 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Convergence in Balanced Resonate-and-Fire Neurons
Jun 01, 2024



Resonate-and-Fire (RF) neurons are an interesting complementary model for integrator neurons in spiking neural networks (SNNs). Due to their resonating membrane dynamics they can extract frequency patterns within the time domain. While established RF variants suffer from intrinsic shortcomings, the recently proposed balanced resonate-and-fire (BRF) neuron marked a significant methodological advance in terms of task performance, spiking and parameter efficiency, as well as, general stability and robustness, demonstrated for recurrent SNNs in various sequence learning tasks. One of the most intriguing result, however, was an immense improvement in training convergence speed and smoothness, overcoming the typical convergence dilemma in backprop-based SNN training. This paper aims at providing further intuitions about how and why these convergence advantages emerge. We show that BRF neurons, in contrast to well-established ALIF neurons, span a very clean and smooth - almost convex - error landscape. Furthermore, empirical results reveal that the convergence benefits are predominantly coupled with a divergence boundary-aware optimization, a major component of the BRF formulation that addresses the numerical stability of the time-discrete resonator approximation. These results are supported by a formal investigation of the membrane dynamics indicating that the gradient is transferred back through time without loss of magnitude.
Accurate online training of dynamical spiking neural networks through Forward Propagation Through Time
Dec 20, 2021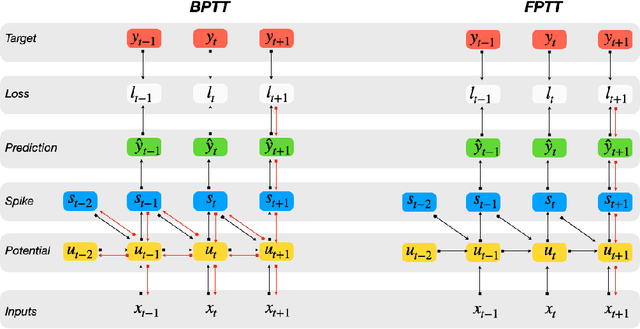
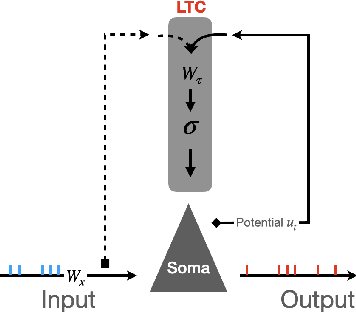
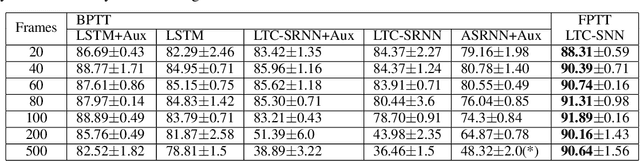
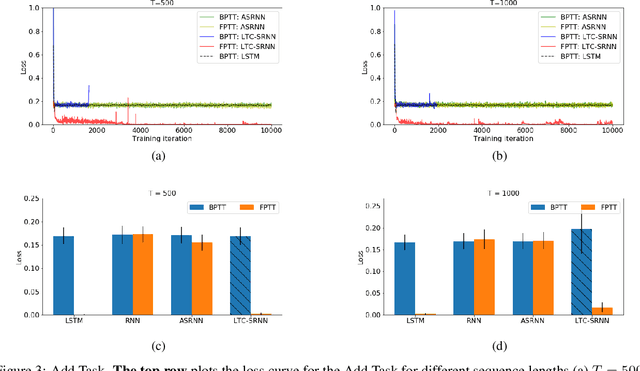
The event-driven and sparse nature of communication between spiking neurons in the brain holds great promise for flexible and energy-efficient AI. Recent advances in learning algorithms have demonstrated that recurrent networks of spiking neurons can be effectively trained to achieve competitive performance compared to standard recurrent neural networks. Still, as these learning algorithms use error-backpropagation through time (BPTT), they suffer from high memory requirements, are slow to train, and are incompatible with online learning. This limits the application of these learning algorithms to relatively small networks and to limited temporal sequence lengths. Online approximations to BPTT with lower computational and memory complexity have been proposed (e-prop, OSTL), but in practice also suffer from memory limitations and, as approximations, do not outperform standard BPTT training. Here, we show how a recently developed alternative to BPTT, Forward Propagation Through Time (FPTT) can be applied in spiking neural networks. Different from BPTT, FPTT attempts to minimize an ongoing dynamically regularized risk on the loss. As a result, FPTT can be computed in an online fashion and has fixed complexity with respect to the sequence length. When combined with a novel dynamic spiking neuron model, the Liquid-Time-Constant neuron, we show that SNNs trained with FPTT outperform online BPTT approximations, and approach or exceed offline BPTT accuracy on temporal classification tasks. This approach thus makes it feasible to train SNNs in a memory-friendly online fashion on long sequences and scale up SNNs to novel and complex neural architectures.
