 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRACLE: Inverse Reinforcement and Curriculum Learning Model for Human-inspired Mobile Robot Navigation
Dec 07, 2023
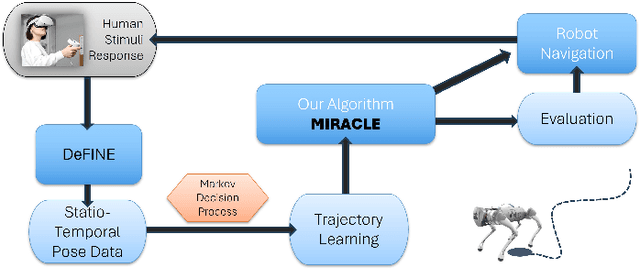

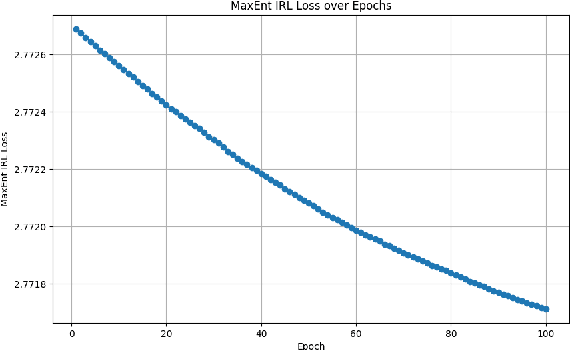
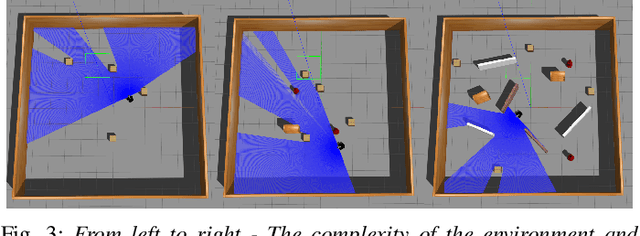
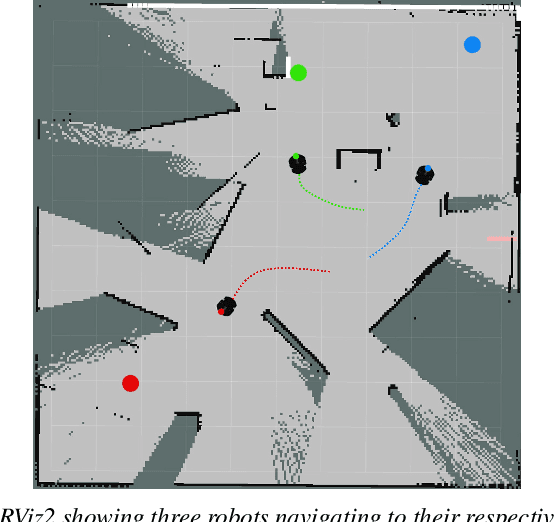
In emergency scenarios, mobile robots must navigate like humans, interpreting stimuli to locate potential victims rapidly without interfering with first responders. Existing socially-aware navigation algorithms face computational and adaptability challenges. To overcome these, we propose a solution, MIRACLE -- an inverse reinforcement and curriculum learning model, that employs gamified learning to gather stimuli-driven human navigational data. This data is then used to train a Deep Inverse Maximum Entropy Reinforcement Learning model, reducing reliance on demonstrator abilities. Testing reveals a low loss of 2.7717 within a 400-sized environment, signifying human-like response replication. Current databases lack comprehensive stimuli-driven data, necessitating our approach. By doing so, we enable robots to navigate emergency situations with human-like perception, enhancing their life-saving capabilities.
