a bilingual (English and Chinese) speech corpus with an emotion transfer task from a reference speech to a target speech. We achieve state-of-art results on both qualitative and quantitative metrics.
FairPy: A Toolkit for Evaluation of Social Biases and their Mitigation in Large Language Models
Feb 10, 2023Studies have shown that large pretrained language models exhibit biases against social groups based on race, gender etc, which they inherit from the datasets they are trained on. Various researchers have proposed mathematical tools for quantifying and identifying these biases. There have been methods proposed to mitigate such biases. In this paper, we present a comprehensive quantitative evaluation of different kinds of biases such as race, gender, ethnicity, age etc. exhibited by popular pretrained language models such as BERT, GPT-2 etc. and also present a toolkit that provides plug-and-play interfaces to connect mathematical tools to identify biases with large pretrained language models such as BERT, GPT-2 etc. and also present users with the opportunity to test custom models against these metrics. The toolkit also allows users to debias existing and custom models using the debiasing techniques proposed so far. The toolkit is available at https://github.com/HrishikeshVish/Fairpy.
Fast Resolution Agnostic Neural Techniques to Solve Partial Differential Equations
Jan 30, 2023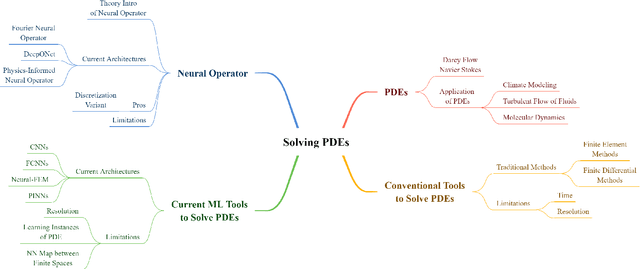



Numerical approximations of partial differential equations (PDEs) are routinely employed to formulate the solution of physics, engineering and mathematical problems involving functions of several variables, such as the propagation of heat or sound, fluid flow, elasticity, electrostatics, electrodynamics, and more. While this has led to solving many complex phenomena, there are still significant limitations. Conventional approaches such as Finite Element Methods (FEMs) and Finite Differential Methods (FDMs) require considerable time and are computationally expensive. In contrast, machine learning-based methods such as neural networks are faster once trained, but tend to be restricted to a specific discretization. This article aims to provide a comprehensive summary of conventional methods and recent machine learning-based methods to approximate PDEs numerically. Furthermore, we highlight several key architectures centered around the neural operator, a novel and fast approach (1000x) to learning the solution operator of a PDE. We will note how these new computational approaches can bring immense advantages in tackling many problems in fundamental and applied physics.
PaCMO: Partner Dependent Human Motion Generation in Dyadic Human Activity using Neural Operators
Nov 25, 2022



We address the problem of generating 3D human motions in dyadic activities. In contrast to the concurrent works, which mainly focus on generating the motion of a single actor from the textual description, we generate the motion of one of the actors from the motion of the other participating actor in the action. This is a particularly challenging, under-explored problem, that requires learning intricate relationships between the motion of two actors participating in an action and also identifying the action from the motion of one actor. To address these, we propose partner conditioned motion operator (PaCMO), a neural operator-based generative model which learns the distribution of human motion conditioned by the partner's motion in function spaces through adversarial training. Our model can handle long unlabeled action sequences at arbitrary time resolution. We also introduce the "Functional Frechet Inception Distance" ($F^2ID$) metric for capturing similarity between real and generated data for function spaces. We test PaCMO on NTU RGB+D and DuetDance datasets and our model produces realistic results evidenced by the $F^2ID$ score and the conducted user study.
NIO: Lightweight neural operator-based architecture for video frame interpolation
Nov 19, 2022We present, NIO - Neural Interpolation Operator, a lightweight efficient neural operator-based architecture to perform video frame interpolation. Current deep learning based methods rely on local convolutions for feature learning and require a large amount of training on comprehensive datasets. Furthermore, transformer-based architectures are large and need dedicated GPUs for training. On the other hand, NIO, our neural operator-based approach learns the features in the frames by translating the image matrix into the Fourier space by using Fast Fourier Transform (FFT). The model performs global convolution, making it discretization invariant. We show that NIO can produce visually-smooth and accurate results and converges in fewer epochs than state-of-the-art approaches. To evaluate the visual quality of our interpolated frames, we calculate the structural similarity index (SSIM) and Peak Signal to Noise Ratio (PSNR) between the generated frame and the ground truth frame. We provide the quantitative performance of our model on Vimeo-90K dataset, DAVIS, UCF101 and DISFA+ dataset.