Accurate and efficient time-domain classification with adaptive spiking recurrent neural networks
Mar 12, 2021Inspired by more detailed modeling of biological neurons, Spiking neural networks (SNNs) have been investigated both as more biologically plausible and potentially more powerful models of neural computation, and also with the aim of extracting biological neurons' energy efficiency; the performance of such networks however has remained lacking compared to classical artificial neural networks (ANNs). Here, we demonstrate how a novel surrogate gradient combined with recurrent networks of tunable and adaptive spiking neurons yields state-of-the-art for SNNs on challenging benchmarks in the time-domain, like speech and gesture recognition. This also exceeds the performance of standard classical recurrent neural networks (RNNs) and approaches that of the best modern ANNs. As these SNNs exhibit sparse spiking, we show that they theoretically are one to three orders of magnitude more computationally efficient compared to RNNs with comparable performance. Together, this positions SNNs as an attractive solution for AI hardware implementations.
MuPNet: Multi-modal Predictive Coding Network for Place Recognition by Unsupervised Learning of Joint Visuo-Tactile Latent Representations
Sep 16, 2019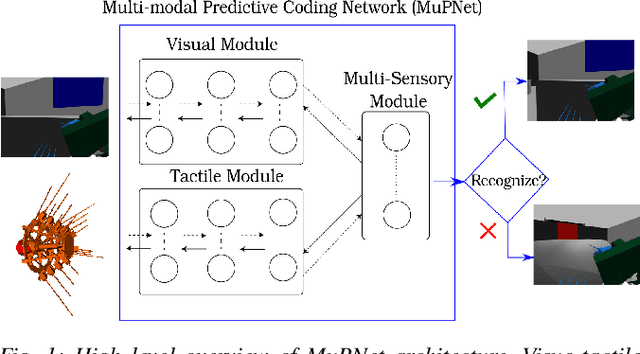
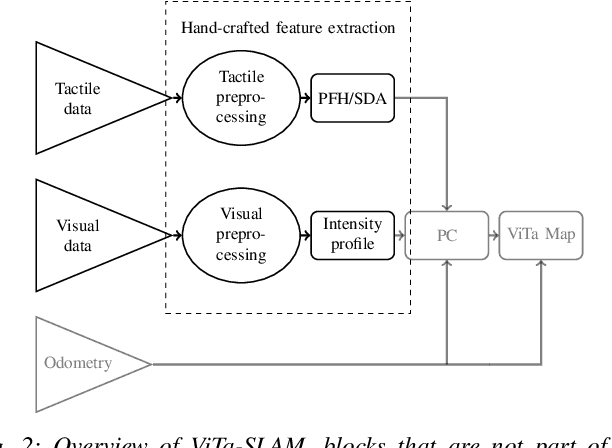

Extracting and binding salient information from different sensory modalities to determine common features in the environment is a significant challenge in robotics. Here we present MuPNet (Multi-modal Predictive Coding Network), a biologically plausible network architecture for extracting joint latent features from visuo-tactile sensory data gathered from a biomimetic mobile robot. In this study we evaluate MuPNet applied to place recognition as a simulated biomimetic robot platform explores visually aliased environments. The F1 scores demonstrate that its performance over prior hand-crafted sensory feature extraction techniques is equivalent under controlled conditions, with significant improvement when operating in novel environments.
LocalNorm: Robust Image Classification through Dynamically Regularized Normalization
Mar 04, 2019

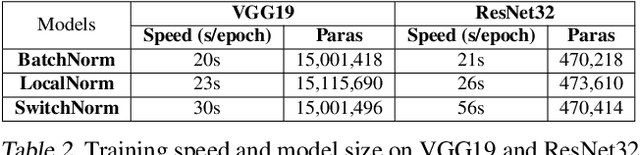
While modern convolutional neural networks achieve outstanding accuracy on many image classification tasks, they are, compared to humans, much more sensitive to image degradation. Here, we describe a variant of Batch Normalization, LocalNorm, that regularizes the normalization layer in the spirit of Dropout while dynamically adapting to the local image intensity and contrast at test-time. We show that the resulting deep neural networks are much more resistant to noise-induced image degradation, improving accuracy by up to three times, while achieving the same or slightly better accuracy on non-degraded classical benchmarks. In computational terms, LocalNorm adds negligible training cost and little or no cost at inference time, and can be applied to already-trained networks in a straightforward manner.