DREAM: Decentralized Reinforcement Learning for Exploration and Efficient Energy Management in Multi-Robot Systems
Sep 29, 2023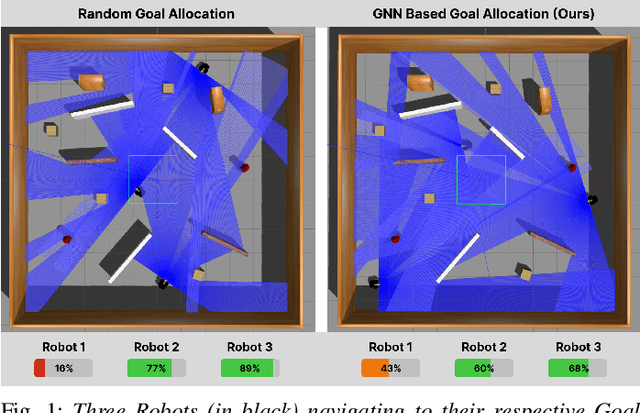
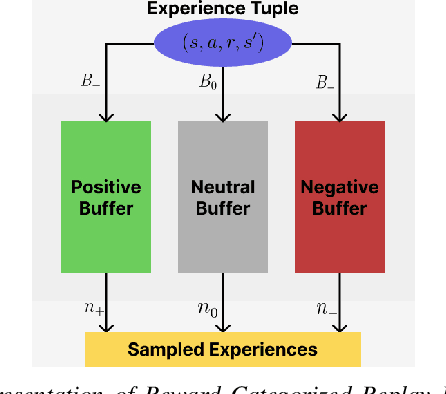
Resource-constrained robots often suffer from energy inefficiencies, underutilized computational abilities due to inadequate task allocation, and a lack of robustness in dynamic environments, all of which strongly affect their performance. This paper introduces DREAM - Decentralized Reinforcement Learning for Exploration and Efficient Energy Management in Multi-Robot Systems, a comprehensive framework that optimizes the allocation of resources for efficient exploration. It advances beyond conventional heuristic-based task planning as observed conventionally. The framework incorporates Operational Range Estimation using Reinforcement Learning to perform exploration and obstacle avoidance in unfamiliar terrains. DREAM further introduces an Energy Consumption Model for goal allocation, thereby ensuring mission completion under constrained resources using a Graph Neural Network. This approach also ensures that the entire Multi-Robot System can survive for an extended period of time for further missions compared to the conventional approach of randomly allocating goals, which compromises one or more agents. Our approach adapts to prioritizing agents in real-time, showcasing remarkable resilience against dynamic environments. This robust solution was evaluated in various simulated environments, demonstrating adaptability and applicability across diverse scenarios. We observed a substantial improvement of about 25% over the baseline method, leading the way for future research in resource-constrained robotics.
HEROES: Unreal Engine-based Human and Emergency Robot Operation Education System
Sep 25, 2023



Training and preparing first responders and humanitarian robots for Mass Casualty Incidents (MCIs) often poses a challenge owing to the lack of realistic and easily accessible test facilities. While such facilities can offer realistic scenarios post an MCI that can serve training and educational purposes for first responders and humanitarian robots, they are often hard to access owing to logistical constraints. To overcome this challenge, we present HEROES- a versatile Unreal Engine simulator for designing novel training simulations for humans and emergency robots for such urban search and rescue operations. The proposed HEROES simulator is capable of generating synthetic datasets for machine learning pipelines that are used for training robot navigation. This work addresses the necessity for a comprehensive training platform in the robotics community, ensuring pragmatic and efficient preparation for real-world emergency scenarios. The strengths of our simulator lie in its adaptability, scalability, and ability to facilitate collaboration between robot developers and first responders, fostering synergy in developing effective strategies for search and rescue operations in MCIs. We conducted a preliminary user study with an 81% positive response supporting the ability of HEROES to generate sufficiently varied environments, and a 78% positive response affirming the usefulness of the simulation environment of HEROES.
ARTEMIS: AI-driven Robotic Triage Labeling and Emergency Medical Information System
Sep 16, 2023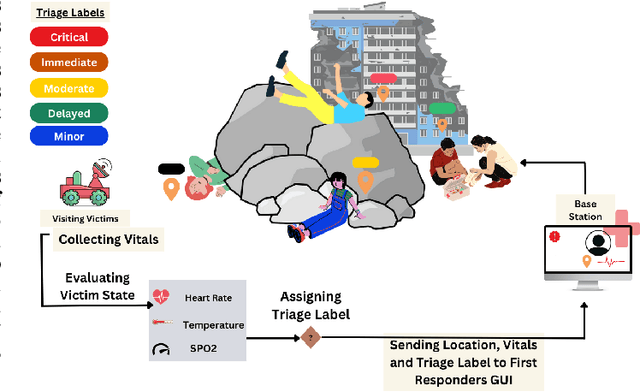
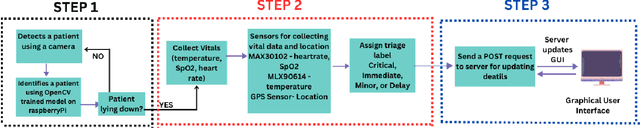
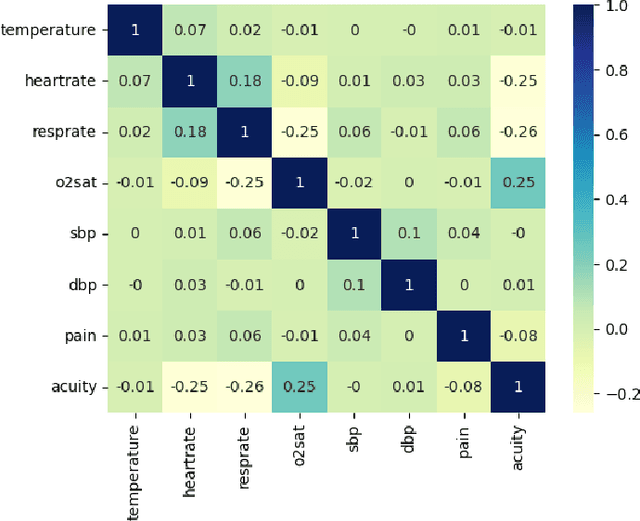
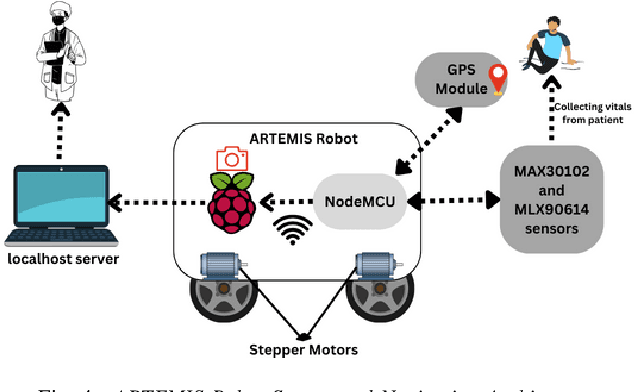
Mass casualty incidents (MCIs) pose a formidable challenge to emergency medical services by overwhelming available resources and personnel. Effective victim assessment is paramount to minimizing casualties during such a crisis. In this paper, we introduce ARTEMIS, an AI-driven Robotic Triage Labeling and Emergency Medical Information System. This system comprises a deep learning model for acuity labeling that is integrated with a robot, that performs the preliminary assessment of injury severity in patients and assigns appropriate triage labels. Additionally, we have developed a frontend (graphical user interface) that is updated by the robots in real time and is accessible to the first responders. To validate the reliability of our proposed algorithmic triage protocol, we employed an off-the-shelf robot kit equipped with sensors for vital sign acquisition. A controlled laboratory simulation of an MCI was conducted to assess the system's performance and effectiveness in real-world scenarios resulting in a triage-level classification accuracy of 92%. This noteworthy achievement underscores the model's proficiency in discerning crucial patterns for accurate triage classification, showcasing its promising potential in healthcare applications.