Generalisation in fully-connected neural networks for time series forecasting
Feb 14, 2019

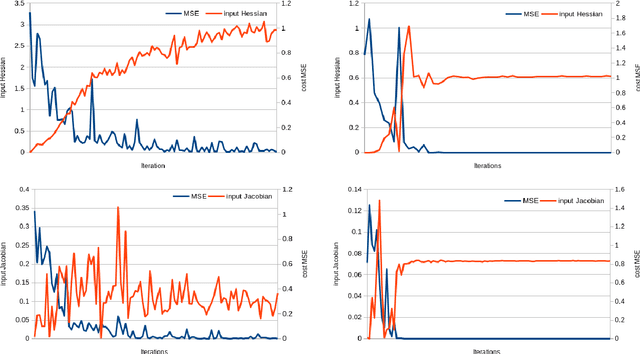

In this paper we study the generalisation capabilities of fully-connected neural networks trained in the context of time series forecasting. Time series do not satisfy the typical assumption in statistical learning theory of the data being i.i.d. samples from some data-generating distribution. We use the input and weight Hessians, that is the smoothness of the learned function with respect to the input and the width of the minimum in weight space, to quantify a network's ability to generalise to unseen data. While such generalisation metrics have been studied extensively in the i.i.d. setting of for example image recognition, here we empirically validate their use in the task of time series forecasting. Furthermore we discuss how one can control the generalisation capability of the network by means of the training process using the learning rate, batch size and the number of training iterations as controls. Using these hyperparameters one can efficiently control the complexity of the output function without imposing explicit constraints.
Pricing options and computing implied volatilities using neural networks
Jan 25, 2019



This paper proposes a data-driven approach, by means of an Artificial Neural Network (ANN), to value financial options and to calculate implied volatilities with the aim of accelerating the corresponding numerical methods. With ANNs being universal function approximators, this method trains an optimized ANN on a data set generated by a sophisticated financial model, and runs the trained ANN as an agent of the original solver in a fast and efficient way. We test this approach on three different types of solvers, including the analytic solution for the Black-Scholes equation, the COS method for the Heston stochastic volatility model and Brent's iterative root-finding method for the calculation of implied volatilities. The numerical results show that the ANN solver can reduce the computing time significantly.
Fast and Efficient Asynchronous Neural Computation with Adapting Spiking Neural Networks
Sep 07, 2016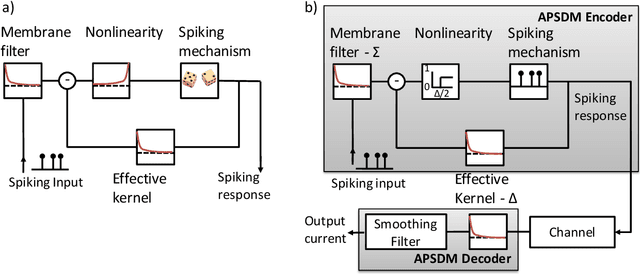
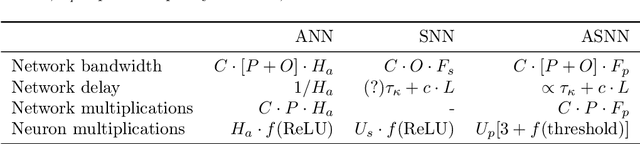
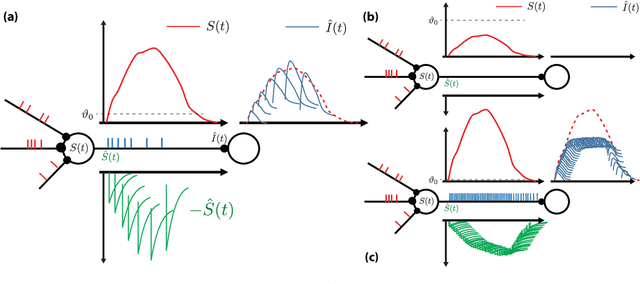
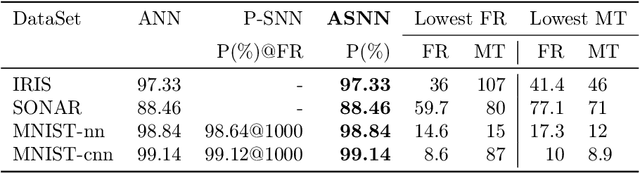
Biological neurons communicate with a sparing exchange of pulses - spikes. It is an open question how real spiking neurons produce the kind of powerful neural computation that is possible with deep artificial neural networks, using only so very few spikes to communicate. Building on recent insights in neuroscience, we present an Adapting Spiking Neural Network (ASNN) based on adaptive spiking neurons. These spiking neurons efficiently encode information in spike-trains using a form of Asynchronous Pulsed Sigma-Delta coding while homeostatically optimizing their firing rate. In the proposed paradigm of spiking neuron computation, neural adaptation is tightly coupled to synaptic plasticity, to ensure that downstream neurons can correctly decode upstream spiking neurons. We show that this type of network is inherently able to carry out asynchronous and event-driven neural computation, while performing identical to corresponding artificial neural networks (ANNs). In particular, we show that these adaptive spiking neurons can be drop in replacements for ReLU neurons in standard feedforward ANNs comprised of such units. We demonstrate that this can also be successfully applied to a ReLU based deep convolutional neural network for classifying the MNIST dataset. The ASNN thus outperforms current Spiking Neural Networks (SNNs) implementations, while responding (up to) an order of magnitude faster and using an order of magnitude fewer spikes. Additionally, in a streaming setting where frames are continuously classified, we show that the ASNN requires substantially fewer network updates as compared to the corresponding ANN.