Graph-based Decentralized Task Allocation for Multi-Robot Target Localization
Sep 16, 2023We introduce a new approach to address the task allocation problem in a system of heterogeneous robots comprising of Unmanned Ground Vehicles (UGVs) and Unmanned Aerial Vehicles (UAVs). The proposed model, \texttt{\method}, or \textbf{G}raph \textbf{A}ttention \textbf{T}ask \textbf{A}llocato\textbf{R} aggregates information from neighbors in the multi-robot system, with the aim of achieving joint optimality in the target localization efficiency.Being decentralized, our method is highly robust and adaptable to situations where collaborators may change over time, ensuring the continuity of the mission. We also proposed heterogeneity-aware preprocessing to let all the different types of robots collaborate with a uniform model.The experimental results demonstrate the effectiveness and scalability of the proposed approach in a range of simulated scenarios. The model can allocate targets' positions close to the expert algorithm's result, with a median spatial gap less than a unit length. This approach can be used in multi-robot systems deployed in search and rescue missions, environmental monitoring, and disaster response.
Visibility-Inspired Models of Touch Sensors for Navigation
Mar 04, 2022

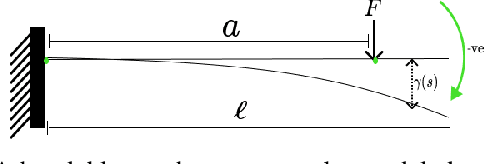

This paper introduces mathematical models of touch sensors for mobile robotics based on visibility. Serving a purpose similar to the pinhole camera model for computer vision, the introduced models are expected to provide a useful, idealized characterization of task-relevant information that can be inferred from their outputs or observations. This allows direct comparisons to be made between traditional depth sensors, highlighting cases in which touch sensing may be interchangeable with time of flight or vision sensors, and characterizing unique advantages provided by touch sensing. The models include contact detection, compression, load bearing, and deflection. The results could serve as a basic building block for innovative touch sensor designs for mobile robot sensor fusion systems.
Unsupervised Learning of slow features for Data Efficient Regression
Dec 11, 2020
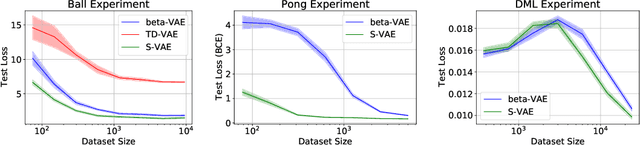
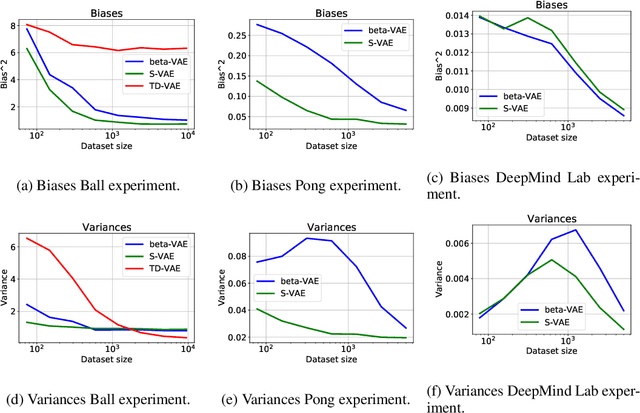
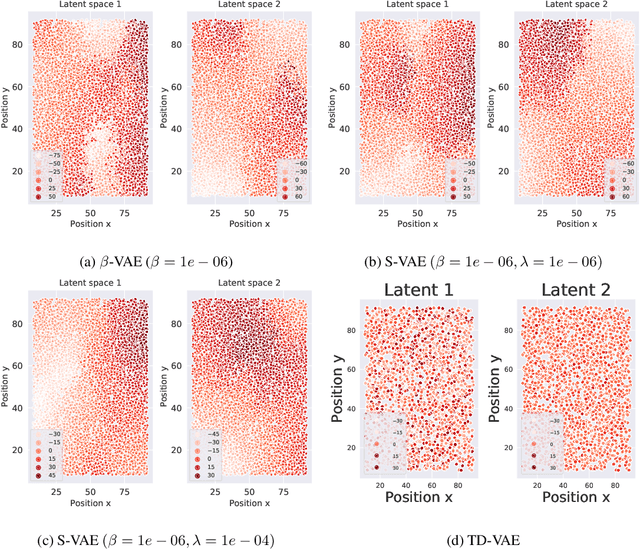
Research in computational neuroscience suggests that the human brain's unparalleled data efficiency is a result of highly efficient mechanisms to extract and organize slowly changing high level features from continuous sensory inputs. In this paper, we apply this slowness principle to a state of the art representation learning method with the goal of performing data efficient learning of down-stream regression tasks. To this end, we propose the slow variational autoencoder (S-VAE), an extension to the $\beta$-VAE which applies a temporal similarity constraint to the latent representations. We empirically compare our method to the $\beta$-VAE and the Temporal Difference VAE (TD-VAE), a state-of-the-art method for next frame prediction in latent space with temporal abstraction. We evaluate the three methods against their data-efficiency on down-stream tasks using a synthetic 2D ball tracking dataset, a dataset from a reinforcent learning environment and a dataset generated using the DeepMind Lab environment. In all tasks, the proposed method outperformed the baselines both with dense and especially sparse labeled data. The S-VAE achieved similar or better performance compared to the baselines with $20\%$ to $93\%$ less data.
DeFINE: Delayed Feedback based Immersive Navigation Environment for Studying Goal-Directed Human Navigation
Mar 06, 2020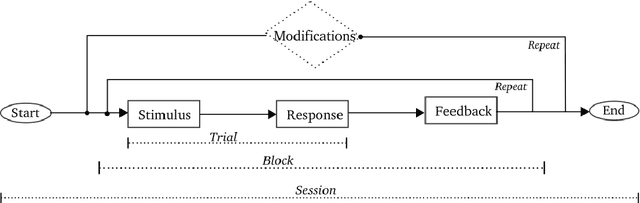
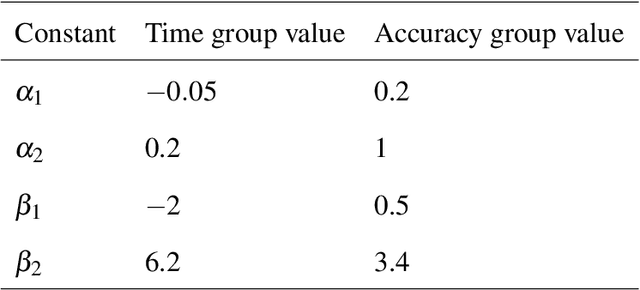
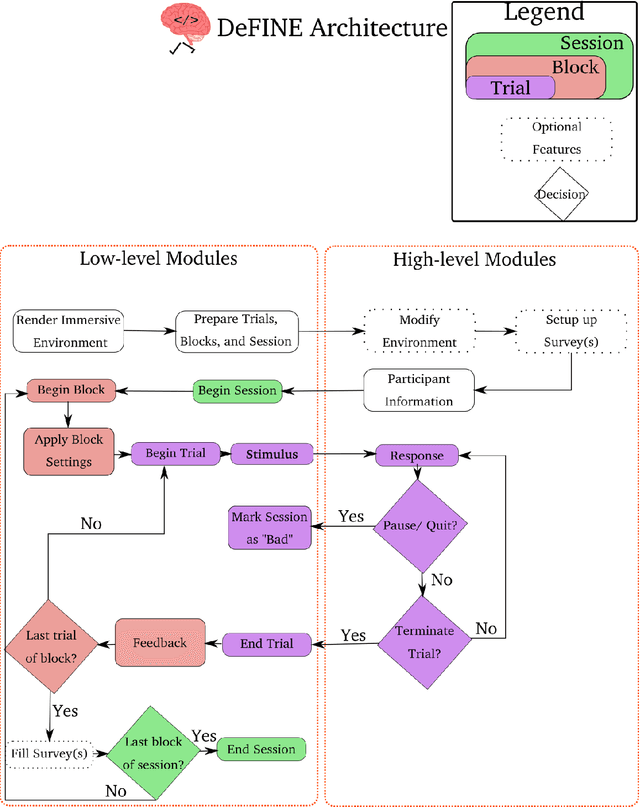
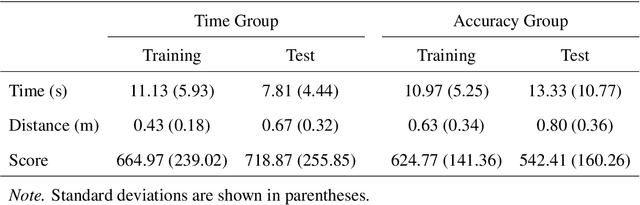
With the advent of consumer-grade products for presenting an immersive virtual environment (VE), there is a growing interest in utilizing VEs for testing human navigation behavior. However, preparing a VE still requires a high level of technical expertise in computer graphics and virtual reality, posing a significant hurdle to embracing the emerging technology. To address this issue, this paper presents Delayed Feedback based