Fractionally Predictive Spiking Neurons
Oct 29, 2010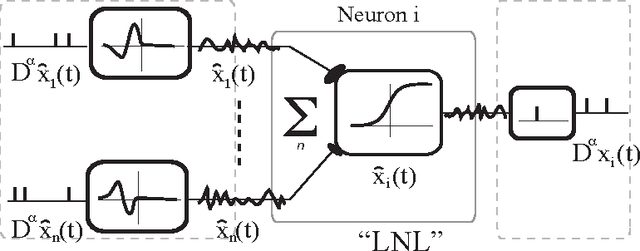
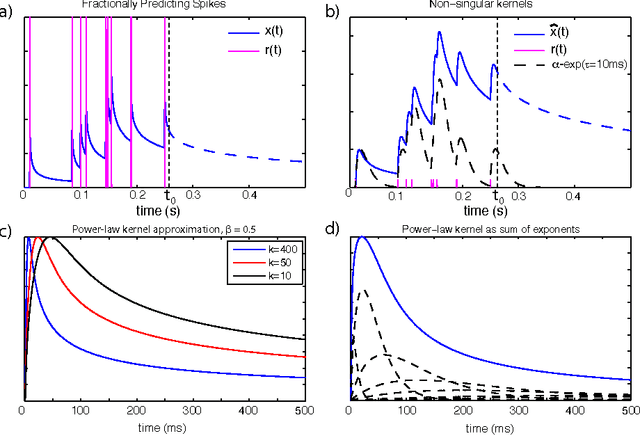
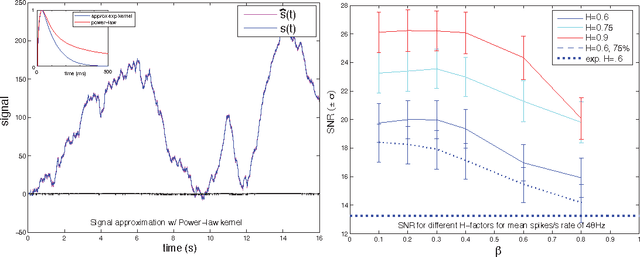
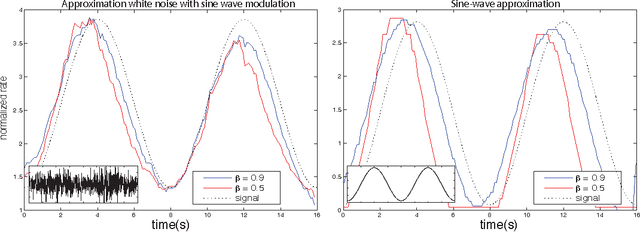
Recent experimental work has suggested that the neural firing rate can be interpreted as a fractional derivative, at least when signal variation induces neural adaptation. Here, we show that the actual neural spike-train itself can be considered as the fractional derivative, provided that the neural signal is approximated by a sum of power-law kernels. A simple standard thresholding spiking neuron suffices to carry out such an approximation, given a suitable refractory response. Empirically, we find that the online approximation of signals with a sum of power-law kernels is beneficial for encoding signals with slowly varying components, like long-memory self-similar signals. For such signals, the online power-law kernel approximation typically required less than half the number of spikes for similar SNR as compared to sums of similar but exponentially decaying kernels. As power-law kernels can be accurately approximated using sums or cascades of weighted exponentials, we demonstrate that the corresponding decoding of spike-trains by a receiving neuron allows for natural and transparent temporal signal filtering by tuning the weights of the decoding kernel.