Immersive Navigation Environment (DeFINE), a framework that allows for easy creation and administration of navigation tasks within customizable VEs via intuitive graphical user interfaces and simple settings files. Importantly, DeFINE has a built-in capability to provide performance feedback to participants during an experiment, a feature that is critically missing in other similar frameworks. To demonstrate the usability of DeFINE from both experimentalists' and participants' perspectives, a case study was conducted in which participants navigated to a hidden goal location with feedback that differentially weighted speed and accuracy of their responses. In addition, the participants evaluated DeFINE in terms of its ease of use, required workload, and proneness to induce cybersickness. Results showed that the participants' navigation performance was affected differently by the types of feedback they received, and they rated DeFINE highly in the evaluations, validating DeFINE's architecture for investigating human navigation in VEs. With its rich out-of-the-box functionality and great customizability due to open-source licensing, DeFINE makes VEs significantly more accessible to many researchers.
MuPNet: Multi-modal Predictive Coding Network for Place Recognition by Unsupervised Learning of Joint Visuo-Tactile Latent Representations
Sep 16, 2019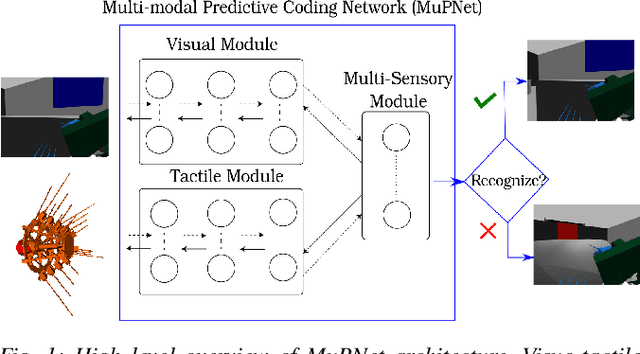

Extracting and binding salient information from different sensory modalities to determine common features in the environment is a significant challenge in robotics. Here we present MuPNet (Multi-modal Predictive Coding Network), a biologically plausible network architecture for extracting joint latent features from visuo-tactile sensory data gathered from a biomimetic mobile robot. In this study we evaluate MuPNet applied to place recognition as a simulated biomimetic robot platform explores visually aliased environments. The F1 scores demonstrate that its performance over prior hand-crafted sensory feature extraction techniques is equivalent under controlled conditions, with significant improvement when operating in novel environments.
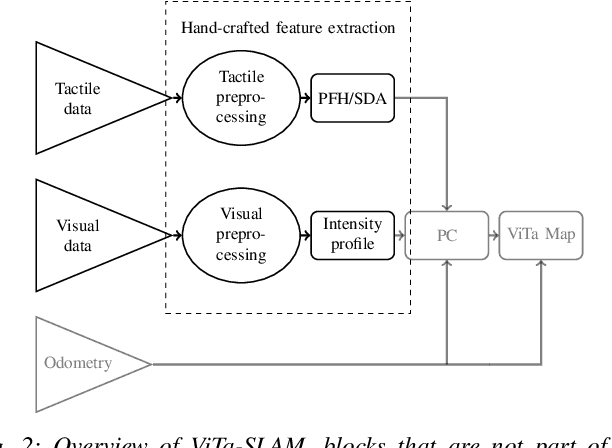
ViTa-SLAM: A Bio-inspired Visuo-Tactile SLAM for Navigation while Interacting with Aliased Environments
Jun 26, 2019
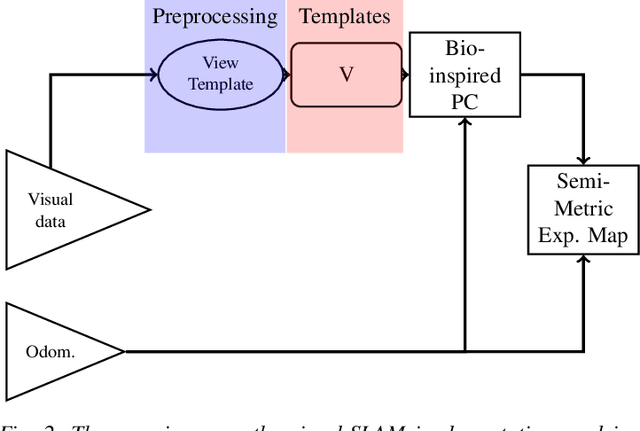

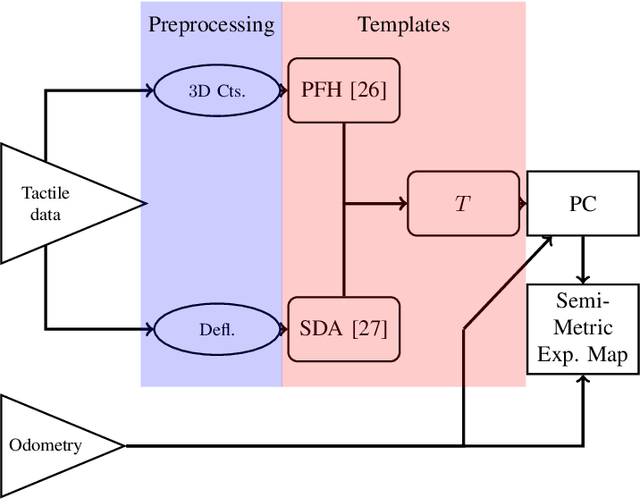
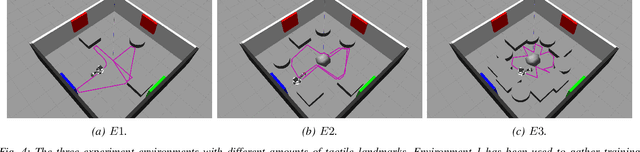
RatSLAM is a rat hippocampus-inspired visual Simultaneous Localization and Mapping (SLAM) framework capable of generating semi-metric topological representations of indoor and outdoor environments. Whisker-RatSLAM is a 6D extension of the RatSLAM and primarily focuses on object recognition by generating point clouds of objects based on whisking information. This paper introduces a novel extension to both former works that is referred to as ViTa-SLAM that harnesses both vision and tactile information for performing SLAM. This not only allows the robot to perform natural interaction with the environment whilst navigating, as is normally seen in nature, but also provides a mechanism to fuse non-unique tactile and unique visual data. Compared to the former works, our approach can handle ambiguous scenes in which one sensor alone is not capable of identifying false-positive loop-closures.